Разработка сетевой библиотеки на C++20: интеграция асинхронности и алгоритма Raft
Posted on Пн 27 января 2025 in misc
Часть 1
Введение
С годами работы в области распределённых систем, я понял, что мой опыт не будет полным без реализации алгоритма Raft. Это осознание побудило меня к действию: я решил создать свою реализацию, используя асинхронные возможности C++20.
Задача стояла не из лёгких: мне требовалось разработать сетевую библиотеку, обходясь без громоздких решений вроде Boost или gRPC, создать эффективную библиотеку сериализации сообщений без использования таких тяжёлых инструментов, как protobuf, и реализовать алгоритм Raft таким образом, чтобы он был независим от сетевой инфраструктуры и поддавался простому тестированию через юнит-тесты.
В этой статье я поделюсь своим опытом создания сетевой библиотеки на основе корутин C++20.
Реализация EchoServer и EchoClient
Первым шагом в создании сетевой библиотеки была реализация простого EchoServer и EchoClient. EchoClient соединяется с EchoServer и отправляет ему сообщения, на которые сервер отвечает тем же текстом. Взаимодействие клиента и сервера можно увидеть на примере:
$ ./echoclient
test
Received: test
message
Received: message
yet another message
Received: yet another message
$ ./echoserver
Received: test
Received: message
Received: yet another message
Код EchoClient
Целью было сделать код клиента максимально простым. Пример реализации:
TSimpleTask client(TLoop* loop)
{
char out[128] = {0};
char in[128] = {0};
ssize_t size = 1;
try {
TSocket input{TAddress{}, 0 /* stdin */, loop->Poller()};
TSocket socket{TAddress{"127.0.0.1", 8888}, loop->Poller()};
co_await socket.Connect();
while (size && (size = co_await input.ReadSome(out, sizeof(out)))) {
co_await socket.WriteSome(out, size);
size = co_await socket.ReadSome(in, sizeof(in));
std::cout << "Received: " << std::string_view(in, size) << "\n";
}
} catch (const std::exception& ex) {
std::cout << "Exception: " << ex.what() << "\n";
}
loop->Stop();
co_return;
}
где TSimpleTask - тривиальная корутина.
Код EchoServer
Аналогично, код сервера был разработан для простоты и эффективности:
TSimpleTask client_handler(TSocket socket, TLoop* loop) {
char buffer[128] = {0}; ssize_t size = 0;
try {
while ((size = co_await socket.ReadSome(buffer, sizeof(buffer))) > 0) {
std::cerr << "Received: " << std::string_view(buffer, size) << "\n";
co_await socket.WriteSome(buffer, size);
}
} catch (const std::exception& ex) {
std::cerr << "Exception: " << ex.what() << "\n";
}
co_return;
}
TSimpleTask server(TLoop* loop)
{
TSocket socket(TAddress{"0.0.0.0", 8888}, loop->Poller());
socket.Bind();
socket.Listen();
while (true) {
auto client = co_await socket.Accept();
client_handler(std::move(client), loop);
}
co_return;
}
Реализация Awaitable в C++20
C++20, хотя и предлагает достаточно низкоуровневый API для реализации корутин, позволяет сократить сложность, предоставляя механизм Awaitable. Awaitable управляет приостановкой и возобновлением корутин, используя coroutine_handle, который ожидает активации на основе механизмов поллинга вроде select или poll.
Awaitable определяет три основных метода: await_ready, который проверяет, готова ли корутина к выполнению, await_suspend, который приостанавливает корутину и связывает её с механизмом поллинга, и await_resume, который возобновляет выполнение корутины после того, как ожидаемое событие произошло. Эта концепция облегчает управление асинхронными операциями, делая код более читаемым и эффективным.
В данном примере метод ReadSome сокета реализован с использованием механизма Awaitable в C++20:
auto ReadSome(char* buf, size_t size) {
struct TAwaitable {
bool await_ready() {
Run();
return ready = (ret >= 0);
}
int await_resume() {
if (!ready) { Run(); }
return ret;
}
void Run() {
ret = read(fd, b, s);
if (ret < 0 && !(err == EINTR||err==EAGAIN||err==EINPROGRESS)) {
throw std::system_error(errno, std::generic_category(), "read");
}
}
void await_suspend(std::coroutine_handle<> h) {
poller->AddRead(fd, h);
}
TSelect* poller;
int fd;
char* b; size_t s;
int ret;
bool ready;
};
return TAwaitable{Poller_,Fd_,buf,size};
}
Структура TAwaitable определяет необходимые функции для управления асинхронным выполнением. Если чтение данных с сокета невозможно, корутина приостанавливается (await_suspend), и событие добавляется в поллер. Как только сокет готов к чтению, вызывается resume на coroutine_handle, что приводит к возобновлению корутины (await_resume) и продолжению её выполнения.
Для реализации более сложных вещей, например, чтобы с помощью ReadSome сделать Read, который читает точное число байт из сокета, нужно уметь вызывать одну корутину из другой корутины и получать результат:
template<typename T, typename TSocket>
struct TStructReader {
TStructReader(TSocket& socket)
: Socket(socket)
{ }
TValueTask<T> Read() {
T res;
size_t size = sizeof(T);
char* p = reinterpret_cast<char*>(&res);
while (size != 0) {
auto readSize = co_await Socket.ReadSome(p, size);
if (readSize == 0) {
throw std::runtime_error("Connection closed");
}
if (readSize < 0) {
continue; // retry
}
p += readSize;
size -= readSize;
}
co_return res;
}
private:
TSocket& Socket;
};
Эта структура будет использоваться так:
auto result = co_await TStructReader<TType>(socket).Read();
Структура TStructReader использует метод ReadSome для асинхронного чтения, обрабатывая ситуации закрытого соединения и необходимость повтора чтения. Чтобы достичь этого, корутина, возвращаемая TStructReader::Read, должна быть одновременно Awaitable. Это обеспечивает возможность приостановки вызывающей корутины и её возобновления после получения результата. Для обеспечения данного поведения в await_suspend мы будем прикапывать корутину, которая нас вызывает, в final_suspend вызываемой корутины мы будем пробуждать вызывающую корутину и получать результат. Полный код подобной корутины (TValueTask<T>) можно найти на GitHub: coroio/corochain.hpp.
Расширенные Возможности Сетевой Библиотеки
С помощью механизма вызова корутин по цепочке, я расширил сетевую библиотеку, реализовав чтение и запись структур данных, построчное чтение, а также поддержку SSL сокетов с использованием цепочек вызовов корутин. Пример echoclient с построчным чтением демонстрирует эффективность и гибкость подхода:
TFileHandle input{0, poller}; // stdin
TSocket socket{std::move(addr), poller};
TLineReader lineReader(input, maxLineSize);
TByteWriter byteWriter(socket);
TByteReader byteReader(socket);
co_await socket.Connect();
while (auto line = co_await lineReader.Read()) {
co_await byteWriter.Write(line);
co_await byteReader.Read(in.data(), line.Size());
std::cout << "Received: " << std::string_view(in.data(), line.Size()) << "\n";
}
Заключение
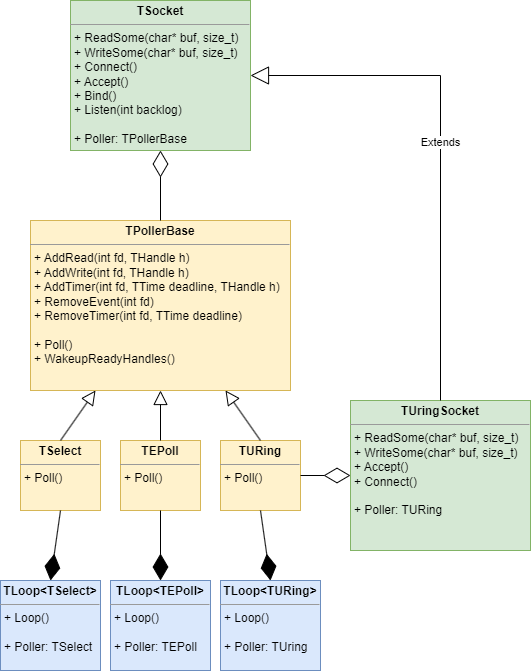
В заключение, архитектура разработанной мной библиотеки представлена на стартовой картинке статьи. Библиотека поддерживает множество механизмов полинга, включая select, poll, epoll, kqueue и uring. Хотя я не описываю протокол Raft в деталях (его можно найти в raft.pdf), я точно следовал его спецификации. Для сериализации сообщений использовалась техника чтения/записи запакованных структур в формате TLV. Пример сессии трёх серверов Raft и клиента демонстрирует функциональность:
$ ./server --id 1 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
Candidate, Term: 2, Index: 0, CommitIndex: 0,
Candidate, Term: 2, Index: 0, CommitIndex: 0,
Leader, Term: 3, Index: 0, CommitIndex: 0, Delay: 2:0 3:0 MatchIndex: 2:0 3:0 NextIndex: 2:1 3:1
Leader, Term: 3, Index: 0, CommitIndex: 0, Delay: 2:0 3:0 MatchIndex: 2:0 3:0 NextIndex: 2:1 3:1
Leader, Term: 3, Index: 0, CommitIndex: 0, Delay: 2:0 3:0 MatchIndex: 2:0 3:0 NextIndex: 2:1 3:1
...
Leader, Term: 3, Index: 1080175, CommitIndex: 1080175, Delay: 2:0 3:0 MatchIndex: 2:1080175 3:1080175 NextIndex: 2:1080176 3:1080176
....
$ ./server --id 2 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
Candidate, Term: 2, Index: 0, CommitIndex: 0,
Follower, Term: 3, Index: 0, CommitIndex: 0,
...
Follower, Term: 3, Index: 1080175, CommitIndex: 1080175,
...
$ ./server --id 3 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
Candidate, Term: 2, Index: 0, CommitIndex: 0,
Follower, Term: 3, Index: 0, CommitIndex: 0,
...
Follower, Term: 3, Index: 1080175, CommitIndex: 1080175,
...
$ dd if=/dev/urandom | base64 | pv -l | ./client --node 127.0.0.1:8001:1 >log1
198k 0:00:03 [159.2k/s] [ <=>
Исходный код сетевой библиотеки доступен на GitHub: coroio, где также можно ознакомиться с сравнительными графиками производительности по сравнению с libevent. Код библиотеки Raft также доступен: miniraft-cpp.
Часть 2
Эта статья является продолжением предыдущей публикации, в которой описывается разработка сетевой библиотеки на C++20. В данном продолжении акцент сделан на более детальном описании разработки алгоритма Raft и его интеграции с сетевой библиотекой.
Алгоритм Raft представляет собой ключевой компонент в архитектуре распределенных систем. Он применяется для обеспечения согласованности и надежности в условиях распределенных вычислений, позволяя системам эффективно управлять состоянием и принимать решения в условиях потенциальных сбоев и изменений в составе кластера.
Этот алгоритм особенно ценен для систем, где требуется высокая доступность и надежность, таких как распределенные базы данных, системы управления конфигурациями и многие другие области, где требуется координация действий между множеством узлов.
Основные понятия алгоритма Raft
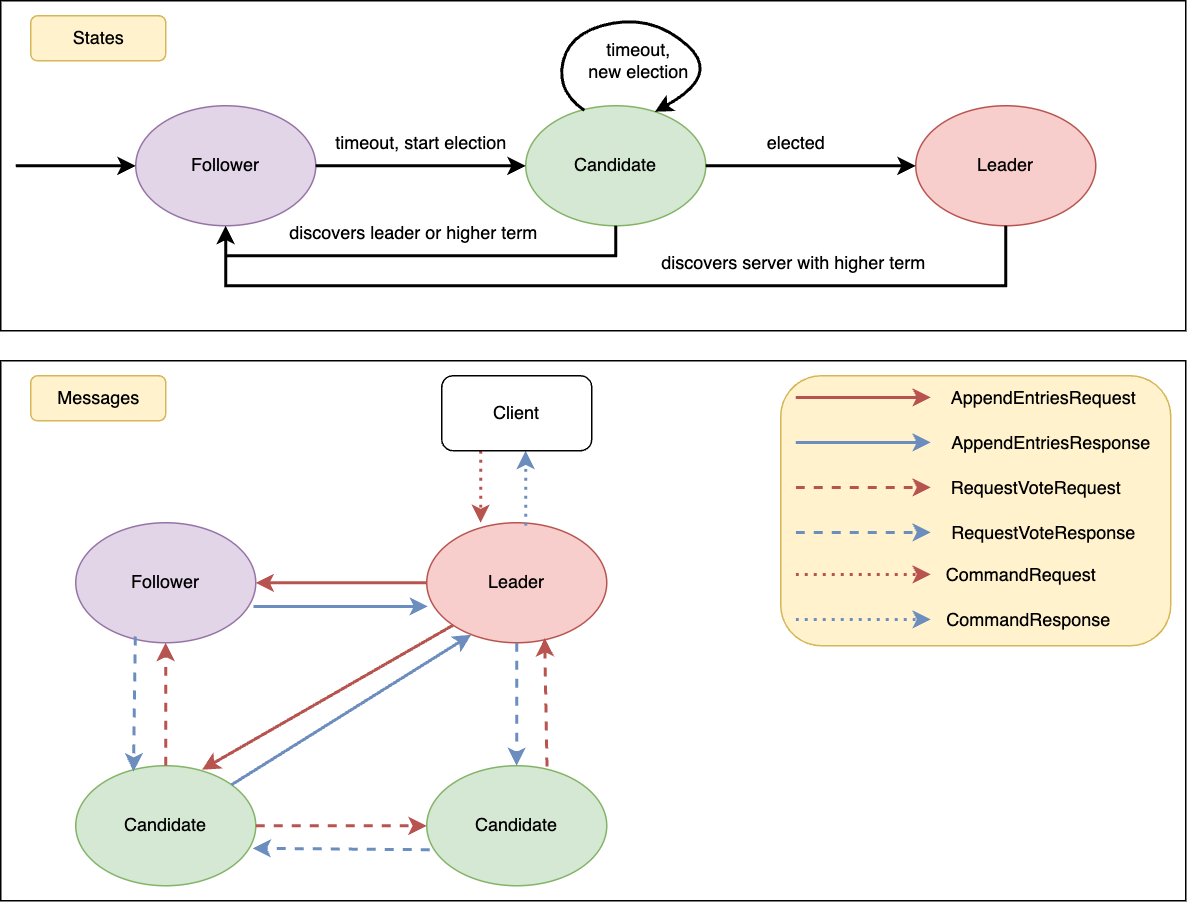
В Raft, каждый участник имеет одну из трех ролей: Leader, Follower или Candidate. Участники обмениваются сообщениями и меняют свои роли в соответствии с определенными правилами. Например, все участники начинают как Followers, становятся Candidates, если не получают сообщения от Leader, и проводят голосование. Чтобы стать Leader, участник должен получить большинство голосов. Диаграмма состояний и переходов между ними доступна на стартовой картинке к статье.
В алгоритме Raft, каждый участник обладает состоянием, которое делится на два вида: постоянное (persistent) и изменяемое (volatile). Постоянное состояние включает в себя несколько ключевых полей:
CurrentTerm: это число, которое увеличивается при каждом новом выборе лидера.VotedFor: участник хранит информацию о том, за кого он голосовал в последний раз.Log: это распределенный лог, который позволяет участнику добавлять к своему состоянию данные для реализации сложных сущностей на основе алгоритма Raft, таких как распределенные базы данных.
На C++:
struct TState {
uint64_t CurrentTerm = 1;
uint32_t VotedFor = 0;
std::vector<TMessageHolder<TLogEntry>> Log;
};
Изменяемое состояние (volatile) каждого участника включает важные поля:
CommitIndex: Индекс последней надёжно сохранённой записи в распределённом логе, подтверждённой большинством участников.LastApplied: Индекс последней записи, применённой к состоянию машины, полезен для реализации сложных систем, таких как базы данных.NextIndexиMatchIndex: Словари для отслеживания индексов логов, которые необходимо отправить на серверы (NextIndex) и индексы подтверждённых записей (MatchIndex).Votes: Множество голосов, собранных от узлов.HeartbeatDueиRpcDue: Словари для управления временем отправки сообщений и таймаутов RPC.ElectionDue: Время начала нового голосования, используется наFollower'ах для перехода в состояниеCandidateи начала голосования.
На языке C++:
using TTime = std::chrono::time_point<std::chrono::steady_clock>;
struct TVolatileState {
uint64_t CommitIndex = 0;
uint64_t LastApplied = 0;
std::unordered_map<uint32_t, uint64_t> NextIndex;
std::unordered_map<uint32_t, uint64_t> MatchIndex;
std::unordered_set<uint32_t> Votes;
std::unordered_map<uint32_t, TTime> HeartbeatDue;
std::unordered_map<uint32_t, TTime> RpcDue;
TTime ElectionDue;
};
В алгоритме Raft используются два основных типа сообщений, каждый из которых имеет свой ответ:
-
TAppendEntriesRequest: Используется лидером как для отправки Heartbeat-сообщений, так и для передачи новых записей
Follower'ам. В ответ на это сообщениеFollowerотправляет TAppendEntriesResponse. -
TRequestVoteRequest: Используется кандидатами для запроса голосования. Сообщение содержит информацию, необходимую другим узлам для принятия решения о том, стоит ли отдать голос за отправителя сообщения. В ответ на этот запрос другие узлы отправляют TRequestVoteResponse.
Дополнительно к основным сообщениям, Leader может получать от клиентов (не участников кластера) специальные сообщения типа TCommandRequest. Эти сообщения используются для добавления новых записей в распределенный лог. Это позволяет клиентам вносить изменения в состояние системы, которые затем реплицируются на остальные узлы кластера. Ответ на TCommandRequest генерируется и отправляется только после того, как сообщение было надежно сохранено на большинстве участников (majority) кластера Raft.
На рисунке в начале статьи наглядно изображены типы сообщений, которые могут передаваться между участниками алгоритма Raft. Правила обработки сообщений описаны в raft.pdf в таблице на странице 4, я не буду подробно на них останавливаться.
API Библиотеки
В API библиотеки для алгоритма Raft представлены два ключевых компонента:
- INode: Этот интерфейс определяет методы
Send(для отправки сообщений участникам, фактически добавляя их в буфер) иDrain(для использования и возможной отправки буферизованных сообщений):
struct INode {
virtual ~INode() = default;
virtual void Send(TMessageHolder<TMessage> message) = 0;
virtual void Drain() = 0;
};
- TRaft: Этот класс является основой, хранящей текущее состояние, стейты и ссылки на
INodeдля взаимодействия с другими участниками. Он обрабатывает входящие сообщения и управляет таймаутами. КлассTRaftтребует от пользователя библиотеки постоянной подачи новых сообщений и регулярного вызоваProcessTimeoutдля обработки таймаутов и переходов между состояниями:
class TRaft {
public:
TRaft(uint32_t node, const std::unordered_map<uint32_t, std::shared_ptr<INode>>& nodes);
void Process(TTime now, TMessageHolder<TMessage> message, const std::shared_ptr<INode>& replyTo = {});
void ProcessTimeout(TTime now);
};
Метод Process обрабатывает каждое сообщение в соответствии с текущим состоянием узла и правилами алгоритма Raft.
Метод ProcessTimeout занимается обработкой таймаутов. В случае истечения таймаута Follower переходит в состояние Candidate и инициирует процесс голосования для выбора нового лидера. С другой стороны, Leader использует таймауты для регулярной отправки Heartbeat сообщений, подтверждая своё лидерство.
Структура сообщений
В моей архитектуре Raft все сообщения производны от базового типа TMessage, который содержит поля для типа (Type), длины (Len) и собственно данных (Value):
enum class EMessageType : uint32_t {
NONE = 0,
LOG_ENTRY = 1,
REQUEST_VOTE_REQUEST = 2,
REQUEST_VOTE_RESPONSE = 3,
APPEND_ENTRIES_REQUEST = 4,
APPEND_ENTRIES_RESPONSE = 5,
COMMAND_REQUEST = 6,
COMMAND_RESPONSE = 7,
};
struct TMessage {
uint32_t Type;
uint32_t Len;
char Value[0];
};
Все сообщения, которые передаются между узлами, наследуются от TMessageEx, дополнительно включая поля для идентификации отправителя (Src), получателя (Dst) и текущего терма (Term):
struct TMessageEx: public TMessage {
uint32_t Src = 0;
uint32_t Dst = 0;
uint64_t Term = 0;
};
Для примера рассмотрим сообщение TAppendEntriesRequest, которое в алгоритме Raft используется лидером для отправки запросов на добавление записей в лог. Оно включает в себя поля PrevLogIndex, PrevLogTerm, LeaderCommit, LeaderId и Nentries. Поля PrevLogIndex и PrevLogTerm используются для того, чтобы Follower могли верифицировать и принимать набор сообщений:
struct TAppendEntriesRequest: public TMessageEx {
static constexpr EMessageType MessageType = EMessageType::APPEND_ENTRIES_REQUEST;
uint64_t PrevLogIndex = 0;
uint64_t PrevLogTerm = 0;
uint64_t LeaderCommit = 0;
uint32_t LeaderId = 0;
uint32_t Nentries = 0;
};
В случае наличия записей, за сообщением следует payload, состоящий из Nentries сообщений типа TLogEntry, каждое из которых содержит терм и данные:
struct TLogEntry: public TMessage {
static constexpr EMessageType MessageType = EMessageType::LOG_ENTRY;
uint64_t Term = 1;
char Data[0];
};
Остальные используемые сообщения:
struct TAppendEntriesResponse: public TMessageEx {
static constexpr EMessageType MessageType = EMessageType::APPEND_ENTRIES_RESPONSE;
uint64_t MatchIndex;
uint32_t Success;
};
struct TRequestVoteRequest: public TMessageEx {
static constexpr EMessageType MessageType = EMessageType::REQUEST_VOTE_REQUEST;
uint64_t LastLogIndex;
uint64_t LastLogTerm;
uint32_t CandidateId;
};
struct TRequestVoteResponse: public TMessageEx {
static constexpr EMessageType MessageType = EMessageType::REQUEST_VOTE_RESPONSE;
uint32_t VoteGranted;
};
struct TCommandRequest: public TMessage {
static constexpr EMessageType MessageType = EMessageType::COMMAND_REQUEST;
char Data[0];
};
struct TCommandResponse: public TMessage {
static constexpr EMessageType MessageType = EMessageType::COMMAND_RESPONSE;
uint64_t Index;
};
Для удобства преобразования между базовым сообщением и конкретными типами сообщений используется структура-обертка TMessageHolder. Эта обертка содержит указатель на сообщение (Mes), сырые данные (RawData), размер payload (PayloadSize) и payload (Payload). Методы Cast и Maybe обеспечивают удобное и безопасное преобразование типов сообщений:
template<typename T>
requires std::derived_from<T, TMessage>
struct TMessageHolder {
T* Mes;
std::shared_ptr<char[]> RawData;
uint32_t PayloadSize;
std::shared_ptr<TMessageHolder<TMessage>[]> Payload;
template<typename U>
requires std::derived_from<U, T>
TMessageHolder<U> Cast() {
return TMessageHolder<U>(static_cast<U*>(Mes), RawData, PayloadSize, Payload);
}
template<typename U>
requires std::derived_from<U, T>
auto Maybe() { ... }
};
В коде TRaft, методы Cast и Maybe используются для определения типа сообщения и соответствующей обработки, что упрощает обработку входящих сообщений и улучшает читаемость кода:
void TRaft::Candidate(TTime now, TMessageHolder<TMessage> message) {
if (auto maybeResponseVote = message.Maybe<TRequestVoteResponse>()) {
OnRequestVote(std::move(maybeResponseVote.Cast()));
} else if (auto maybeRequestVote = message.Maybe<TRequestVoteRequest>()) {
OnRequestVote(now, std::move(maybeRequestVote.Cast()));
} else if (auto maybeAppendEntries = message.Maybe<TAppendEntriesRequest>()) {
OnAppendEntries(now, std::move(maybeAppendEntries.Cast()));
}
}
void TRaft::Follower(TTime now, TMessageHolder<TMessage> message) {
if (auto maybeRequestVote = message.Maybe<TRequestVoteRequest>()) {
OnRequestVote(now, std::move(maybeRequestVote.Cast()));
} else if (auto maybeAppendEntries = message.Maybe<TAppendEntriesRequest>()) {
OnAppendEntries(now, std::move(maybeAppendEntries.Cast()));
}
}
void TRaft::Leader(TTime now, TMessageHolder<TMessage> message, const std::shared_ptr<INode>& replyTo) {
if (auto maybeAppendEntries = message.Maybe<TAppendEntriesResponse>()) {
OnAppendEntries(std::move(maybeAppendEntries.Cast()));
} else if (auto maybeCommandRequest = message.Maybe<TCommandRequest>()) {
OnCommandRequest(std::move(maybeCommandRequest.Cast()), replyTo);
} else if (auto maybeVoteRequest = message.Maybe<TRequestVoteRequest>()) {
OnRequestVote(now, std::move(maybeVoteRequest.Cast()));
} else if (auto maybeAppendEntries = message.Maybe<TAppendEntriesRequest>()) {
OnAppendEntries(now, std::move(maybeAppendEntries.Cast()));
}
}
В сетевой библиотеке чтение и запись сообщений реализованы простым и эффективным образом. Для записи используется метод Write класса TMessageWriter, который сначала записывает основное сообщение с помощью TByteWriter, а затем рекурсивно обрабатывает и записывает Payload:
template<typename TSocket>
TValueTask<void> TMessageWriter<TSocket>::Write(TMessageHolder<TMessage> message) {
co_await TByteWriter(Socket).Write(message.Mes, message->Len);
auto payload = std::move(message.Payload);
for (uint32_t i = 0; i < message.PayloadSize; ++i) {
co_await Write(std::move(payload[i]));
}
co_return;
}
Для чтения используется метод Read класса TMessageReader, который сначала читает тип и длину сообщения, а затем само сообщение и его Payload:
template<typename TSocket>
TValueTask<TMessageHolder<TMessage>> TMessageReader<TSocket>::Read() {
decltype(TMessage::Type) type;
decltype(TMessage::Len) len;
auto s = co_await Socket.ReadSome(&type, sizeof(type));
if (s != sizeof(type)) {
throw std::runtime_error("Connection closed");
}
s = co_await Socket.ReadSome(&len, sizeof(len));
if (s != sizeof(len)) {
throw std::runtime_error("Connection closed");
}
auto mes = NewHoldedMessage<TMessage>(type, len);
co_await TByteReader(Socket).Read(mes->Value, len - sizeof(TMessage));
auto maybeAppendEntries = mes.Maybe<TAppendEntriesRequest>();
if (maybeAppendEntries) {
auto appendEntries = maybeAppendEntries.Cast();
auto nentries = appendEntries->Nentries;
mes.InitPayload(nentries);
for (uint32_t i = 0; i < nentries; i++) {
mes.Payload[i] = co_await Read();
}
}
co_return mes;
}
Класс TRaftServer отвечает за управление сетевыми соединениями и обработку сообщений для TRaft. Для каждого входящего соединения запускается корутина, которая читает сообщения и передает их в TRaft для обработки. Эта корутина также регулярно вызывает ProcessTimeout и DrainNodes:
while (true) {
auto mes = co_await TMessageReader(client->Sock()).Read();
Raft->Process(std::chrono::steady_clock::now(), std::move(mes), client);
Raft->ProcessTimeout(std::chrono::steady_clock::now());
DrainNodes();
}
DrainNodes запускает корутины отправки сообщений для каждой ноды.
Помимо этого, запускается отдельная корутина для обслуживания таймаутов, которая периодически обновляет состояние Raft, выполняет DrainNodes и может выводить отладочную информацию:
while (true) {
Raft->ProcessTimeout(std::chrono::steady_clock::now());
DrainNodes();
auto t1 = std::chrono::steady_clock::now();
if (t1 > t0 + dt) {
DebugPrint();
t0 = t1;
}
co_await Poller.Sleep(t1 + sleep);
}
Эти корутины обеспечивают непрерывную и эффективную обработку сетевых сообщений и таймаутов в системе.
TRaftServer является шаблонным классом, параметризованным типом сокета TSocket. Возможные варианты сокетов включают TSocket для обычных сетевых операций, TUringSocket для операций через интерфейс io_uring, и TSslSocket --- обертку для SSL-соединений. Эта гибкая структура позволяет TRaftServer эффективно работать с различными типами сетевых соединений, обеспечивая широкий спектр возможностей для управления сетевыми взаимодействиями в рамках алгоритма Raft.
Тестирование
Класс TRaft разработан так, чтобы быть независимым от сети, что делает его особенно удобным для юнит-тестирования. Это позволяет разработчикам тестировать различные сценарии работы алгоритма Raft, не полагаясь на внешние сетевые компоненты. В качестве примера можно рассмотреть тестирование сценария 7f raft.pdf:
void test_follower_append_entries_7f(void**) {
std::vector<TMessageHolder<TMessage>> messages;
auto onSend = [&](const TMessageHolder<TMessage>& message) {
messages.push_back(message);
};
auto ts = std::make_shared<TFakeTimeSource>();
auto raft = MakeRaft(onSend, 3);
raft->SetState(TState{
.CurrentTerm = 1,
.VotedFor = 2,
.Log = MakeLog<TLogEntry>({1,1,1,2,2,2,3,3,3,3,3})
});
auto mes = NewHoldedMessage(TMessageEx {
.Src = 2,
.Dst = 1,
.Term = 8,
}, TAppendEntriesRequest {
.PrevLogIndex = 3,
.PrevLogTerm = 1,
.LeaderCommit = 9,
.LeaderId = 2,
.Nentries = 7,
});
SetPayload(mes, MakeLog({4,4,5,5,6,6,6}));
raft->Process(ts->Now(), mes);
auto last = messages.back().Cast<TAppendEntriesResponse>();
assert_true(last->Success);
assert_true(last->MatchIndex = 10);
assert_true(raft->GetState()->Log.size() == 10);
assert_terms(raft->GetState()->Log, {1,1,1,4,4,5,5,6,6,6});
}
В этом примере юнит-теста реализована ситуация, когда узел в состоянии Follower получает сообщения TAppendEntriesRequest. Тест имитирует приходящие сообщения и проверяет логику обработки и изменения состояния узла в соответствии с правилами Raft. Важным аспектом здесь является использование TFakeTimeSource - контролируемого источника времени, который заменяет системные часы. Это позволяет точно симулировать таймауты и другие временные зависимости.
Тестирование задержки (latency) записи сообщений одним клиентом на кластер из трех и пяти узлов проведено для оценки производительности. Результаты тестирования для кластера из трех узлов показывают следующие перцентили задержки в наносекундах:
- 50-й перцентиль (медиана): 292,872 нс
- 80-й перцентиль: 407,561 нс
- 90-й перцентиль: 569,164 нс
- 99-й перцентиль: 40,279,001 нс
Эти результаты указывают на то, что большинство операций записи происходит с относительно низкой задержкой.
Для кластера из пяти узлов результаты тестирования задержки записи сообщений показывают следующие значения:
- 50-й перцентиль (медиана): 425,194 нс
- 80-й перцентиль: 672,541 нс
- 90-й перцентиль: 1,027,669 нс
- 99-й перцентиль: 38,578,749 нс
Эти данные свидетельствуют о том, что с увеличением количества узлов задержки записи также увеличиваются.
В оценке задержек, полученных в тестах моей Raft библиотеки, нет однозначного ответа на вопрос, хорошие они или плохие. Всё зависит от того, что важнее для вашей системы: быстродействие или надёжность. Для критически важных систем, где каждая микросекунда на счету, эти задержки могут показаться высокими. Но если в приоритете надёжность и согласованность данных, то миллисекундные задержки --- это нормально. В конце концов, в распределённых системах, где требуется согласование данных между множеством узлов, такие показатели задержек часто являются приемлемым компромиссом.
Заключение
Подводя итог, хочется отметить, что созданная мной библиотека является ярким примером гибкого использования стандартных корутин C++20 для построения распределённых систем. Она несёт в себе основной функционал алгоритма Raft, управляя состояниями узлов и обрабатывая сообщения, но при этом оставляет простор для дальнейших улучшений и добавления продвинутых функций, таких как персистирование состояния на диск, снапшотинг и динамическое управление узлами.
Ссылки
Вот ссылки для дополнительной информации и материалов, упомянутых в статье:
- Предыдущая часть статьи: Разработка сетевой библиотеки на C++20: интеграция асинхронности и алгоритма Raft (часть 1))
- Основная статья об алгоритме Raft: Raft Consensus Algorithm
- Сетевая библиотека на GitHub: coroio
- Реализация Raft на GitHub: miniraft-cpp