Что каждый программист должен знать о памяти
Posted on Пн 08 июня 2026 in misc
Введение
Часть 1. Современное массовое аппаратное обеспечение
2.1 Типы RAM
2.2 Технические детали доступа к DRAM
2.3 Другие пользователи основной памяти
Часть 2. Кэш-память процессора
3.1 Кэш процессора - общая картина
3.2 Как работает кэш-память высокого уровня
3.3 Подробности реализации кэш-памяти процессора
3.3.1 Ассоциативность
3.3.2 Измерение влияния использования кэш-памяти
3.3.3 Запись данных
3.3.4 Поддержка многопроцессорности
3.3.5. Другие детали
3.4 Кэш-память инструкций
3.4.1 Самомодифицирующийся код
3.5 Коэффициенты промахов кэш-памяти
3.5.1 Пропускная способность кэш-памяти и основной памяти
3.5.2 Загрузка критических слов
3.5.3 Место размещения кэш-памяти
3.5.4 Влияние шины FSB
Часть 3. Виртуальная память
4.1 Простейшее преобразование адресов
4.2 Многоуровневые таблицы страниц
4.3 Оптимизация доступа к таблицам страниц
4.4 Значение виртуализации
Часть 4. Поддержка устройств NUMA
5.1 Аппаратные устройства NUMA
5.2 Поддержка NUMA в операционной системе
5.3 Предоставляемая информация
5.4 Стоимость удаленного доступа
Часть 5. Что могут делать программисты - оптимизация кеша
6.1 Обход кэша
6.2 Доступ к кэшу
6.2.1 Оптимизация доступа к кэшу данных 1 уровня
6.2.2 Оптимизация доступа к кэшу инструкций уровня 1
6.2.3 Оптимизация доступа к кэшу уровня 2 и выше
6.2.4 Оптимизация использования TLB
6.3 Предварительная загрузка
6.3.1 Аппаратная предварительная загрузка
6.3.2 Программная предварительная загрузка
6.3.3 Специальный вид предварительной загрузки: условная загрузка
6.3.4 Вспомогательные потоки
6.3.5 Прямой доступ к кэшу
Часть 6. На что еще способны программисты
6.4 Мультипотоковая оптимизация.
6.4.1 Оптимизация параллельного доступа
6.4.2 Оптимизация работы с атомарными операциями
6.4.3 Решаем проблемы с пропускной способностью
6.5 Программирование NUMA
6.5.1 Политика выделения памяти
6.5.2 Установка политик
6.5.3 Свопинг и политики выделения памяти
6.5.4 Политика VMA
6.5.5 Запросы информации об узлах
6.5.6 Наборы ЦПУ и узлов памяти
6.5.7 Явные оптимизации NUMA
6.5.8 Используем всю полосу пропускания
Часть 7. Инструменты для повышения производительности памяти.
7.1. Профилирование памяти
7.2. Моделирование кэшей ЦПУ
7.3. Оценка использования памяти
7.4. Улучшаем прогнозирование ветвлений
7.5. Оптимизация страничных ошибок
Часть 8. Технологии будущего
8.1. Проблемы с атомарными операциями
8.2. Транзакционная память
8.3. Увеличение латентности
8.4. Векторные операции
Часть 9. Приложения и библиография.
9 Примеры и программы-бенчмарки
9.1 Умножение матриц
9.2 Предсказание отладочного ветвления
9.3 Измерение издержек, связанных с общим использованием кэш-строк
10 Несколько советов по использованию oprofile
10.1 Базовые сведения о oprofile
10.2 Как это все выглядит
10.3 Запуск профилирования
11 Типы памяти
12 Введение в libNUMA
12.1 Поиск потоков, принадлежащих данному процессору (потоков-братьев)
12.2 Поиск ядер, принадлежащих данному процессору (ядер-братьев)
Библиография
Оригинал: What every programmer should know about memory Автор: Ulrich Drepper Дата публикации: 21.09.2007 Перевод: Капустин С.В. Дата перевода: 25.03.2009
В то время как ядра процессоров становятся быстрее и многочисленнее, ограничивающим фактором для большинства программ теперь, и будет еще некоторое время в будущем, является доступ к памяти. Разработчики аппаратного обеспечения внедряют все более изощренные технологии ускорения работы памяти, такие как кэши процессоров, но они не могут работать оптимально без некоторой помощи разработчика программного обеспечения. К несчастью, ни структура, ни стоимость использования подсистемы памяти компьютера или кэша процессора хорошо не осознается большинством разработчиков программного обеспечения. Эта статья объясняет структуру подсистемы памяти, используемую в современных массовых компьютерах, показывая, почему были разработаны процессорные кэши, как они работают, и что программа должна делать, чтобы добиться их оптимального использования.
1 Введение
Раньше компьютеры были намного проще. Различные компоненты системы, такие как процессор (ЦПУ), память, устройства хранения данных, сетевые интерфейсы, были разработаны вместе и, следовательно, были вполне сбалансированы по производительности. Например, память и сетевые интерфейсы были не (много) быстрее ЦПУ по пропускной способности.
Эта ситуация изменилась с тех пор как основная структура компьютеров стабилизировалась, и разработчики аппаратного обеспечения сконцентрировались на оптимизации отдельных подсистем. Неожиданно производительность некоторых подсистем отстала от других, и образовались так называемые "бутылочные горлышки". Это, прежде всего, относится к подсистемам хранения данных и памяти, которые из соображений стоимости улучшались медленнее по сравнению с другими компонентами.
Проблему отставания скорости устройств хранения данных решали в основном, используя программные технологии: операционная система хранит наиболее часто используемые (и те, что предположительно будут использованы) данные в основной памяти, которая обеспечивает скорость доступа на порядок больше, чем жесткий диск. И к самим устройствам хранения данных стали добавлять внутренний кэш, так что увеличение производительности достигалось без изменения операционной системы. {Изменения, однако, все равно необходимы, для того, чтобы гарантировать целостность данных.} Исходя из целей этой статьи, мы не будем далее углубляться в программную оптимизацию доступа к устройствам хранения данных.
В отличие от подсистемы хранения данных, устранение проблемы "бутылочного горлышка" для случая основной памяти оказалось более трудным делом, и почти все решения тут требуют изменений в аппаратном обеспечении. На сегодня эти изменения происходят в основном в следующих сферах:
- изменения в аппаратуре RAM (скорость и параллелизм);
- разработка контроллеров памяти;
- кэши ЦПУ;
- прямой доступ к памяти (DMA) для устройств.
Этот документ посвящен в основном кэшам ЦПУ и некоторым эффектам проектирования контроллеров памяти. В процессе исследования этих тем, мы рассмотрим прямой доступ к памяти (DMA) с целью его роли в общей картине. Однако начнем мы с обзора современного аппаратного обеспечения компьютеров. Это потребуется для понимания проблем и ограничений эффективного использования подсистемы памяти. Мы также расскажем о различных типах RAM и о том, почему различия все ещё существуют.
Этот документ ни в коем случае не претендует на полноту. Он ограничивается массовыми компьютерами и некоторым подмножеством их аппаратного обеспечения. Некоторые темы будут обсуждаться лишь настолько подробно, насколько это необходимо для целей этой статьи. Читателям рекомендуется найти более детальную документацию по таким темам.
Когда речь идет о деталях, специфичных для некоторой ОС, и используемых в ОС решениях, речь идет исключительно о Linux. О других ОС не будет дано никакой информации. У автора отсутствует интерес к обсуждению результатов, получающихся для других ОС. Если читатель считает, что он должен использовать другую ОС, он должен потребовать от её производителей написать подобный документ.
Последний комментарий перед началом. Текст содержит некоторое количество терминов "обычно" и других в кавычках. Технология, описываемая здесь, существует реальном мире во множестве вариаций, и эта статья описывает только наиболее распространенные версии. Нечасто бывает возможность делать утверждения, применимые абсолютно ко всем вариантам технологии, отсюда и кавычки.
1.1 Структура документа
Этот документ в основном для разработчиков программного обеспечения. Он не углубляется в технические детали так, чтобы быть полезным для читателей, ориентированных на аппаратное обеспечение. Но прежде, чем мы сможем перейти к практической информации для программистов, необходимый фундамент должен быть заложен.
Для этого вторая глава описывает технические детали памяти с произвольным доступом (RAM - random-access memory). Содержание главы полезно знать, но оно абсолютно не критично для понимания последующих глав. Соответствующие ссылки на эту главу даны в местах, где это требуется, так что нетерпеливый читатель может сначала пропустить большую часть главы.
Третья глава в деталях описывает поведение кэша ЦПУ. Чтобы текст был не таким сухим, используются рисунки. Эта глава существенно необходима для понимания остальной части документа. Глава 4 кратко описывает строение виртуальной памяти. Эта глава также необходима для остального.
Глава 5 описывает в деталях системы, построенные по технологии Non Uniform Memory Access (NUMA).
Глава 6 - это центральная глава всей статьи. Она собирает вместе информацию из предыдущих глав и дает программисту указания как писать код, работающий оптимально при разных ситуациях. Очень нетерпеливый читатель может начать чтение с этой главы и, если необходимо, возвращаться к предыдущим главам, чтобы освежить знания об используемых технологиях.
Глава 7 представляет инструменты, которые могут помочь программисту делать свою работу эффективнее. Даже при полном понимании технологии в сложных программных проектах бывает неочевидно, где кроются проблемы. Некоторые инструменты необходимы.
В главе 8 мы делаем обзор технологий, которые ожидаются в ближайшем будущем, или тех, которые неплохо было бы иметь.
1.2 Сообщения об ошибках
Автор намерен обновлять этот документ в случае обнаружения ошибок и при прогрессе технологий. Читатели, желающие сообщить об ошибках, могут сделать это при помощи электронной почты.
1.3 Благодарности
Хотел бы поблагодарить Джонрэя Фуллера и особенно Джонотана Корбета за участие в непосильной работе по приведению английского языка автора к более или менее общепринятой форме. Маркус Армбрустер предоставил много ценного материала о проблемах и упущениях текста.
1.4 Об этом документе
Заголовок этой статьи отдает дань классической статье Давида Голдберга "Что каждый программист должен знать об арифметике чисел с плавающей точкой". Эта статья все ещё не так широко известна, хотя каждый, кто садится за клавиатуру для серьезного программирования, должен её знать.
2 Современное массовое аппаратное обеспечение
Понимание устройства массового аппаратного обеспечения важно потому, что специализированное аппаратное обеспечение теряет свои позиции. Увеличение масштаба сейчас чаще достигается за счет горизонтального масштабирования, а не за счет вертикального. То есть сегодня проще использовать много небольших, соединенных вместе массовых компьютеров, чем несколько действительно больших очень быстрых (и дорогих) систем. Это так из-за того, что широко доступно недорогое и быстрое сетевое аппаратное обеспечение. Есть все ещё ситуации, когда применяются большие специализированные системы, и они все ещё предоставляют возможности для бизнеса, но в целом рынок почти целиком состоит из массового аппаратного обеспечения. На 2007 год Red Hat ожидает, что в будущем "стандартными строительными блоками" для большинства центров обработки данных будут компьютеры с числом процессоров до четырех, в каждом процессоре по четыре ядра, которые, в случае процессоров Intel будут использовать технологию гиперпоточности. {Гиперпоточность позволяет двум и более программам использовать одно ядро процессора с небольшим количеством дополнительного оборудования.} Это означает, что стандартная система в центре обработки данных будет иметь до 64 виртуальных процессоров. Машины большего размера будут поддерживаться, но четырехпроцессорные четырехъядерные системы представляются наиболее предпочтительными, и основная оптимизация будет направлена на эти машины.
В структуре массовых компьютеров существуют большие различия. Мы охватим более 90% таких компьютеров, концентрируясь на наиболее важных различиях. Имейте в виду, что технические детали меняются быстро, так что читатель должен принимать во внимание дату этой статьи.
Многие годы персональные компьютеры и небольшие серверы были построены на чипсете, состоящем из двух частей: Северный мост (Northbridge) и Южный мост (Southbridge). Рисунок 2.1 показывает эту структуру.

Рисунок 2.1: Структура с Северным и Южным мостом
Все ЦПУ (два в предыдущем примере, но может быть больше) соединены через системную шину (Front Side Bus, FSB) с Северным мостом. Северный мост содержит, кроме всего прочего, контроллер памяти, и его устройство определяет тип чипов RAM, используемых компьютером. Различные типы RAM, такие как DRAM, Rambus, и SDRAM, требуют различные контроллеры памяти.
Чтобы соединиться с другими системными устройствами Северный мост должен обмениваться данными с Южным мостом. Южный мост, часто именуемый мост ввода/вывода обменивается с устройствами через множество различных шин. Сегодня важное значение имеют шины PCI, PCI Express, SATA и USB, но также Южным мостом поддерживаются PATA, IEEE 1394, последовательные и параллельные порты. Более старые системы имеют слоты AGP, присоединенные к Северному мосту. Это делалось из соображений производительности и было связано с недостаточной скоростью обмена данными между Северным и Южным мостом. Однако сегодня слоты PCI-E присоединены к Южному мосту.
Из такой структуры системы вытекает несколько важных следствий:
- Все данные, которыми обмениваются ЦПУ друг с другом идут по той же шине, что используется для обмена данными с Северным мостом.
- Весь обмен данными с RAM проходит через Северный мост.
- У RAM имеется только один порт. {Мы не обсуждаем многопортовую RAM в этом документе, так как она не применяется в персональных компьютерах, по крайней мере там, где программист имеет к ней доступ. Её можно найти в специализированнам аппаратном обеспечении, таком как сетевые маршрутизаторы, где очень важна скорость.}
- Обмен данными между ЦПУ и устройствами, присоединенными к Южному мосту, идет через Северный мост.
В этом дизайне можно сразу увидеть пару "бутылочных горлышек". Одно такое "бутылочное горлышко" возникает при доступе устройств к RAM. На заре эры персональных компьютеров весь обмен данными с устройствами по любому мосту шел через ЦПУ, негативно влияя на общую производительность системы. Чтобы этого избежать некоторые устройства получили возможность прямого доступа к памяти (DMA - direct memory access). DMA позволяет устройствам получать и сохранять данные в RAM с помощью Северного моста, не используя ЦПУ (и неизбежно влияя на его производительность). Сегодня все высокопроизводительные устройства, подключенные к любому мосту, могут использовать DMA. И хотя это очень сильно снижает загрузку ЦПУ, это создает конкуренцию за пропускную способность Северного моста, так как запросы DMA соревнуются с доступом ЦПУ к RAM. Эта проблема должна приниматься во внимание.
Второе "бутылочное горлышко" относится к шине от Северного моста к RAM. Точные детали устройства этой шины зависят от используемого типа памяти. На старых системах только одна шина ведет ко всем чипам RAM и параллельный доступ невозможен. Современные типы RAM требуют двух раздельных шин (или каналов, как они называются для DDR2, см. рисунок 2.8), что удваивает доступную пропускную способность. Северный мост распределяет доступ к памяти между каналами. Более новые технологии, (FB-DRAM, например) добавляют ещё больше каналов.
Имея в виду ограниченную пропускную способность, важно так составить расписание доступа к памяти, чтобы минимизировать задержки. Как мы увидим, процессоры намного быстрее и должны ждать доступа к памяти, несмотря на использование процессорных кэшей. Когда к памяти одновременно пытаются получить доступ множество процессоров, их ядер или потоков, ожидание становится ещё длиннее. Это также справедливо для операций DMA.
Кроме параллельного доступа к памяти есть и другие проблемы. Сами модели доступа к данным очень сильно влияют на производительность подсистемы памяти, особенно когда есть несколько каналов памяти. Модели доступа к данным RAM будут подробно обсуждаться в разделе 2.2.
На некоторых более дорогих системах Северный мост не содержит контроллера памяти. Вместо этого Северный мост может быть подключен к нескольким внешним контроллерам памяти (в следующем примере к четырем).

Рисунок 2.2: Северный мост с внешними контроллерами памяти
Преимущество такой архитектуры в том, что есть больше, чем одна шина памяти и, следовательно, общая пропускная способность больше. Также этот дизайн поддерживает больший объем памяти. При параллельном доступе к памяти задержка снижается за счет одновременного доступа к разным банкам. Это особенно верно, когда к Северному мосту подключено несколько процессоров, как на рисунке 2.2. Для такого дизайна первичное ограничение - это внутренняя пропускная способность Северного моста, феноменальная для этой архитектуры (от Intel). {Для полноты следует заметить, что такое расположение контроллеров памяти может быть использовано для других целей, таких как ⌠RAID памяти, полезный при использовании памяти с возможностью горячей замены.}
Использование нескольких контроллеров памяти не единственный способ увеличить пропускную способность памяти. Другой популярный способ - это встраивать контроллеры памяти в ЦПУ и присоединять к каждому ЦПУ память. Эта модель популярна на системах с архитектурой SMP (symmetric multiprocessing), базирующихся на процессорах Opteron от AMD. Рисунок 2.3 показывает такую систему. У Intel, начиная с процессоров Nehalem, будет поддержка технологии Common System Interface (CSI). Это в основном тот же подход: встроенный контроллер памяти с возможностью локальной памяти для каждого процессора.

Рисунок 2.3: Встроенный контроллер памяти
В такой архитектуре количество банков памяти равно количеству процессоров. На четырехпроцессорной машине пропускная способность памяти будет в 4 раза больше и отпадет необходимость в сложном Северном мосте с огромной пропускной способностью. То, что контроллер памяти встроен в ЦПУ, также имеет ряд преимуществ, мы не будем сейчас в это углубляться.
Но у такой архитектуры есть и недостатки. Во-первых, так как по-прежнему вся память машины должна быть доступна для всех процессоров, память более не является однородной (отсюда и название - "архитектура с неоднородной памятью", NUMA - Non-Uniform Memory Architecture). Локальная память процессора доступна ему на обычной скорости. Ситуация меняется, когда нужно получить доступ к памяти, расположенной на другом процессоре. Тут приходится использовать соединения между процессорами. Чтобы получить доступ к памяти ЦПУ2 из ЦПУ1, нужно пройти по одному соединению. Чтобы получить доступ к памяти ЦПУ4 из ЦПУ1, нужно пройти по двум соединениям.
Каждый проход по соединению имеет соответствующую стоимость. Мы говорим о "факторах NUMA", когда описываем дополнительное время, необходимое, чтобы достичь удаленной памяти. Пример архитектуры на рисунке 2.3 имеет два уровня для каждого ЦПУ: ЦПУ, который находится рядом, и ЦПУ, который находится через два соединения. На более сложных машинах число уровней может быть значительно больше. Есть также архитектуры (например x445 у IBM x445 и Altix у SGI), где более одного типа соединения. ЦПУ организованы в узлы, и внутри узла время доступа к памяти может быть однородным или иметь небольшой фактор NUMA. Соединение между узлами может быть очень дорогим, с большим фактором NUMA.
Массовые машины с архитектурой NUMA существуют сегодня и, наверное, будут играть все большую роль в будущем. Ожидается, что с конца 2008 года все машины с технологией SMP будут использовать архитектуру NUMA. Ограничения этой архитектуры делают важной способность программы учитывать то, что она использует NUMA. В главе 5 мы еще обсудим архитектуры машин и некоторые технологии, которые ядро Linux предоставляет для программ.
Кроме технических деталей, описанных в оставшейся части этой главы есть несколько дополнительных факторов, влияющих на производительность RAM. Программное обеспечение не может на них влиять, поэтому в этом разделе они не описываются. Заинтересованный читатель может узнать о некоторых из них в разделе 2.1. Это нужно только для полноты картины и возможно будет полезно при принятии решения о приобретении компьютера.
Следующие две главы обсуждают детали устройства памяти на уровне выходов и протокол доступа между контроллером памяти и чипами DRAM. Программисты найдут эту информацию поучительной, так как эти детали объясняют, почему доступ к RAM работает так, как он работает. Это не обязательное знание и читатель, ищущий темы, более приближенные к повседневной жизни, может перейти к разделу 2.2.5.
2.1 Типы RAM
За прошедшие годы было много типов RAM, и каждый тип отличался, зачастую значительно, от другого. Старые типы сегодня интересны только историкам. Мы не будем исследовать их детали. Вместо этого мы сконцентрируемся на современных типах RAM. Мы пройдем только по поверхности, исследуя детали, видимые ядру ОС или разработчику программного обеспечения через характеристики производительности.
Первые интересные детали сосредоточены вокруг вопроса, почему существуют различные типы RAM на одной и той же машине. Более конкретно, почему существуют вместе статическая RAM (SRAM {В других контекстах SRAM может означать ⌠синхронная RAM.}) и динамическая RAM (DRAM). Первая намного быстрее и предоставляет ту же функциональность. Почему не вся RAM на машине это SRAM? Ответ, как легко ожидать, в цене. SRAM намного дороже производить и использовать, чем DRAM. Оба этих фактора важны, важность второго возрастает все больше и больше. Чтобы понять эту разницу, мы посмотрим, как реализовано хранение единицы информации для SRAM и DRAM.
В оставшейся части этого раздела обсуждаются низкоуровневые детали реализации RAM. Будем вдаваться в детали ровно настолько, насколько это требуется. То есть будем обсуждать сигналы на "логическом уровне", а не на том уровне, на котором их рассматривают разработчики аппаратного обеспечения. Этот уровень для наших целей достаточен.
2.1.1 Статическая RAM
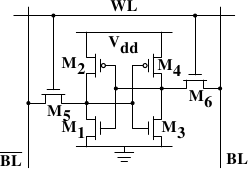
Рисунок 2.4: 6-транзисторная статическая RAM
Рисунок 2.4 показывает структуру 6-транзисторной ячейки SRAM. Ядро этой ячейки формируется четырьмя транзисторами от M1 до M4, которые формируют два перекрещенных инвертера. Они имеют два стабильных состояния, представляющих 0 и 1 соответственно. Состояние остается стабильным, пока подается напряжение Vdd.
Если нужно узнать состояние ячейки, на линию доступа к слову WL подается ток. Это немедленно делает состояние ячейки доступным на BL и BL. Если нужно записать новое состояние, сначала устанавливаются нужные значения на BL и BL и затем подается ток на WL. Так как внешние генераторы сильнее четырех транзисторов (от M1 до M4), это позволяет перезаписать старое состояние.
Более детальное описание того, как работают ячейки памяти можно найти в [1]. Для дальнейшего обсуждения важно отметить следующее:
- одна ячейка требует шесть транзисторов. Есть варианты с четырьмя транзисторами, но у них есть недостатки.
- поддержание состояния ячейки требует постоянного наличия напряжения.
- состояние ячейки становится доступным почти немедленно после подачи напряжения на WL. Сигнал настолько прямоугольный (быстро меняется между двумя двоичными состояниями) насколько таковыми являются все сигналы, управляемые транзисторами.
- состояние ячейки стабильное, циклы регенерации не требуются.
Есть другие формы SRAM, более медленные и экономичные, но они нам неинтересны, так как мы смотрим на быструю RAM. Эти медленные варианты интересны в основном из-за того, что они могут использоваться вместо динамической RAM, так как имеют более простой интерфейс.
2.1.1 Динамическая RAM
Динамическая RAM по своей структуре намного проще, чем статическая. Рисунок 2.5 показывает структуру типичной ячейки DRAM. Она состоит всего из одного транзистора и одного конденсатора. Огромная разница в сложности означает, конечно, что она и функционирует совсем по-другому.

Figure 2.5: 1-транзисторная динамическая RAM
Ячейка динамической RAM хранит своё состояние в конденсаторе C. Транзистор M служит для того, чтобы охранять доступ к состоянию. Чтобы прочитать состояние ячейки подается ток на линию доступа AL, это приводит к тому, что в зависимости от наличия заряда в конденсаторе на линии DL может появиться или не появиться ток. Чтобы записать данные в ячейку линия DL соответственно устанавливается, затем на AL подается ток на время, достаточное для зарядки или разрядки конденсатора.
Есть некоторые затруднения при реализации схемы работы динамической RAM. Использование конденсатора означает, что чтение ячейки разряжает конденсатор. Эта процедура не может повторяться до бесконечности, в некоторый момент конденсатор необходимо перезарядить. Еще хуже то, что для того, чтобы обеспечивать энергией огромное количество ячеек (сейчас на чипах 109 или больше ячеек) емкость конденсатора должна быть маленькой (на уровне фемтофарад или ниже). Полностью заряженный конденсатор содержит несколько десятков тысяч электронов. И хотя сопротивление конденсатора велико (пара тераОм), он самопроизвольно разряжается за короткое время. Эта проблема называется "утечки".
Из-за утечек ячейки DRAM нужно постоянно подзаряжать. Сейчас для большинства чипов DRAM эта подзарядка происходит каждые 64 миллисекунды. Во время цикла подзарядки доступ к памяти невозможен. В некоторых случаях это задерживает до 50% обращений к памяти (см. [2]).
Вторая проблема, возникающая из-за маленького заряда, это то, что информация, прочитанная из ячейки, не может быть сразу использована. Линия данных должна быть подключена к усилителю считывания, который должен определить, 0 это или 1, так как единицей может быть целый диапазон значений заряда.
Третья проблема, это то, что чтение ячейки истощает заряд конденсатора. Это означает, что после каждой операции чтения должна идти операция перезарядки конденсатора. Это делается автоматически направлением выхода из усилителя считывания обратно в конденсатор. Это означает, однако, что чтение требует дополнительной энергии и, что более важно, времени.
Четвертая проблема, это то, что зарядка и разрядка конденсатора не происходят мгновенно. Сигналы, получаемые усилителем считывания не прямоугольной формы, поэтому нужно использовать консервативную оценку времени, когда может быть использован результат чтения ячейки. Вот формулы зарядки и разрядки конденсатора:

Это означает, что конденсатору нужно некоторое время (определяемое емкостью C и сопротивлением R), чтобы зарядиться или разрядиться. Это также означает, что ток, который может быть распознан усилителем считывания, появляется не сразу. Рисунок 2.6 показывает кривые зарядки и разрядки. Единицами измерения оси X служат единицы произведения емкости на сопротивление RC, которые являются единицами времени.

Рисунок 2.6: Время зарядки и разрядки конденсатора
В отличие от случая статической RAM, где результат чтения ячейки появляется немедленно после подачи тока на линию доступа слова, всегда проходит некоторое время пока конденсатор отдаст достаточное количество заряда. Эта задержка жестко ограничивает скорость DRAM.
Простой подход имеет и свои преимущества. Основное - это размер. Площадь на чипе, необходимая для одной ячейки DRAM во много раз меньше площади для ячейки SRAM. Ячейкам SRAM также необходимо отдельное питание для транзисторов, поддерживающих её состояние. Структура ячейки DRAM также позволяет располагать рядом друг с другом много ячеек, образующих матрицу.
В общем, значительная разница в стоимости побеждает. Везде, кроме специализированного аппаратного обеспечения (например, сетевых маршрутизаторов), мы вынуждены жить с основной памятью, основанной на DRAM. Это оказывает громадное влияние на работу программиста, что мы и обсудим далее в этой статье. Но сначала ещё несколько деталей об использовании DRAM.
2.1.3 Доступ к DRAM
Программа выбирает расположение данных в памяти, используя виртуальный адрес. Процессор преобразует его в физический адрес и, окончательно, контроллер памяти выбирает чип RAM, соответствующий этому адресу. Чтобы выбрать конкретную ячейку памяти на чипе RAM, передается физический адрес в форме некоторого количества адресных линий.
Было бы совершенно непрактично адресовать каждый участок памяти непосредственно из контроллера памяти: 4Гб RAM потребовали бы 232 адресных линий. Вместо этого адрес передается как двоичное число, используя меньшее количество адресных линий. В чипе DRAM этот адрес нужно, прежде всего, демультиплексировать. Демультиплексор с N адресными линиями будет иметь 2N выходов. Эти выходы будут использоваться для выбора ячейки памяти. Использование такого прямого подхода не является проблемой для чипов небольшого размера.
Но число ячеек растет, и этот подход больше не работает. Чип с емкостью 1Гбит (ненавижу эти десятичные префиксы из СИ. Для меня гигабит всегда будет 230, а не 109 бит.) потребовал бы 30 адресных линий и 230 линий выбора. Размер демультиплексора растет экспоненциально при росте числа входных линий, если мы не хотим жертвовать скоростью. Демультиплексор с 30 входными линиями занимает большую площадь на чипе и вдобавок очень сложен. Еще важнее то, что передать 30 импульсов по адресным линиям синхронно намного сложнее, чем, скажем, "всего" 15. Меньше линий придется в этом случае подгонять по длине так, чтобы сигнал доходил до конца по ним одновременно. {Современные типы DRAM такие, как DDR3, могут автоматически подгонять время, но есть пределы допустимых расхождений.}

Рисунок 2.7: Схема динамической RAM
На рисунке 2.7 изображена упрощенная схема строения DRAM. Ячейки DRAM организованы в строки и колонки. Можно было бы расположить их в одной строке, но тогда потребовался бы огромный демультиплексор. А так мы можем обойтись одним мультиплексором и одним демультиплексором общим размером вполовину меньше. {Мультиплексоры и демультиплексоры эквивалентны, и мультиплексор здесь будет работать как демультиплексор при записи. Поэтому отныне мы будем их отождествлять.} Это огромная экономия со всех сторон. В этом примере адресные линии a0 и a1 через демультиплексор выбора адреса строки (RAS - row address selection) выбирают адресную линию целой строки ячеек. При чтении содержимое всех ячеек строки подается на мультиплексор выбора адреса колонки (CAS - column address selection) {линия над именами означает логическое отрицание}. На основе адреса, полученного по адресным линиям a2 и a3, содержимое одной из колонок подается на выход чипа DRAM. Это происходит параллельно на некотором количестве чипов DRAM, для того чтобы получить количество бит, соответствующее ширине шины данных.
При записи новое значение ячейки подается на шину данных и, когда ячейка выбрана через RAS и CAS, оно сохраняется в ячейке. Очень простой дизайн. Конечно, в реальности намного больше сложностей. При чтении нужно определить задержку, с которой данные поступают на шину данных, после подачи сигнала с адресом. Мы знаем из предыдущего раздела, что конденсаторы не отдают заряд мгновенно. Сигнал от ячеек такой слабый, что его нужно усиливать. При записи нужно определить, как долго должен подаваться сигнал с данными на шину, после того как выбраны адреса строк и колонок, чтобы успешно сохранить новое значение в ячейке (опять же конденсаторы не заряжаются мгновенно). Эти временные константы являются ключевыми для производительности чипа DRAM. Мы обсудим их в следующем разделе.
Ещё одна проблема масштабируемости состоит в том, что невозможно к каждому чипу подвести 30 адресных линий. Ножки чипа это драгоценный ресурс. К сожалению, данные по возможности должны передаваться параллельно (например, в 64 битных командах). Контроллер памяти должен уметь делать адресацию каждого модуля RAM (набора чипов RAM). Если по соображениям производительности требуется параллельный доступ к нескольким модулям RAM, и каждый модуль RAM требует свой набор из 30 или более адресных линий, тогда контроллеру памяти для 8 модулей RAM потребовалось бы более 240 ножек только для адресации.
Чтобы решить эту проблему, чипы DRAM уже давно мультиплексируют адреса самостоятельно. Это означает, что адрес передается двумя частями. Первая часть адресных бит (a0 и a1 в примере на рисунке 2.7) выбирает строку. Этот выбор остается активным, пока его не отменяют. Затем вторая часть, адресные биты a2 и a3, выбирает колонку. Ключевое отличие в том, что нужны только две внешние адресные линии. Ещё несколько линий будет необходимо для того, чтобы показывать, когда сигналы RAS и CAS готовы, но это небольшая плата за уменьшение числа адресных линий вдвое. Это мультиплексирование адресов само по себе, однако, создает некоторые проблемы. Мы обсудим их в разделе 2.2.
2.1.4 Выводы
Не беспокойтесь, если детали этого раздела покажутся вам неясными. Вот все важные вещи, которые нам понадобятся в дальнейшем:
- есть причины, почему не вся память является памятью типа SRAM
- чтобы использовать конкретную ячейку памяти, её нужно предварительно выбрать
- число адресных линий непосредственно влияет на стоимость контроллера памяти, материнской платы, модуля DRAM и чипа DRAM
- результаты операций чтения и записи доступны не сразу, а через некоторое время
В следующем разделе мы немного углубимся в детали процесса доступа к памяти DRAM. Мы не будем больше обсуждать детали доступа к SRAM, которая обычно адресуется напрямую. Так поступают для большей скорости и из-за небольшого размера SRAM. SRAM в настоящее время используется как встроенная в кэшах ЦПУ, а там размер соединений маленький и полностью под контролем разработчика ЦПУ. Кэши ЦПУ мы обсудим позже, но все, что мы должны знать, это то, что ячейки SRAM имеют определенную максимальную скорость, которая зависит от напряжения, приложенного к SRAM. Эта скорость может варьироваться от немного медленнее, чем ядро ЦПУ, до на один или два порядка медленнее.
[1] Wikipedia. Static random access memory. http://en.wikipedia.org/wiki/Static_Random_Access_Memory, 2006.
[2] Vinodh Cuppu, Bruce Jacob, Brian Davis and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133--1153, 2001.
[3] Stokes, Jon ``Hannibal''. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM. http://arstechnica.com/paedia/r/ram_guide/ram_guide.part2-1.html, 2004.
[4] Dowler, M. Introduction to DDR-2: The DDR Memory Replacement. http://www.pcstats.com/articleview.cfm?articleID=1573, 2004.
[5] Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003.
2.2 Технические детали доступа к DRAM
В предыдущем разделе мы видели, что чипы DRAM мультиплексируют адреса, чтобы сэкономить ресурсы. Мы также видели, что доступ к ячейкам DRAM требует времени, так как конденсаторы в этих ячейках разряжаются таким образом, что не сразу выдают стабильный сигнал. Мы также видели, что ячейки DRAM необходимо подзаряжать. Теперь пришло время собрать это все вместе и посмотреть, как эти факторы определяют детали доступа к DRAM.
Мы сконцентрируемся на современной технологии, мы не будем обсуждать асинхронную DRAM и её варианты, так как они неактуальны. Читатели, заинтересованные этой темой, отсылаются к [2] и [3]. Мы также не будем говорить о Rambus DRAM (RDRAM), хотя эта технология и не является вышедшей из употребления. Просто она не используется широко в системной памяти. Мы сконцентрируемся исключительно на синхронной DRAM (SDRAM - Synchronous DRAM) и её последовательнице Double Data Rate DRAM (DDR).
Синхронная DRAM, как следует из её названия, работает по источнику времени. В контроллере памяти имеется тактовый генератор, частота которого определяет частоту системной шины (FSB - Front Side Bus) - интерфейс контроллера памяти, используемый чипами DRAM. Во время написания этого текста используются частоты 800МГц, 1066МГц, и даже 1333МГц, а частота 1600МГц анонсирована для следующего поколения. Это не означает, что частота шины действительно такая высокая. Вместо этого за один такт данные передаются два или четыре раза. Большие числа лучше продаются, поэтому производители рекламируют шину 200МГц с учетверенной скоростью передачи данных как шину с "эффективной" частотой 800МГц.
Сегодня для SDRAM одна порция передачи данных составляет 64 бит - 8 байт. Следовательно, скорость передачи данных для FSB это 8 байт умножить на эффективную частоту шины (6.4Гб/с для шины 200МГц с учетверенной скоростью передачи данных). Кажется, что это много, но это пиковая скорость, максимум, который невозможно превзойти. Как мы увидим, протокол обмена данными с модулем RAM предполагает наличие множества отрезков времени, когда никакие данные не передаются. Это как раз такие отрезки времени, которые мы должны научиться понимать и минимизировать, чтобы добиться наилучшей производительности.
2.2.1 Протокол доступа к чтению

Рисунок 2.8: Временные диаграммы протокола доступа к чтению из SDRAM
Рисунок 2.8 показывает активность на некоторых выходах модуля DRAM, которую можно разделить на три фазы, которые на рисунке окрашены в разные цвета. Как обычно, время течет слева направо. Многие детали опущены. Здесь мы говорим только о тактовых импульсах шины, сигналах RAS и CAS и шинах адреса и данных. Цикл чтения начинается с того, что контроллер памяти посылает по адресной шине адрес строки и понижает уровень сигнала RAS. Все сигналы читаются во время повышения уровня сигнала тактового генератора (CLK), поэтому не имеет значения, что сигналы не совсем прямоугольной формы - лишь бы они были стабильны, когда их начнут читать. Установка адреса строки побуждает чип RAM фиксировать адресную строку.
Сигнал CAS может быть послан через tRCD (RAS-to-CAS Delay) тактов. Затем по адресной шине передается адрес колонки и понижается уровень сигнала CAS. Здесь мы видим как две части адреса (практически половинки) могут быть переданы по одной и той же адресной шине.
Наконец адресация закончена и можно передавать данные. Чипу RAM нужно некоторое время, чтобы подготовить это. Эта задержка обычно называется CAS Latency (CL). На рисунке 2.8 она равна 2. Она может быть выше или ниже, в зависимости от качества контроллера памяти, материнской платы и модуля DRAM. Она также может принимать половинные значения. При CL=2.5 первые данные начнут передаваться на первом понижении сигнала тактового генератора в синей области.
Со всеми этими приготовлениями было бы расточительно передавать только одно слово данных. Вот почему модули DRAM позволяют контроллеру памяти задавать количество передаваемых данных. Обычно выбор между 2, 4, или 8 словами. Это позволяет заполнить целые строки кэшей без новой последовательности RAS/CAS. Контроллер памяти может также послать сигнал CAS без нового выбора строки. Так можно считывать или записывать последовательно идущие адреса памяти значительно быстрее, из-за того, что не нужно посылать сигнал RAS и деактивировать строку (см. ниже). Контроллер памяти должен решать, хранить ли строку "открытой". Теоретически, если держать её все время открытой, то это может иметь отрицательные последствия в существующих приложениях (см. [2]). Когда посылать новый сигнал CAS - определяется свойством Command Rate модуля RAM (обычно обозначается как Tx, где x это значение такое как 1 или 2, оно будет равно 1 для высокопроизводительных модулей DRAM, которые принимают новые команды каждый цикл).
В этом примере SDRAM выдает одно слово за цикл. Это то, что может делать первое поколение. DDR может передавать два слова за цикл. Это сокращает время передачи, но не изменяет задержку. В принципе, DDR2 работает так же, хотя на практике это выглядит по-другому. Здесь нет необходимости углубляться в детали. Достаточно отметить, что DDR2 можно сделать быстрее, дешевле, более надежной и более энергоэффективной (см. [4] для более подробной информации).
2.2.2 Предварительная зарядка и активация
Рисунок 2.8 не покрывает полный цикл. Он показывает только часть полного цикла доступа к DRAM. Перед тем как можно будет послать новый сигнал RAS текущая выбранная строка должна быть деактивирована и новая строка должна быть заряжена. Мы можем сконцентрироваться здесь на случае, когда это делается явной командой. Есть улучшения протокола, которые, в некоторых случаях, позволяют обойтись без этого дополнительного шага. Однако задержка, вызванная зарядкой, все равно влияет на операцию.

Рисунок 2.9: Предварительная зарядка и активация SDRAM
Рисунок 2.9 показывает активность, начинающуюся от одного сигнала CAS, и заканчивающуюся сигналом CAS для другой строки. Данные, затребованные первым сигналом CAS, появляются как и раньше через CL циклов. В этом примере затребованы два слова, на передачу которых SDRAM требуется два цикла. Можно представить себе четыре слова на чипе DDR.
Даже на модулях DRAM с command rate равным 1 команда на предварительную зарядку не может быть запущена сразу. Необходимо ждать пока передаются данные. В нашем случае это два цикла. Получается то же, что и CL, но это просто совпадение. Сигнал на предварительную зарядку не имеет специальной выделенной линии. Вместо этого на некоторых реализациях используется одновременное понижение уровней Write Enable (WE) и RAS. Эта комбинация не имеет смысла сама по себе (см. подробности кодирования в [5]).
После того, как команда на предварительную зарядку передана, нужно ждать tRP (Row Precharge time) циклов до того как строка может быть выбрана. На рисунке 2.9 большая часть этого времени (обозначенная фиолетовым цветом) пересекается с передачей данных (светло-синий). Это хорошо! Но tRP больше, чем время передачи данных, поэтому следующий сигнал RAS задерживается на один цикл.
Если бы мы продолжили ось времени в диаграмме, то обнаружили бы, что следующая передача данных начинается через 5 циклов после окончания текущей. Это значит, что шина данных используется только в двух циклах из семи. Умножьте это на скорость FSB, и теоретические 6.4Гб/с для шины частотой 800МГц превратятся в 1.8Гб/с. Это плохо, и этого следует избегать. Техники, описанные в главе 6, помогут увеличить эту скорость. Но программист должен для этого постараться.
Есть ещё одна временная константа для модулей SDRAM, которую мы не обсудили. На рисунке 2.9 команда на предварительную зарядку ограничена только временем передачи данных. Другое ограничение состоит в том, что модулю SDRAM необходимо время после сигнала RAS, прежде чем он сможет заряжать другую строку (это время обозначается tRAS). Это число обычно довольно высоко, в два или три раза больше значения tRP. Это проблема, если после сигнала RAS следует только один сигнал CAS и передача данных заканчивается через несколько циклов. Предположим, что на рисунке 2.9 первому сигналу CAS непосредственно предшествует сигнал RAS и tRAS равно 8 циклам. Тогда команду на предварительную зарядку нужно отложить на один цикл, так как сумма tRCD, CL, и tRP (т.к. оно больше, чем время передачи данных) составляет всего 7 циклов.
Модули DDR часто описываются, используя специальную нотацию: w-x-y-z-T. Например: 2-3-2-8-T1. Это означает:
| w | 2 | CAS Latency (CL) |
| x | 3 | RAS-to-CAS delay (tRCD) |
| y | 2 | RAS Precharge (tRP) |
| z | 8 | Active to Precharge delay (tRAS) |
| T | T1 | Command Rate |
Есть ещё множества временных констант, которые влияют на то, как должны даваться и исполняться команды. Но на практике этих пяти констант достаточно, чтобы определять производительность модуля.
Иногда полезно знать эту информацию об используемом компьютере, чтобы правильно интерпретировать определенные измерения. И определенно полезно знать эти детали, когда покупаешь компьютер, так как они, вместе со скоростями FSB и SDRAM, являются одними из важнейших факторов, определяющих производительность компьютера.
Склонный к приключениям читатель может также попытаться настроить систему. Иногда BIOS позволяет изменять некоторые или все из этих значений. У модулей SDRAM имеются программируемые регистры, где можно установить эти значения. Обычно BIOS выбирает наилучшее из значений по умолчанию. Если модуль RAM высокого качества, то может быть будет возможно уменьшить одну из задержек, не влияя на стабильность компьютера. Многочисленные оверклокерские сайты в Интернете предлагают уйму документации об этом. Делайте это на свой страх и риск, но не говорите потом, что вас не предупреждали.
2.2.3 Перезарядка
Наиболее часто упускаемая тема при рассмотрении доступа к DRAM это перезарядка. Как было показано в разделе 2.1.2, ячейки DRAM нужно постоянно освежать. И это не происходит незаметно для остальной части системы. Когда строка перезаряжается (единица измерения здесь строка (см. [5]) хотя в [2] и другой литературе утверждается иное), доступ к ней невозможен. Исследование в [2] показывает, что "удивительно, но организация перезарядки DRAM может драматически влиять на производительность".
Согласно спецификации JEDEC (Joint Electron Device Engineering Council), каждая ячейка DRAM должна перезаряжаться каждые 64мс. Если массив DRAM имеет 8192 строк, это означает, что контроллер памяти должен посылать команду на перезарядку в среднем каждые 7.8125 микросекунд (эти команды могут быть поставлены в очередь и поэтому на практике максимальный интервал между двумя из них может быть больше). Управлять расписанием команд на перезарядку является обязанностью контроллера памяти. Модуль DRAM помнит адрес последней перезаряженной строки и автоматически увеличивает счетчик адреса для каждой новой команды.
Программист мало может влиять на перезарядку и моменты времени, когда эти команды даются. Но важно иметь эту часть жизненного цикла DRAM в виду, когда интерпретируешь измерения. Если важное слово должно быть прочитано из строки, а строка в этот момент перезаряжается, процессор может быть в простое довольно большое время. Как долго длится зарядка, зависит от модуля DRAM.
2.2.4 Типы памяти
Стоит потратить немного времени на описание существующих типов памяти и их ближайших последователей. Мы начнем с SDR (Single Data Rate) SDRAM, так как они являются базисом для DDR (Double Data Rate) SDRAM. SDR были очень простыми. Скорость ячеек памяти и передачи данных была одинаковой.

Рисунок 2.10: Операции SDR SDRAM
На рисунке 2.10 ячейка памяти DRAM может выдавать содержимое памяти с той же скоростью, с которой оно транспортируется по шине памяти. Если ячейка DRAM может работать на частоте 100МГц, то скорость передачи данных шиной будет 100Мб/с. Частота f для всех компонентов одинакова. Повышать пропускную способность чипа DRAM дорого, так как потребление энергии растет с ростом частоты. Учитывая огромное число массивов ячеек это невозможно дорого. {Энергопотребление = Динамическая емкость × Напряжение2 × Частота}. В действительности это ещё большая проблема, так как увеличение частоты также требует увеличения напряжения для поддержания стабильности системы. В DDR SDRAM (впоследствии называемая DDR1) пропускная способность была повышена без увеличения какой-либо из задействованных частот.

Рисунок 2.11: Операции DDR1 SDRAM
Различие между SDR и DDR1, как можно увидеть на рисунке 2.11 и понять из имени, в том, что за один цикл передается двойной объем данных. То есть чип DDR1 может передавать данные на увеличении и уменьшении уровня сигнала. Это иногда называют шиной с "двойной прокачкой". Чтобы сделать это возможным без увеличения частоты массива ячеек памяти применяется буфер. Буфер хранит по два бита на каждую линию данных. Для этого, в свою очередь требуется, чтобы массив ячеек на рисунке 2.7 имел шину данных из двух линий. Реализация этого тривиальна: нужно использовать одинаковый адрес колонки для двух ячеек DRAM и обращаться к ним параллельно. Изменения массива ячеек будут минимальными.
SDR DRAM были известны просто по их частоте (например, PC100 для 100МГц SDR). Чтобы улучшить звучание DDR1 DRAM маркетологи должны были изменить эту схему, так как частота не изменилась. Они приняли имя, которое содержит скорость передачи в байтах, которую поддерживает модуль DDR (он имеет шину шириной 64 бит):
100МГц × 64бит × 2 = 1600Мб/с
Следовательно, модуль DDR с частотой 100МГц называется PC1600. С 1600 > 100 все маркетинговые требования соблюдены - звучит намного лучше, хотя реальное улучшение только в два раза. {Я бы понял, если бы увеличили в два раза, а то получаются дутые числа.}

Рисунок 2.12: Операции DDR2 SDRAM
Чтобы получить от технологии ещё больше DDR2 включает ещё немного инноваций. Самое очевидное изменение, как можно видеть из рисунка 2.1 это удвоение частоты шины. Удвоение частоты означает удвоение пропускной способности. Так как удвоение частоты экономически неоправданно для массива ячеек, теперь требуется, чтобы буфер ввода/вывода получал по четыре бита за один цикл, которые он затем передает по шине. Это означает, что изменения в модуле DDR2 состоят в увеличении скорости буфера ввода/вывода DIMM. Это определенно возможно и не требует значительно больше энергии - это всего лишь один небольшой компонент, а не весь модуль. Имя, которое маркетологи придумали для DDR2, аналогично имени для DDR1, только в вычислении значения множитель два заменяется на четыре (теперь у нас шина с "четверной прокачкой"). Рисунок 2.13 показывает используемые сегодня имена модулей.
| Частота массива | Частота шины | Скорость данных | Имя (скорость) | Имя (FSB) |
|---|---|---|---|---|
| 133МГц | 266МГц | 4256Мб/с | PC2-4200 | DDR2-533 |
| 166МГц | 333МГц | 5312Мб/с | PC2-5300 | DDR2-667 |
| 200МГц | 400МГц | 6400Мб/с | PC2-6400 | DDR2-800 |
| 250МГц | 500МГц | 8000Мб/с | PC2-8000 | DDR2-1000 |
| 266МГц | 533МГц | 8512Мб/с | PC2-8500 | DDR2-1066 |
Рисунок 2.13: Имена модулей DDR2
В названии есть ещё один трюк. Скорость FSB, используемая ЦПУ, материнской платой и модулем DRAM выражена через "эффективную" частоту. То есть она умножается на 2 из-за того, что передача данных идет при повышении и понижении уровня сигнала тактового генератора и число увеличивается. Итак, модуль 133МГц с шиной 266МГц имеет "частоту" FSB 533МГц.
Спецификация DDR3 (настоящей, а не GDDR3, используемой в графических картах) подразумевает дальнейшие изменения, продолжающие логику перехода к DDR2. Напряжение будет понижено с 1.8В для DDR2 до 1.5В для DDR3. Так как энергопотребление пропорционально квадрату напряжения это одно дает 30% улучшения. Добавьте к этому уменьшение микросхемы и другие электрические улучшения, и DDR3 может на той же частоте потреблять половину энергии. А на большей частоте обходиться таким же количеством. Или можно вдвое увеличить емкость для такого же количества выделения тепла.
Массив ячеек модуля DDR3 будет работать на четверти скорости внешней шины, что потребует восьмибитного буфера ввода/вывода, больше по сравнению с четырехбитным в DDR2. На рисунке 2.14 изображена схема.

Рисунок 2.14: Операции DDR3 SDRAM
Скорее всего, поначалу модули DDR3 будут иметь немного большую задержку CAS чем DDR2, потому что DDR2 более зрелая технология. Поэтому использовать DDR3 будет иметь смысл только на более высоких частотах, чем те, которые достижимы для DDR2, или когда пропускная способность важнее, чем задержка. Уже ходят разговоры о модулях с напряжением 1.3В, у которых будет та же задержка CAS, как и у DDR2. В любом случае, возможность достичь более высоких скоростей из-за более быстрых шин перевесит увеличение задержки.
Одна возможная проблема с DDR3 состоит в том, что на скорости 1600Мб/с и выше, число модулей на канал может быть сокращено до одного. В ранних версиях это ограничение присутствовало для всех частот, так что можно надеяться, что со временем оно будет снято для всех частот. Иначе емкость систем будет жестко ограничена.
Рисунок 2.15 показывает ожидаемые имена модулей DDR3. JEDEC к этому времени одобрило первые четыре типа. Учитывая, что 45-нанометровые процессоры Intel имеют скорость FSB 1600Мб/с, необходимо иметь 1866Мб/с для рынка оверклокеров. Скорее всего, мы увидим это ближе к концу жизненного цикла DDR3.
| Частота массива | Частота шины | Скорость данных | Имя (скорость) | Имя (FSB) |
|---|---|---|---|---|
| 100МГц | 400МГц | 6400Мб/с | PC3-6400 | DDR3-800 |
| 133МГц | 533МГц | 8512Мб/с | PC3-8500 | DDR3-1066 |
| 166МГц | 667МГц | 10667Мб/с | PC3-10667 | DDR3-1333 |
| 200МГц | 800МГц | 12800Мб/с | PC3-12800 | DDR3-1600 |
| 233МГц | 933МГц | 14933Мб/с | PC3-14900 | DDR3-1866 |
Рисунок 2.15: Имена модулей DDR3
Вся память DDR имеет одну проблему - увеличение частоты шины делает трудным создание параллельных шин данных. Модуль DDR2 имеет 240 контактов. Все соединения до контактов данных и адреса должны быть сделаны так, чтобы они имели приблизительно одинаковую длину. Ещё более проблематично то, что когда на одной шине несколько модулей DDR, сигналы становятся все более и более искаженными для каждого дополнительного модуля. Спецификация DDR2 разрешает использовать только два модуля на одной шине (канале), DDR3 - только один модуль на высоких частотах. С 240 контактами на канал, один Северный мост не может хорошо управлять более чем двумя каналами. В качестве альтернативы можно использовать внешние контроллеры памяти (см. рисунок 2.2), но это очень дорого.
Все это означает, что материнские платы массовых компьютеров могут иметь не более четырех модулей DDR2 или DDR3. Это жестко ограничивает количество памяти, которое может иметь система. Даже старые 32-битные процессоры IA-32 поддерживали до 64Гб RAM, и потребность в большом количестве памяти растет даже для домашних систем, поэтому надо что-то делать.
Одно решение - это добавлять контролеры памяти в каждый процессор, как показано в начале этой главы. AMD делает это на линейке процессоров Opteron, и Intel будет делать в технологии CSI. Это может помочь до тех пор, пока количество памяти, которое способен использовать процессор, может быть присоединено к каждому процессору. В некоторых ситуациях это не так и этот подход приводит к архитектуре NUMA с её негативными эффектами. Для некоторых ситуаций нужно вообще другое решение.
Решение Intel для больших серверных машин, по крайней мере на ближайшие годы, называется Fully Buffered DRAM (FB-DRAM). Модули FB-DRAM используют те же компоненты, что и сегодняшние модули DDR2, что делает их относительно дешевыми в производстве. Разница в соединении с контроллером памяти. Вместо параллельной шины данных FB-DRAM использует последовательную шину (то же было у Rambus DRAM и у SATA, последователе PATA, и у PCI Express после PCI/AGP). Последовательной шиной можно управлять на значительно более высокой частоте, преодолевая негативный эффект сериализации, и даже увеличивая пропускную способность. Основные эффекты от использования последовательной шины:
- можно использовать больше модулей на одном канале,
- можно использовать больше каналов на одном Северном мосте/контроллере памяти,
- последовательная шина является полнодуплексной (две линии).
Модуль FB-DRAM имеет только 69 контактов, вместо 240 у DDR2. Использовать вместе несколько модулей FB-DRAM намного легче, так как электрическими эффектами такой шины легче управлять. Спецификация FB-DRAM позволяет использовать до 8 модулей на один канал.
Учитывая требования к соединениям, предъявляемые двухканальным Северным мостом, теперь возможно управлять шестью каналами FB-DRAM с меньшим количеством контактов: 2×240 против 6×69. Путь на плате до каждого канала также намного проще, что может помочь снизить цену материнских плат.
Параллельные шины с полным дуплексом слишком дороги для традиционных модулей DRAM - очень затратно удваивать количество линий. С последовательными линиями (даже если они разностные, как требует FB-DRAM) это не так, поэтому последовательная шина сделана полностью дуплексной, что означает, в некоторых ситуациях, что пропускная способность удваивается только из-за этого. Но это не единственный случай, когда параллелизм используется для увеличения пропускной способности. Так как контроллер FB-DRAM может обслуживать до шести каналов одновременно, пропускная способность при использовании FB-DRAM может быть увеличена даже для систем с небольшим количеством RAM. Там где система на DDR2 с четырьмя модулями имеет два канала, та же емкость может обслуживаться через четыре канала обычным контроллером FB-DRAM. Реальная пропускная способность последовательной шины зависит от того, какие чипы DDR2 (или DDR3) используются в модулях FB-DRAM.
Мы можем суммировать преимущества таким образом:
| DDR2 | FB-DRAM | |
|---|---|---|
| Контакты | 240 | 69 |
| Каналы | 2 | 6 |
| DIMM/канал | 2 | 8 |
| Max памяти | 16Гб | 192Гб |
| Скорость | ~10Гб/с | ~40Гб/с |
Есть отрицательные стороны FB-DRAM при использовании нескольких DIMM на одном канале. Сигнал задерживается, хотя и минимально для каждой DIMM в цепи, что означает увеличение задержки. Но для того же количества памяти на той же частоте FB-DRAM всегда будет быстрее, чем DDR2 и DDR3, так как на канал нужна только одна DIMM. Для систем с большим объемом памяти у DDR просто нет решения на массовых компонентах.
2.2.5 Выводы
Этот раздел должен был показать, что доступ к DRAM не может быть сколь угодно быстрым процессом. По крайней мере по сравнению со скоростью процессора и скоростью доступа процессора к регистрам и кэшу. Важно держать в уме различия между частотами ЦПУ и памяти. Процессор Intel Core 2 имеет частоту 2.933ГГц, и системная шина с частотой 1.066ГГц будут иметь отношение тактовых частот 11:1 (заметьте, что данные на шину подаются вчетверо быстрее её частоты). Простой в один цикл памяти означает простой 11 циклов процессора. В большинстве машин реально используются более медленные DRAM, что ещё более увеличивает задержку. Держите эти цифры в уме, когда мы будем говорить о простоях в последующих главах.
Графики для команд чтения показывают, что модули DRAM способны передавать данные с большой и устойчивой скоростью. Целые строки DRAM могут передаваться без единой задержки. Шина данных может оставаться на 100% загруженной. Для модулей DDR это означает, что в каждом цикле передается два 64-битных слова. Для модулей DDR2-800 на двух каналах это 12.8Гб/с.
Но доступ к DRAM не всегда последователен, если конечно он не специально так организован. Используются отдаленные друг от друга участки памяти, что означает, что неизбежно использование предварительной зарядки и новых сигналов RAS. Вот тогда все замедляется и модулям DRAM нужна помощь. Чем скорее случится предварительная зарядка и послан сигнал RAS, тем меньше расходы на использование новой строки.
Чтобы сократить простои и создать большее перекрытие по времени операций их вызывающих, используется аппаратная и программная предварительная выборка (см. раздел 6.3). Она также помогает переместить операции с памятью во времени так, что достаточно будет задействовать меньшее количество ресурсов позднее, перед тем как данные непосредственно понадобятся. Нередко возникает проблема, когда данные, произведенные в одном раунде нужно сохранить, а данные, необходимые в следующем раунде нужно прочитать. Перемещая чтение во времени, мы добьемся того, что операции чтения и записи не нужно будет делать одновременно.
2.3 Другие пользователи основной памяти
Кроме процессоров есть другие компоненты системы, имеющие доступ к основной памяти. Высокопроизводительные карты, например сетевые и контроллеры накопителей не могут позволить себе пропускать все используемые ими данные через процессор. Вместо этого они читают и записывают данные непосредственно в основную память (Direct Memory Access, DMA). На рисунке 2.1 мы можем видеть, что эти карты могут через Южный и Северный мосты обмениваться данными непосредственно с памятью. Другим шинам, например USB, также требуется пропускная способность FSB, хотя они и не используют DMA, так как Южный мост соединен с Северным также через FSB.
Хотя DMA определенно полезен, он подразумевает ещё большую конкуренцию за пропускную способность FSB. Во время высокой активности трафика DMA процессор может простаивать дольше обычного, ожидая данных от основной памяти. Этого можно избежать на соответствующем оборудовании. С архитектурой как на рисунке 2.3 вычисления используют память на узлах, на которые DMA не влияет. Также возможно присоединить Южный мост к каждому узлу, равномерно распределяя загрузку FSB между всеми узлами. Есть множество возможностей. В главе 6 мы обсудим техники и программные интерфейсы, которые позволят делать возможные в программном обеспечении улучшения.
И в конце нужно упомянуть, что некоторые дешевые системы содержат подсистемы графики без выделенной видеопамяти. Такие системы используют в качестве видеопамяти части основной памяти. Так как доступ к видеопамяти происходит часто (для дисплея размера 1024x76 с 16-битным цветом на 60Гц мы говорим о 94Мб/с) и системная память, в отличие от видеопамяти не имеет двух портов, это может сильно влиять на производительность системы и особенно на задержку. Когда производительность является приоритетом, лучше игнорировать такие системы. От них только больше хлопот, чем пользы. Люди, покупающие такие машины должны осознавать, что они не получат лучшей производительности.
Ссылки к разделу 2
[1] Wikipedia. Static random access memory. http://en.wikipedia.org/wiki/Static_Random_Access_Memory, 2006.
[2] Vinodh Cuppu, Bruce Jacob, Brian Davis and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133--1153, 2001.
[3] Stokes, Jon ``Hannibal''. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM. http://arstechnica.com/paedia/r/ram_guide/ram_guide.part2-1.html, 2004.
[4] Dowler, M. Introduction to DDR-2: The DDR Memory Replacement. http://www.pcstats.com/articleview.cfm?articleID=1573, 2004.
[5] Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003.
3 Кэш-память процессора
Процессоры сегодня гораздо сложнее, чем они были всего лишь 25 лет назад. В то время частота ядра процессора была равна приблизительно частоте шины памяти. Доступ к памяти был лишь чуть-чуть медленнее, чем доступ к регистрам. Но в начале 90-х годов это все резко изменилось, когда разработчики процессоров увеличили частоту ядра процессора, а частоту шины памяти и производительность чипов памяти не удалось увеличить пропорционально. Как рассказывается в предыдущем разделе, это не связано с тем, что нельзя создать более быструю оперативную память. Сделать это можно, но это не экономично. Оперативная память, работающая с той же скоростью, что ядра современных процессоров, будет на несколько порядков дороже, чем любая динамической память.
Если выбирать между машиной с очень маленькой и очень быстрой оперативной памятью и машиной с большим количеством не такой быстрой оперативной памятью, второй вариант всегда будет более выигрышным в случаях, когда размер рабочего набора данных будет превышать размер небольшой оперативной памяти и потребуются затраты на доступ к вторичным хранилищам данных, таким как жесткие диски. Проблема здесь заключается в скорости доступа к вторичным хранилищам данных, которыми, как правило, являются жесткие диски, и которые потребуется использовать для подкачки части рабочего набора. Доступ к таким дискам на порядки медленнее, чем даже доступ к памяти DRAM.
К счастью, это не тот случай, когда либо все, либо ничего. Компьютер в дополнение к большому объему памяти DRAM может иметь небольшое количество высокоскоростной памяти SRAM. Одной из возможных реализаций могло бы быть выделение определенной области адресного пространства процессора как содержащей память SRAM, а для памяти DRAM отвести все остальное. В этом случае задачей операционной могло бы быть оптимальное распределение данных, позволяющее использовать память SRAM. В принципе, память SRAM в подобной ситуации используется в качестве расширения набора регистров процессора.
Хотя такая реализация возможна, она нежизнеспособна. Если игнорировать проблему отображения физических ресурсов такой памяти SRAM в виртуальные адресные пространства процессов (что само по себе ужасно трудно), то при таком подходе потребуется, чтобы в каждом процессе с помощью программного обеспечения выполнялось администрирование распределения этой области памяти. Размер этой области памяти может варьироваться от процессора к процессору (поскольку процессоры имеют различное количество дорогой памяти SRAM). Каждый модуль, который входит в состав программы, будет претендовать на свою долю в быстрой памяти, из-за чего возникнут дополнительные расходы на синхронизацию запросов. В общем, выгоды, полученные от использования быстрой памяти, будут полностью съедены накладными расходами на управление ресурсами.
Поэтому вместо того, чтобы использовать память SRAM под управлением операционной системы или пользователя, она становится ресурсом, использование и администрирование которого осуществляется процессорами так, что это не видно ни операционной системе, ни пользователю. В этом режиме память SRAM используется для создания временных копий (другими словами, кэширования) данных, которые находятся в основной памяти, но которые, возможно, совсем скоро будут использоваться процессором. Это возможно, поскольку коду программы и данным свойственны пространственная и временная компактность. Это значит, что если рассматривать короткие промежутки времени, существует достаточно большая вероятность, что тот же самый код или данные будут использованы повторно. В случае кода, это означает, что в коде, скорее всего, есть много циклов, так что один и тот же код запускается на выполнение снова и снова (идеальный случай пространственной компактности - spatial locality). Доступ к данным также в идеале ограничен небольшим пространством. Даже если участки памяти, используемые в течение коротких периодов времени, расположены не рядом друг с другом, есть высокая вероятность того, что в скором времени будут повторно использованы те же самые данные (временная компактность - temporal locality). Для кода примером является цикл, в котором осуществляется вызов функции, а функция находится в другом месте адресного пространства. Эта функция может находиться в памяти далеко от вызова, но вызовы этой функции будут близки во времени. Для данных это означает, что некоторое количество памяти, используемое за один раз (размером в рабочий набор данных) в идеале ограничено, но участки этой используемой память из-за случайного характера доступа к оперативной памяти, могут располагаться далеко друг от друга. Реализация существования этой компактности является ключом к концепции кэш-памяти процессора в том виде, как мы используем ее сегодня.
Простой подсчет может показать, насколько теоретически может быть эффективна кэш-память. Предположим, что на доступ к оперативной памяти тратится 200 циклов, а на доступ к кэш-памяти - 15 циклов. Тогда, если в коде 100 раз используются 100 элементов данных, то в случае, если кэш-память отсутствует, на операции с памятью будет потрачено 2000000 циклов и, если данные находятся в кэше, на это будет потрачено только 168 500 циклов. Это улучшение составляет 91,5%.
Размер памяти SRAM, используемой для кэша, во много раз меньше, чем основная память. По опыту автора, имевшего дело рабочими станциями, имеющим кэш-память процессора, размер кэша всегда приблизительно равен 1/1000-ой от размера оперативной памяти (сегодня: 4 Мб кэш-памяти и 4 Гб оперативной памяти). Это само по себе не является проблемой. Если размер рабочего набора (набора данных, с которым в текущий момент осуществляется работа) меньше, чем размер кэш-памяти, то проблем нет. Но в компьютеры большое количество памяти не добавляют без всяких причин. Рабочий набор непременно больше, чем кэш-память. Это особенно актуально в системах, где запускаются несколько процессов и размер рабочего набора равен сумме размеров рабочих наборов всех отдельных процессов и ядра.
Все, что нужно, чтобы использовать кэш-память ограниченного размера, это набор хороших стратегий, которые определяют, что в любой заданный момент времени должно кешироваться. Поскольку не все данные рабочего набора используется одновременно, мы можем на время заменять некоторые данные, находящиеся в кэш-памяти, другими данными. И, возможно, это удастся сделать раньше, чем данные станут, на самом деле, необходимы. Такая предварительная загрузка позволит скрыть некоторые затраты на доступ к основной памяти, поскольку загрузка происходит асинхронно относительно выполнения программы. Все эти методы и многое другое можно использовать для того, чтобы кэш-память казалась больше, чем она есть на самом деле. Мы обсудим их в разделе 3.3. Использование всех этих методов позволит программисту помочь работе процессора. Как это сделать, мы обсудим в разделе 6.
3.1 Кэш процессора — общая картина
Прежде, чем погружаться в технические детали реализации кэш-памяти процессора, для некоторых читателей может быть полезным сначала рассмотреть некоторые особенности того, как кэш-память вписывается в "общую картину" современной компьютерной системы.

Рис 3.1: Минимальная конфигурация кэш-памяти
На рис.3.1 показана минимальная конфигурация кэш-памяти. Она соответствует архитектуре, которую можно найти в ранних системах со встроенной кэш-памятью процессора. Здесь ядро процессора уже не напрямую связано с основной памятью. {В самых ранних системах кэш-память была присоединена к системной шине точно также, как процессор и оперативная память. Это больше смахивало на некотрое приспособление, а не на реальное решение}. Загрузка всех данных и их запоминание в памяти должны осуществляться через кэш-память. Соединением между ядром процессора и кэш-памятью представляет собой специальное быстрое соединение. В упрощенном представлении оперативная память и кэш-память подключаются к системной шине, которая также может использоваться для подключения к другим компонентам системы. Мы будем называть системную шину "шиной FSB", т. е. так, как она называется сегодня, смотрите раздел 2.2. В данном разделе мы будем игнорировать наличие северного моста Northbridge; предполагается, что он используется для того, чтобы облегчить обмен данными между процессором (процессорами) и основной памятью.
Несмотря на то, что в компьютерах в течение последних нескольких десятилетий используется архитектура фон Неймана, опыт показывает, что использование отдельной кэш-памяти для кода и для данных дает преимущество. Фирма Intel с 1993 года использует отдельную кэш-память для кода и для данных и не намеревается от этого отказываться. Области памяти, используемые под код и под данные, в значительной мере независимы друг от друга и, следовательно, отдельная кэш-память будет работать лучше. В последние годы появилась еще одна особенность: в наиболее распространенных процессорах шаг декодирования инструкций выполняется медленно; кэширование декодированных инструкций может ускорить выполнение, особенно в тех случаях, когда конвейер пуст из-за неправильного предсказания инструкций или из-за невозможности выполнить само предсказание.
Вскоре после добавления кэш-памяти система стала еще более сложной. Снова увеличилась разница по скорости между кэш-памятью и основной памятью, и из-за этого был добавлен еще один уровень кэш-памяти, который был больше по размеру, но работал медленнее, чем кэш-память первого уровня. Просто увеличить размер кэш-памяти первого уровня не удалось по экономическим причинам. Сегодня есть даже машины, в которых регулярно используется три уровнями кэш-памяти. Система с таким процессором показана на рис.3.2. Поскольку количество ядер в одном процессоре увеличивается, в будущем количество уровней кэш-памяти может увеличиться еще больше.

Рис.3.2: Процессор с тремя уровнями кэш-памяти
На рис.3.2 показаны три уровня кэш-памяти и приведены обозначения, которыми мы будем пользоваться в оставшейся части статьи. L1d является кэш-памятью 1-го уровня для данных, L1i является кэш-памятью 1-го уровня для инструкций и т.д. Заметьте, что это только схема; поток данных на самом деле может на пути от ядра к оперативной памяти не проходить через кэш-память высокого уровня. Разработчикам процессоров предоставлено достаточно свободы в проектирования интерфейса кэш-памяти. Для программистов эти проектные решения невидимы.
Кроме того, у нас есть процессоры, у которых есть несколько ядер, и каждое ядро может иметь несколько "потоков" ("threads"). Разница между ядром и потоком в том, что в отдельных ядрах имеются отдельные копии (почти {в более ранних многоядерных процессорах даже имелась отдельная кэш-память второго и третьего уровня}) всех аппаратных ресурсов. Ядра в случае, если они не используют одни те же ресурсы, например, если одни одновременно к внешней шине, могут работать полностью самостоятельно. Потоки, с другой стороны, разделяют почти все ресурсы процессора. Фирма Intel реализует потоки так, что для потоков отдельно реализованы только регистры, причем и здесь есть ограничения, поскольку некоторые регистры являются общими. Поэтому "общая картина" современного процессора будет выглядеть так, как это показано на рис.3.3.

Рис.3.3: Много процессоров, много ядер, много потоков
На этом рисунке у нас есть два процессора, каждый с двумя ядрами, каждое из которых имеет два потока. Потоки совместно используют кэш-память 1-го уровня. В ядрах (показаны темно-серым цветом) есть отдельная кэш-память 1-го уровня. Все ядра процессора совместно используют кэш-память более высокого уровня. Два процессора (два больших прямоугольника, показанных светло серым цветом), конечно, не разделяют (не используют одновременно --- прим.пер.) какую-либо кэш-память. Все это будет важно в случаях, когда речь пойдет о вилянии кэш-памяти в приложениях с несколькими процессами или несколькими потоками.
3.2 Как работает кэш-память высокого уровня
Чтобы понять, каковы затраты и экономия от использования кэш-памяти, мы должны объединить вместе знания об архитектуре машины и об оперативной памяти, взятые из раздела 2, со знаниями о структуре кэш-памяти, описанной в предыдущем разделе.
По умолчанию все данные, которые читаются или записываются ядрами процессора, хранятся в в кэш-памяти. Есть области памяти, которые кэшировать нельзя, но это то, о чем должны беспокоиться разработчики ОС; это невидно прикладному программисту. Есть также инструкции, которые позволяют программисту принудительно обходить определенную кэш-память. Это будет обсуждаться в разделе 6.
Если процессору требуется некоторое слово данных, то поиск сначала осуществляется в кэш-памяти. Очевидно, что в кэш-памяти не может находиться содержимое всей оперативной памяти (в противном случае, нам не нужна была бы кэш-память), но, поскольку кэшируются адреса всей памяти, каждая запись в кэш-памяти помечается тегом с адресом слова данных основной памяти. Таким образом, при запросе на чтение или запись адрес можно искать в кэш-памяти по совпадению тега. Адрес в этом контексте может быть виртуальным, либо физическим адресом - все зависит от реализации кэш-памяти.
Поскольку в дополнение к фактически используемой памяти под тег требуется еще место, неэффективно использовать слова в качестве средства поиска данных в кэш-памяти. Для 32-разрядных слов на машине с архитектурой x86 для самого тэга, возможно, потребуется 32 бита памяти или более. Кроме того, поскольку пространственная компактность является одним из принципов, на которых основывается использование кэш-памяти, было бы плохо не принимать это во внимание. Поскольку есть вероятность, что фрагменты памяти, расположенные по соседству, могут использоваться совместно, они должны загружаться в кэш память вместе. Вспомните также о том, что мы узнали в разделе 2.2.1: использование модулей оперативной памяти будет еще более эффективным, если в них перемещаются по рядам подряд сразу много слов данных, причем без подачи нового сигнала CAS и даже сигнала RAS. Таким образом, данные хранятся в кэш-памяти не в виде отдельных слов, а, наоборот, в виде "строк", состоящих из нескольких смежных слов. В ранних вариантах кэш-памяти длина этих строк была 32 байта, теперь нормой является 64 байта. Если ширина шины памяти равна 64 бита, то это значит, что передача одной кэш-строки осуществляется за 8 действий. В DDR этот режим транспортировки данных очень эффективен.
Когда содержимое памяти необходимо процессору, то вся кэш-строка загружается в кэш-память L1d. Адрес памяти для каждой кэш-строки вычисляется с помощью маскирования значения адреса, зависящего от размера кэш-строки. Для 64 байтовой кэш-строки это означает, что обнуляются младшие 6 битов. Эти биты используются как смещение в кэш-строке. Оставшиеся биты в некоторых случаях используется для поиска кэш-строки в кэш-памяти, а также в качестве тега. На практике значение адреса делится на три части. Для 32-битного адреса это может выглядеть следующим образом:

Если размер кэш-строки равен 2O, то младшие O битов будут использоваться как смещение в кэш-строке. Следующие S битов рассматриваются как "индекс кэш-набора" ("cache set"). Мы вскоре подробнее рассмотрим, почему для кэш-строк используются кэш-наборы, а не один непрерывный участок. На данный момент достаточно понимать, что есть 2S кэш-наборов, содержащих кэш-строки. В результате остается 32 - S - O = T битов, из которых формируется тег. Эти Т битов представляют собой значение, ассоциированное (связанное) с каждой отдельной кэш-строкой и используемое для того, чтобы можно было различать все алиасы {известно, что все кэш-строки с одинаковым значением части S адреса имеют один и тот же алиас}, которые кэшированы в одном и том же кэш-наборе. Биты S используются для адресации кэш-набора и их не нужно сохранять, поскольку они одинаковы для всех кэш-строк в одном кэш-наборе.
Когда инструкция модифицирует содержимое памяти, процессор должен, прежде всего, загрузить кэш-строку, поскольку инструкция не изменяет сразу всю кэш-строку (исключение из правила: запись с объединением так, как это описано в разделе 6.1). Таким образом, будет загружено содержимое кэш-строки, которое было до операции записи. В кэш-памяти нельзя хранить части кэш-строк. Кэш-строка, в которую была сделана запись и которая не была обратно записана в в основную память, называют "грязной" ("dirty"). Как только будет выполнена запись в память, флаг, указывающий на то, что строка грязная, сбрасывается.
Для того, чтобы в кэш-память можно было загрузить новые данные, почти всегда сначала необходимо освободить место. При удалении из кэш памяти L1d кэш-строка перемещается вниз --- в кэш-память L2 (в которой используется тот же самый размер кэш-строки). Конечно, это означает, что в кэш-памяти L2 должно быть место. А это, в свою очередь, может быть причиной перемещения содержимого в кэш-память L3 и, в конце концов, в основную память. Каждое последующее выталкивание содержимого из кэш-памяти будет все более дорогостоящим. То, что здесь описано, является моделью эксклюзивной или исключающей кэш-памятью (exclusive cache), предпочтение которой отдается в современных процессорах AMD и VIA. В Intel реализуется инклюзивная или включающая кэш-память (inclusive caches) {Это обобщение не вполне корректно. Некоторые варианты кэш-памяти являются исключающими, а некоторые включающие варианты кэш-памяти имеют свойства исключающей кэш-памяти}, в котором каждая кэш-строка, имеющаяся в кэш-памяти L1d, также присутвует в кэш-памяти L2. Поэтому удаление из кэш-памяти L1d происходит гораздо быстрее. При достаточном размере кэш-памяти L2 накладные расходы, вызванные хранением содержимого в двух местах, будут минимальными, а при выталкивании содержимого из кеш-памяти дадут выигрыш. Возможным преимуществом исключающей кэш-памяти в том, что загрузка новой кэш-строки выполняется только в кэш-память L1d, а не в L2, что может происходить быстрее.
Процессоры сами управляют кэш-памятью, причем наиболее удобным для них образом и до тех пор, пока не изменится модель памяти, определяемая архитектурой процессора. Например, отлично, когда у процессора есть возможность совсем мало или вообще не использовать шину памяти и с упреждением записывать измененные кэш-строки обратно в основную память. Большое количество вариантов реализации кэш-памяти имеется для процессоров с архитектурой x86 и x86-64, причем как для процессоров различных производителей, так и для моделей одного и того же производителя.
В системах с симметричной многопроцессорной архитектурой (SMP) кэш-память отдельных процессоров не может работать независимо друг от друга. В любой момент времени все процессоры должны видеть одно и то же содержимое памяти. Поддержка такого единообразного содержимого памяти называется "когерентностью кэш-памяти". Если процессор видит свою собственную кэш-память и основную память, он не должен видеть содержимое грязных кэш-строк в других процессорах. Реализация прямого доступа к кэш-памяти одного процессора из другого процессора является чрезвычайно дорогой и чрезвычайно узкой по производительности. Вместо этого, процессоры просто узнают, когда другой процессор хочет прочитать или записать определенную кэш-строку.
Если обнаружен доступ на запись и у процессора в его кэш-памяти есть просто копия кэш-строки, то эта кэш-строка помечается как неверная. Будущие обращения к ней потребуют ее перезагрузки. Обратите внимание, что доступ на чтение из другого процессора не потребует помечать ее как неверную, так что вполне может быть сразу несколько чистых копий кэш-строки.
В более сложных случаях реализации кэш-памяти могут возникать другие ситуации. Если кэш-строка, которую хочет прочитать или в которую хочет сделать запись другой процессор, помечена в кэш-памяти первого процессора как грязная, то потребуется совсем другая последовательность действий. В этом случае содержимое основной памяти будет рассматриваться как устаревшее и вместо него процессор, делающий запрос, должен получить содержимое кэш-строки от первого процессора. Первый процессор с помощью перехвата обращения обнаруживает эту ситуацию и автоматически отправляет данные процессору, сделавшему запрос. Это действие выполняется в обход основной памяти, хотя в некоторых реализациях предполагается, контроллер памяти должен отследить такую прямую передачу данных и сохранить в основной памяти содержимое кэш-строки. Если обнаружен доступ на запись, то первый процессор должен пометить кэш-строку как неверную.
Со временем были разработаны несколько протоколов когерентности кэш-памяти. Самым важным является протокол MESI, который мы представим в разделе 3.3.4. Все это можно подытожить в виде нескольких простых правил:
- Грязные кэш-строки не присутствуют в кэш-памяти любого другого процессора.
- Чистые копии одной и той же кэш-строки могут находиться в кэш-памяти сколь угодно большого количества процессоров.
Если соблюдать эти правила, то процессоры могут эффективно использовать свою кэш-память даже в многопроцессорных системах. Все, что процессоры должны делать, это контролировать доступ друг-друга на запись и сравнить адреса с теми, что хранятся в их локальной кэш-памяти. В следующем разделе мы расскажем о деталях реализации и, в частности, о расходах на реализацию.
Наконец, мы должны иметь общее представление о расходах, связанных попаданиями и промахами, возникающими при использовании кэш-памяти. Ниже приведены цифры для процессора Intel Pentium M:
| Где | Циклы |
| Регистр | <= 1 |
| Кэш-память L1d | ~3 |
| Кэш-память L2 | ~14 |
| Основная память | ~240 |
Это фактическое время доступа, измеренное в циклах процессора. Интересно отметить, что для кэш-памяти L2, реализованной в виде микросхемы, основная часть (возможно, даже большая) времени доступа связана с передачей сигналов по проводникам. Это физическое ограничение, которое может только ухудшиться по мере увеличения размера кэш-памяти. Эти цифры могут улучшиться только при смене технологического процесса (например, в линейке Intel переход от технологии 60 нм для Merom на технологию 45 нм для Penryn).
Числа в таблице выглядят большими, но, к счастью, указанные расходы происходят не всегда при каждом попадании или промахе, связанными с кэш-памятью. Некоторые затраты могут быть скрытыми. Во всех современных процессорах используются внутренние конвейеры, в которых происходит декодирование и подготовка инструкций к исполнению и которые имеют различную длину. В случае, если передача значения осуществляется в регистр, то часть накладных расходов, связанных с памятью (или кэш-памятью), не будет. Если операция загрузки в память может быть запущена в конвейере на достаточно раннем этапе, то она может выполняться параллельно с другими операциями и общие затраты, связанные с загрузкой, могут оказаться скрытыми. Это часто случается в кэш-памяти L1d, а для некоторых процессоров с длинными конвейерами также и в кэш-памяти L2.
Есть много причин, из-за которых нельзя начинать чтение из памяти на достаточно раннем этапе. Это может быть просто отсутствие достаточного количества ресурсов, необходимых для доступа к памяти, или может так случиться, что окончательный адрес загрузки станет доступен позднее в виде результата выполнения другой команды. В этом случае расходы на загрузку (полностью) скрыть не удастся.
Когда выполняется операция записи, процессор не обязан ждать, пока значение будет надежно сохранено в памяти. Если значение, запоминаемое в памяти, не будет сказываться на выполнении следующих инструкций, то нет причин, которые бы мешали процессору продолжать выполнение дальше. Он может достаточно рано начать выполнение следующей команды. Если используются теневые регистры (shadow registers), в которых могут находиться значения, уже недоступные в обычном регистре, процессор даже может изменять значение, которое должно быть запомнено с помощью еще не полностью выполненной операции записи.

Рис.3.4: Время доступа для операций записи, выполняемых случайным образом
Иллюстрация влияния использования кэш-памяти приведена на рис.3.4. Далее мы расскажем о программе, которая генерирует данные; это простая имитация программы, случайным образом обращающаяся к некоторым областям памяти, которые можно переконфигурировать. Каждый элемент данных имеет фиксированный размер. Количество элементов зависит от размера выбранного рабочего набора. По оси Y указывается среднее число циклов процессора, необходимое для обработки одного элемента; обратите внимание, что шкала оси Y логарифмическая. В диаграммах подобного вида то же самое касается и оси X. Размер рабочего набора всегда указывается в виде степеней числа 2.
На графике показано три различных участка. Это не удивительно: в конкретном процессоре есть кэш-память L1d и L2 , но нет кэш-памяти L3. Исходя из некоторого опыта, мы можем сделать вывод, что размер кэш-памяти L1d равен 213 байтов, а размер кэш-памяти L2 равен 220 байтов. Если весь рабочий набор помещается в кэш-память L1d, то количество циклов на одну операцию для каждого элемента меньше 10. Как только он превышает размер кэш-памяти L1d, процессор будет загружать данные из кэш-памяти L2 и среднее время возрастет примерно до 28. Как только кэш-памяти L2 станет недостаточно, затрачиваемое время резко увеличится до 480 циклов и более. Это время, в течение которого большинству операций придется загружать данные из основной памяти. И хуже того: поскольку данные изменяются, грязные кэш-строки должны также записываться обратно в память.
Этот график должен стать достаточно побудительным мотивом для того, чтобы изучать те способы кодирования, которые помогают улучшить использование кэша. Здесь мы говорим не о каких-то нескольких ничтожных процентах; здесь речь идет об иногда возможных улучшениях на целые порядки. В разделе 6 мы рассмотрим способы, которые позволяют писать более эффективный код. В следующем разделе мы перейдем к подробностям реализации кэш-памяти процессоров. Знать об этом хорошо, но эти знания не являются необходимыми для изучения остальной части статьи. Так что этот раздел можно пропустить.
3.3 Подробности реализации кэш-памяти процессора
Разработчики кэш-памяти столкнулись с проблемой, состоящей в том, что потенциально в кэш-памяти может оказаться любая ячейка огромной основной памяти. Если рабочий набор данных, используемых в программе, достаточно большой, то это означает, что за каждое место в кэш-памяти будут соревноваться многие фрагменты основной памяти. Как ранее уже сообщалось, нередко соотношение между кэш-памятью и основной памятью составляет 1 к 1000.
3.3.1 Ассоциативность
Можно было бы реализовать кэш-память, в которой каждая кэш-строка может хранить копию любой ячейки памяти. Это называется полностью ассоциативной кэш-памятью (fully associative cache). Чтобы получить доступ к кэш-строке, ядро процессора должно было бы сравнить теги всех до единой кэш-строк с тегом запрашиваемого адреса. Тег должен будет хранить весь адрес, который не будет указываться смещение в кэш-строке (это означает, что значение S, показанное на рисунке в разделе 3.2, будет равно нулю).
Есть кэш-память, которая реализована подобным образом, но взглянуть на размеры кэш-памяти L2, используемой в настоящее время, то видно, что это непрактично. Учтите, что 4 Мб кэш-памяти с кэш-строками размером в 64Б должна иметь 65 536 записей. Чтобы получить адекватную производительность, логические схемы кэш-памяти должны быть в состоянии в течение нескольких циклов выбрать из всех этих записей ту, которая соответствует заданному тегу. Затраты на реализацию такой схемы будут огромными.
Рис.3.5: Схематическое изображение полностью ассоциативной кэш-памяти
Для каждой кэш-строки требуется, чтобы компаратор выполнил сравнение тега большого размера (заметьте, S равно нулю). Буква, стоящая рядом с каждым соединением, обозначает ширину соединения в битах. Если ничего не указано, то ширина соединения равна одному биту. Каждый компаратор должен сравнивать два значения, ширина каждого из которых равна Т бит. Затем, исходя из результата, должно выбираться и стать доступным содержимое соответствующей кэш-строки. Для этого потребуется объединить столько наборов линий данных О, сколько есть сегментов кэш-памяти (cache buckets). Число транзисторов, необходимых для реализации одного компаратора будет большим в частности из-за того, что компаратор должен работать очень быстро. Итеративный компаратор использовать нельзя. Единственный способ сэкономить на количестве компараторов, это снизить их число с помощью итеративного сравнения тегов. Это не подходит по той же самой причине, по которой не подходят итеративные компараторы: на это потребуется слишком много времени.
Полностью ассоциативная кэш-память практична для кэш-памяти малого размера (например, кэш-память TLB в некоторых процессорах Intel является полностью ассоциативной), но эта кэш-память должна быть небольшой - действительно небольшой. Речь идет максимум о нескольких десятках записей.
Для кэш-памяти L1i, L1d и кэш-памяти более высокого уровня необходим другой подход. Все, что можно сделать, это ограничить поиск. В самом крайнем случае каждый тег отображается точно в одну кэш-запись. Расчет прост: для кэш-памяти 4MB/64B с 65 536 записями мы можем напрямую обращаться к каждому элементу и использовать для этого с 6-го по 21-й биты адреса (16 битов). Младшие 6 битов являются индексом кэш-строки.

Рис.3.6: Схематическое изображение кэш-памяти с прямым отображением
Как видно из рисунка 3.6 реализация такой кэш-памяти с прямым отображением (direct-mapped cache) может быть быстрой и простой. Для нее требуется только один компаратор, один мультиплексор (на этой схеме приведены два, поскольку тег и данные разделены, но это не является строгим конструктивным требованием) и некоторая логическая схема для выбора контента, содержащего действительно допустимые кэш-строки. Компаратор сложный из-за требований, касающихся скорости, но теперь он только один; в результате можно потратить больше усилий, чтобы сделать его более быстрым. Реальная сложность такого подхода заключена в мультиплексорах. Количество транзисторов в простом мультиплексоре растет по закону O(log N), где N является количеством кэш-строк. Это приемлемо, но может получиться медленный мультиплексор, и в этом случае скорость можно увеличить, если потратиться на транзисторы в мультиплексорах и для увеличения скорости распараллелить часть работы. Общее количество транзисторов будет расти медленное в сравнении с ростом размера кэш-памяти, что делает это решение очень привлекательным. Но у такого подхода есть недостаток: он работает только в случае, если адреса, используемые в программе, равномерно распределены относительно битов, используемых для прямого отображения. Если это не так, и это обычно бывает, некоторые кэш-записи используются активно и, поэтому, неоднократно высвобождаются, в то время как другие практически вообще не используются, либо остаются пустыми.

Рис.3.7: Схематическое изображение кэш-памяти с множественной ассоциативностью
Эту проблему можно решить с помощью кэш-памяти с множественной ассоциативностью (set associative). Кэш-память с множественностью ассоциативностью сочетает в себе черты кэш-памяти с полной ассоциативностью и кэш-памяти с прямым отображением, что позволяет в значительной степени избежать недостатков этих решений. На рис.3.7 показана схема кэш-памяти с множественной ассоциативностью. Память под теги и под данные разделена на наборы, выбор которых осуществляется в соответствие с адресом. Это похоже на кэш-память с прямым отображением. Но вместо того, чтобы для каждого значения из набора использовать отдельный элемент, один и тот же набор используется для кэширования некоторого небольшого количества значений. Теги для всех элементов набора сравниваются параллельно, что похоже на функционирование полностью ассоциативной кэш-памяти.
Результатом является кэш-память, которая достаточно устойчива к промахам из-за неудачного или преднамеренного выбора адресов с одними и теми же номерами наборов в одно и то же время, а размер кэш-памяти не ограничен количеством компараторов, которые могут работать параллельно. Если кэш-память увеличивается (смотрите рисунок), то увеличивается только количество столбцов, а не количество строк. Число строк увеличивается только в том случае, если повышается ассоциативность кэш-памяти. Сегодня процессоры для кэш-памяти L2 используют уровни ассоциативности до 16 и выше. Для кэш-памяти L1 обычно используется уровень, равный 8.
Таблица 3.1: Влияние размера кэш-памяти, ассоциативности и размера кэш-строки
| Размер кэш-памяти L2 |
Ассоциативность | |||||||
|---|---|---|---|---|---|---|---|---|
| Прямое отображение | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27 794 595 | 20 422 527 | 25 222 611 | 18 303 581 | 24 096 510 | 17 356 121 | 23 666 929 | 17 029 334 |
| 1M | 19 007 315 | 13 903 854 | 16 566 738 | 12 127 174 | 15 537 500 | 11 436 705 | 15 162 895 | 11 233 896 |
| 2M | 12 230 962 | 8 801 403 | 9 081 881 | 6 491 011 | 7 878 601 | 5 675 181 | 7 391 389 | 5 382 064 |
| 4M | 7 749 986 | 5 427 836 | 4 736 187 | 3 159 507 | 3 788 122 | 2 418 898 | 3 430 713 | 2 125 103 |
| 8M | 4 731 904 | 3 209 693 | 2 690 498 | 1 602 957 | 2 207 655 | 1 228 190 | 2 111 075 | 1 155 847 |
| 16M | 2 620 587 | 1 528 592 | 1 958 293 | 1 089 580 | 1 704 878 | 883 530 | 1 671 541 | 862 324 |
Если у нас кэш-память 4MB/64B и 8-канальная ассоциативность, то в кэш-памяти у нас будет 8192 наборов и для адресации кэш-наборов потребуется только 13 битов тега. Чтобы определить, какая из записей (если таковая имеется) содержит в кэш-наборе адресуемую кэш-строку, потребуется сравнить 8 тегов. Это можно сделать за очень короткое время. Как видно из практики, в этом смысл есть.
В таблице 3.1 показано количество промахов кэш-памяти L2 для некоторой программы (в данном случае --- для компилятора gcc, который, по мнению разработчиков ядра Linux, является наиболее важным бенчмарком) при изменении размера кэш-памяти, размера кэш-строки, а также значения множественной ассоциативности. В разделе 7.2 мы познакомимся с инструментальным средством, предназначенным для моделирования кэш-памяти, которое необходимо для этого теста.
Просто, если это еще не очевидно, взаимосвязь всех этих значений в том, что размер кэш-памяти равен
размер кэш-строки х ассоциативность х количество множеств
Отображение адресов в кэш-память вычисляется как
$O = log_{2}$ от размера кэш-строки
$S = log_{2}$ от числа наборов
согласно рисунку в разделе 3.2.

Рис.3.8: Размер кэш-памяти и уровень ассоциативности (CL=32)
Рис. 3.8 делает данные таблицы более понятными. На рисунке приведены данные для кэш-строки фиксированного размера, равного 32 байта. Если посмотреть на цифры для заданного размера кэш-памяти, то видно, что ассоциативность действительно может существенно помочь сократить число промахов кэш-памяти. Для кэш-памяти размером 8 МБ при переходе от прямого отображения на кэш-память с 2-канальной ассоциативностью экономится почти 44% кэш-памяти. В случае, если используется кэш-память со множественной ассоциативностью, то процессор может хранить в кэш-памяти рабочий набор большего размера, чем в случае кэш-памяти с прямым отображением.
В литературе иногда можно прочитать, что введение ассоциативности имеет тот же самый эффект, как удвоение размера кэш-памяти. Это, как это видно для случая перехода от кэш-памяти размером 4 МБ к кэш-памяти размером 8 МБ, верно в некоторых крайних случаях. Но это, конечно, не верно при последующем увеличении ассоциативности. Как видно из данных, последующее увеличение ассоциативности дает существенно меньший выигрыш. Нам, однако, не следует абсолютно не учитывать этот факт. В программе нашего примера пик использования памяти равен 5,6 MB. Так что при размере кэш-памяти в 8 Мб, что те же самые кэш-наборы будут использоваться многократно (более, чем дважды). С увеличением рабочего набора экономия может увеличиться, поскольку, как мы видим, при меньших размерах кэш-памяти преимущество от использования ассоциативности будет больше.
В целом, увеличение ассоциативность кэш-памяти выше 8, как кажется, дает слабый эффект при одном потоке рабочей нагрузки. С появлением многоядерных процессоров, которые используют общую кэш-память L2, ситуация меняется. Теперь у вас в основном есть две программы, которые обращаются к одной и той же кэш-памяти, в результате чего на практике эффект от использования ассоциативности должен увеличиться вдвое (или в четыре раза для четырехядерных процессоров). Таким образом, можно ожидать, что с увеличением числа ядер, ассоциативность общей кэш-памяти должна расти. Как это станет делать невозможным (16-канальную ассоциативность реализовывать уже трудно) разработчики процессоров начнут использовать общую кэш-память уровня L3 и далее, в то время как кэш-память уровня L2 будет, потенциально, совместно использоваться некоторым подмножеством ядер.
Другой эффект, который мы можем увидеть на рис.3.8, это то, как увеличение размера кэш-памяти способствует увеличению производительности. Эти данные нельзя интерпретировать без знания размера рабочего набора. Очевидно, что кэш-память такого размера, как основная память, должен привести к лучшим результатам, нежели кэш-память меньшего размера, так что в целом нет никаких ограничений на увеличение размера кэш-памяти и получения ощутимых преимуществ.
Как уже упоминалось выше, размер рабочего набора в его пиковом значении равен 5,6 Мб. Это значение не позволяет нам рассчитать размер памяти, который бы принес максимальную выгоду, но позволяет оценить этот размер. Проблема в том, что вся память используется не непрерывно и, следовательно, у нас есть конфликты даже при наличии 16M кэш-памяти и рабочего набора, размер которого равен 5,6M (вспомните преимущество 2-канальной ассоциативной кэш-памяти размером в 16 МБ над версией с прямым отображением). Но можно с уверенностью сказать, что при такой нагрузке преимущество кэш-памяти размером в 32 МБ будет несущественным. Однако кто сказал, что рабочий набор должен оставаться неизменным? С течением времени рабочие нагрузки растут и то же самое должно касаться размера кэш-памяти. Когда покупаются машины и принимается решение, за какой размер кэш-памяти требуется заплатить, стоит измерить размер рабочего набора. Почему это важно, можно увидеть на рис. 3.10.
Рис.3.9: Размещение памяти, используемой при тестировании
Запускается два типа тестов. В первом тесте элементы обрабатываются последовательно. В тестовой программе используется указатель n, но элементы массива связаны друг с другом, так что они обходятся в том порядке, в котором они находятся в памяти. Этот вариант показан в нижней части рис.3.9. Есть одна обратная ссылка, идущая от последнего элемента. Во втором тесте (верхняя часть рисунка) элементы массива обходятся в произвольном порядке. В обоих случаях элементы массива образуют циклический односвязный список.
3.3.2 Измерение влияния использования кэш-памяти
Все рисунки строятся на основе измерений при помощи программы, в которой можно промоделировать рабочие наборы произвольного размера, доступ на чтение и запись, а также доступ в последовательном или произвольном порядке. Некоторые результаты мы уже видели на рис.3.4. Программа создает массив, соответствующий по размеру рабочего набора и состоящий из элементов следующего типа:
struct l {
struct l *n;
long int pad[NPAD];
};
Все элементы соединяются в циклический список с помощью элемента n в последовательном или случайном порядке. При переходе от одного элемента к следующему всегда используется указатель, даже если элементы расположены последовательно. Элемент pad представляет собой полезную нагрузку и его можно делать сколь угодно большим. В некоторых тестах данные изменяются, в других программа выполняет только операции чтения.
При выполнении измерений мы говорим о размерах рабочего набора. Рабочий набор состоит из массива элементов структуры struct l. В рабочем наборе размером в 2N байтов находятся
2N/sizeof(struct l)
элементов. Очевидно, что значение sizeof(struct l) зависит от величины NPAD. Для 32-разрядных систем, NPAD=7 означает, что размер каждого элемента массива равен 32 байта, а для 64-разрядных систем - 64 байта.
Однопоточный последовательный доступ
Простейший случай представляет собой простой обход всех записей в списке. Элементы списка располагаются последовательно, между ними нет промежутков. Порядок обхода значения не имеет, процессор может выполнять обход одинаково хорошо в обоих направлениях. Мы измеряем здесь, а также во всех следующих тестах, время, в течение которого выполняется обработка одного элемента списка. Единицей времени является процессорный цикл. Результат приведен на рис.3.10. Если не указано что-либо иное, все измерения выполняется на машине с процессором Pentium 4 в 64-разрядном режиме, что означает, что структура structure l с NPAD=0 имеет размер в восемь байт.

Рис.3.10: Доступ с последовательным чтением, NPAD=0

Рис.3.11: Последовательное чтение для нескольких значений размеров
Первые два измерения загрязнены шумом. Измеряемая нагрузка слишком мала, чтобы из нее отфильтровать влияние остальной части системы. Мы можем смело предположить, что все значения равны уровню в 4 цикла. С учетом этого, мы видим следующие три различных фрагмента:
- Когда размер рабочего набора увеличивается до 214 байтов.
- Размер от 215 байтов и до 220 байтов
- Размер от 221 байтов и выше.
Эти различия можно легко объяснить: в процессоре есть 16kB кэш-памяти L1d и 1MB кэш-памяти L2. При переходе от одного уровня к другому острых углов не видно, поскольку кэш-память используется другими частями системы, а также кэш-память не предназначена для хранения исключительно данных программы. В частности, кэш-память L2 является универсальной кэш-памятью и она также используется для инструкций (Замечание: Intel использует инклюзивную кэш-память).
Что, возможно, не вполне ожидаемо, это действительно затрачиваемое время для рабочих наборов различного размера. Значения времени при попадании данных в кэш-памятьL1d оказывается ожидаемым: время загрузки после попадания в кэш-память L1d составляет приблизительно 4 цикла для процессора P4. Но как насчет доступа к кэш-памяти L2? Как только кэш-памяти L1d окажется недостаточно для хранения данных, можно ожидать, что в кэш-памяти L2 для одного элемента потребуется 14 циклов или более. Но результаты показывают, что требуется лишь около 9 циклов. Это несоответствие можно объяснить только использованием в процессорах улучшенной логики. Предполагая, что будут использоваться последовательно идущие области памяти, процессор осуществляет предварительную загрузку (prefetches) следующей кэш-строки. Это означает, что когда на самом деле будет использоваться следующая строка, она окажется уже наполовину загруженной. Поэтому задержка, которая требуется на ожидание загрузки следующей кэш-строки, гораздо меньше, чем время доступа к кэш-памяти L2.
Эффект предварительной загрузки будет еще большее в случае, если размер рабочего набора будет превышать размер кэш-памяти L2. Ранее мы говорили, что на доступ к основной памяти затрачивается более 200 циклов. Однако при использовании эффективной предварительной загрузки время доступа в процессоре можно уменьшить до 9 циклов. Как видно из разницы между 200 и 9, это работает прекрасно.
Мы можем, по крайней мере, косвенно, пронаблюдать за тем, как процессор выполняет предварительную загрузку. На рис.3.11 показаны значения времени для различных размеров одного и того же рабочего набора, но на этот раз мы рассмотрим графики для различных размеров структуры structure l. Они отличаются тем, что элементов в списке меньше, но размеры элементов - больше. Влияние различия размеров элементов выражается в том, что расстояние между элементами n (они, по-прежнему, идут последовательно) растет. Для четырех вариантов графика значения равны 0, 56, 120 и 248 байтов, соответственно.
В нижней части мы видим строку из предыдущего графика, но на этот раз он выглядит более или менее прямой линией. Значения времени для других случаев выглядят гораздо хуже. На этом графике мы также видим три других уровня, а также большое количество ошибок в тестах с небольшими размерами рабочего набора (игнорируем их снова). До тех пор, пока используется только кэш-память L1d , графики, более или менее, везде совпадают. Предварительная загрузка не нужна и поэтому при каждом доступе в кэш-память L1d имеет место попадание для элементов всех размеров.
Что касается попаданий кэш-памяти L2, то, как мы видим, три новых графика, в целом, совпадают друг с другом, но находятся на более высоком уровне (около 28). Это уровень времени доступа к кэш-памяти L2. Это значит, что, как правило, отсутствует предварительная загрузка из кэш-памяти L2 в кэш-память L1d. Даже для NPAD = 7 нам при каждой итерации требуется новая кэш-строка; для NPAD = 0 цикл должен повториться восемь раз прежде, чем потребуется следующая кэш-строка. Нельзя на каждом цикле загружать новую строку с помощью технологии предварительной загрузки. Поэтому в каждой итерации мы видим срыв загрузки из кэш-памяти L2.
Еще более интересная ситуация в случае, когда раз размер рабочего набора превышает объем кэш-памяти L2. Теперь все четыре кэш-строки сильно отличаются друг от друга. Очевидно, что при изменении производительности разница размеров элементов играет важную роль. Процессор должен определить размер необходимого фрагмента данных и в случае, когда NPAD = 15 и 31, не выполнять ненужный поиск кэш-строк, поскольку размер элемента меньше, чем окно предварительной загрузки (см. раздел 6.3.1). Если изменение размера элемента оказывает на предварительную загрузку сильное влияние, то это значит, что на затраты, связанные с предварительной загрузкой, влияют аппаратные ограничения: предварительная загрузка не может нарушать границы страниц. При каждом увеличении размера мы снижаем аппаратную эффективность на 50%. Если бы в аппаратной реализации предварительной загрузки было бы разрешено нарушать границы страниц, а следующая страница не была бы резидентной или допустимой, то для поиска страницы пришлось бы привлечь OS. Это означает, что программа может получить отказ в доступе к странице, доступ к которой не был инициализирован самой программой. Это совершенно неприемлемо, поскольку процессор не знает, существует ли некоторая страница и присутствует ли она в оперативной памяти. В последнем случае операционная система должна прервать процесс. В любом случае, если учесть, что для NPAD = 7 и более нам для каждого элемента списка нужна одна строка кэша, аппаратная предварительная загрузка много сделать не сможет. Просто не хватит времени для загрузки данных из памяти, поскольку все, что процессор успеет сделать, это прочитать одно слово, а затем загрузить следующий элемент.
Еще одна существенная причина снижения производительности связана с промахами в кэш-памяти TLB. Это кэш-память, в которой, как это было подробно описано в разделе 4, запоминается результат перевода виртуальных адресов в физические адреса. Кэш-память TLB достаточно мала, поскольку она должна быть очень быстрой. Если доступно больше страниц, чем для них в кэш-памяти TLB может поместиться записей, используемых для перевода из виртуального в физический адрес, то перевод адресов должен повторяться. Это очень дорогостоящая операция. Если элементы большего размера, то затраты на поиск в кэш-памяти TLB компенсируются обработкой меньшего количества элементов. Это означает, что общее количество записей в кэш-памяти TLB, которые должны быть обработаны для одного элемента списка, будет большим.
Чтобы пронаблюдать за эффектами кэш-памяти TLB, мы можем запустить другой тест. При первом измерении мы, как и обычно, расположим элементы последовательно. Мы используем NPAD = 7 для элементов, которые полностью занимают одну кэш-строку. При втором измерении мы помещаем каждый элемент списка на отдельную страницу. Оставшееся место на каждой странице мы не используем и не учитываем его при подсчете общего размера рабочего набора. {Да, это немного непоследовательно, поскольку в других тестах мы учитываем неиспользуемую часть структуры в размере элемента, и мы могли бы определить NPAD так, чтобы каждый элемент занимал всю страницу. В подобном случае размеры рабочих наборов были бы совсем другими. Хотя это и не рассматривается в этом тесте, но в любом случае из-за неэффективности предварительной загрузки это мало что изменит}. Из-за этого в случае первого измерении при каждой итерации по списку потребуется новая кэш-строка, а для каждых 64 элементов --- новая страница. В случае второго измерения для каждой итерации потребуется загрузить новую кэш-строку, которая будет находиться на новой странице.
Рис.3.12: Влияние кэш-памяти TLB при последовательном чтении элементов
Результат можно увидеть на рис.3.12. Измерения проводились на той же машине, что и для рис.3.11. В связи с ограничениями имеющейся основной памяти, размер рабочего набора пришлось ограничить 224 байтами, для которых требуется 1 Гб памяти, чтобы разместить объекты на отдельных страницах. Нижняя, красная кривая в точности соответствует кривой NPAD = 7 на рис.3.11. Мы видим различные фрагменты, указывающие размеры кэш-памяти L1d и L2. Вторая кривая отличается радикальным образом. Важным отличием является резкое увеличение значения, начинающиеся, когда размер рабочего набора достигает 213 байтов. Это происходит при переполнении кэш-памяти TLB. При условии, что размер элемента равен 64 байта, мы можем вычислить, что в кэш-памяти TLB находятся 64 записи. Ошибки отказа в доступе к страницам отсутствуют, т. к. программа блокирует память для того, чтобы предотвратить использование подкачки.
Видно, что количество циклов, необходимое для вычисления физического адреса и сохранения его в кэш-памяти TLB, очень большое. На графике на рисунке 3.12 показан экстремальный случай, но должно быть понятно, что важным фактором снижения производительности при больших значениях NPAD является уменьшение эффективности кэш-памяти TLB. Поскольку физический адрес должен вычисляться раньше, чем можно будет для кэш-памяти L2 или основной памяти прочитать кэш-строку, затраты, необходимые на это вычисление, добавляются к затратам времени доступа к памяти. Этим частично объясняется, почему общие затраты на один элемент списка для NPAD = 31 выше, чем теоретическое время доступа к памяти.

Рис.3.13: Последовательное чтение и запись, NPAD=1
Мы можем увидеть несколько более подробную информацию, касающуюся реализации предварительной загрузки, если посмотрим на результаты теста, в котором элементы списка изменяются. На рис.3.13 показаны три графика. Размер элементов во всех случаях равен 16 байтам. Первый график соответствует уже знакомому нам проходу по списку, который рассматривается как базовый. Для второго графика, помеченного как "Inc", перед переходом к следующему элементу в текущем элементе просто происходит увеличение компонента pad[0]. Для третьего графика, помеченного как "Addnext0", берется компонента pad[0] следующего элемента в списке, которая добавляется к компоненту pad[0] члена текущего элемента списка.
Естественно предположить, что тест "Addnext0" работает медленнее, поскольку ему предстоит выполнить больше работы. Перед тем, как переходить к следующему элементу списка, требуется загрузить его значение его элемента. Вот почему оказывается удивительно, что, на самом деле, этот тест для некоторых размеров рабочих наборов работает быстрее, чем тест "Inc". Объясняется это тем, что доступ к следующему элементу списка происходит, главным образом, с помощью принудительно выполняемой предварительной загрузки. Каждый раз, когда программа переходит к следующему элементу списка, мы можем быть уверены, что этот элемент будет находиться в кэш-памяти L1d. В результате мы видим, что до тех пор, пока рабочий набор по размеру помещается в кэш-память L2, на тест "Addnext0" затрачивается столько же времени, сколько и на тест "Follow".
Однако тест "Addnext0", когда он выходит за границы кэш-памяти L2, не поспевает за тестом "Inc". Для него требуется загружать из основной памяти больше данных. Вот почему при размере рабочего набора в 221 байтов кривая теста "Addnext0" достигает уровня в 28 циклов. Уровень в 28 циклов вдвое больше, чем уровень в 14 циклов, которого достигает кривая теста "Follow". Это тоже легко объяснить. Когда память изменяется, то, в отличие от двух других тестов, в этом тесте для того, чтобы освободить место в кэш-памяти L2 под новую кэш-строку, нельзя просто выбросить данные. Вместо этого данные должны быть записаны в память. Это значит, что доступная пропускная способность шины FSB уменьшается вдвое и, удваивается время, требуемое для передачи данных из основной памяти в кэш-память L2.

Рис.3.14: Преимущество большого размера кэш-памяти L2/L3
И последний фактором, влияющим на эффективность последовательной обработки данных в кэш-памяти, является ее размер. Это должно быть очевидным, но, тем не менее, на этот фактор следует указать. На рис.3.14 показано время для теста Increment с элементами размером в 128 байтов (NPAD=15 для 64-разрядных машин). На этот раз мы видим, измерения с трех разных машин. В первых двух машинах используется процессор P4, в последней --- Core 2. Первые две различаются размерами кэш-памяти. В первом процессоре имеется 32k кэш-памяти L1d и 1M кэш-памяти L2. Во второй имеется 16k кэш-памяти L1d, 512k кэш-памяти L2 и 2M кэш-памяти L3. В процессоре Core 2 имеется 32k кэш-памяти L1d и 4M кэш-памяти L2.
На графике интересно не то, насколько хорошо процессор Core 2 работает в сравнении с другими двумя процессорами (хотя это и впечатляет). Наибольший интерес представляет та часть графика, где размер рабочего набора является слишком большим для соответствующей кэш-памяти последнего уровня и участие в работе принимает основная память.
Таблица 3.2. Попадания и пропуски при последовательном обходе списка и при обходе списка в произвольном порядке
| Размер набора |
Последовательно | Произвольным образом | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Попадания L2 |
Промахи L2 |
Число итераций |
Отношение пропусков / попаданий |
Доступ к L2 на одну итерацию |
Попадания L2 |
Промахи L2 |
Число итераций |
Отношение пропусков / попаданий |
Доступ к L2 на одну итерацию | |
| 220 | 88 636 | 843 | 16 384 | 0.94% | 5.5 | 30 462 | 4721 | 1 024 | 13.42% | 34.4 |
| 221 | 88 105 | 1 584 | 8 192 | 1.77% | 10.9 | 21 817 | 15 151 | 512 | 40.98% | 72.2 |
| 222 | 88 106 | 1 600 | 4 096 | 1.78% | 21.9 | 22 258 | 22 285 | 256 | 50.03% | 174.0 |
| 223 | 88 104 | 1 614 | 2 048 | 1.80% | 43.8 | 27 521 | 26 274 | 128 | 48.84% | 420.3 |
| 224 | 88 114 | 1 655 | 1 024 | 1.84% | 87.7 | 33 166 | 29 115 | 64 | 46.75% | 973.1 |
| 225 | 88 112 | 1 730 | 512 | 1.93% | 175.5 | 39 858 | 32 360 | 32 | 44.81% | 2 256.8 |
| 226 | 88 112 | 1 906 | 256 | 2.12% | 351.6 | 48 539 | 38 151 | 16 | 44.01% | 5 418.1 |
| 227 | 88 114 | 2 244 | 128 | 2.48% | 705.9 | 62 423 | 52,049 | 8 | 45.47% | 14 309.0 |
| 228 | 88 120 | 2 939 | 64 | 3.23% | 1 422.8 | 81 906 | 87 167 | 4 | 51.56% | 42 268.3 |
| 229 | 88 137 | 4 318 | 32 | 4.67% | 2 889.2 | 119 079 | 163 398 | 2 | 57.84% | 141 238.5 |
Как и ожидалось, чем больше размер кэш-памяти последнего уровня, тем дольше кривая остается на низком уровне, соответствующем затратам на доступ к кэш-памяти L2. Важно отметить благодаря чему достигается повышенная производительность. Второй процессор (который чуть старее) может обрабатывать рабочий набор размером в 220 байтов вдвое быстрее, чем первый процессор. Все это благодаря увеличенному размеру кэш-памяти последнего уровня. Процессор Core 2 с 4M кэш-памяти L2 выполняет это работу еще лучше.
Если нагрузка меняется случайным образом, то это не столь важно. Но если нагрузку можно изменить в соответствие с размером кэш-памяти последнего уровня, то скорость выполнения программы можно увеличить весьма существенно. Вот почему иногда стоит потратиться на процессор с кэш-памятью большего размера.
Измерение однопоточного доступа, осуществляемого в произвольном порядке
Мы видели, что процессор благодаря предварительной загрузке кэш-строк в кэш-память L2 и L1d может скрыть большую часть затрат, связанных с оперативной памятью и даже с задержками доступа к кэш-памяти L2. Одна это может хорошо работать только в случае, когда доступ к памяти предсказуем.

Рис.3.15: Чтение в последовательном / произвольном порядке, NPAD=0
Если доступ непредсказуем или происходит случайным образом, то ситуация совершенно иная. На рис.3.15 сравнивается время доступа к отдельному элементу списка при последовательном доступе (как на рис.3.10) с временем доступа в случае, когда элементы списка распределены в рабочем наборе случайным образом. Порядок определяется с помощью связного списка, порядок элементов в котором задан случайным образом. Процессор не может гарантированно выполнять предварительную загрузку данных. Это может произойти только случайно, если элементы, которые обрабатываются почти пдряд, в памяти также расположены близко друг к другу.
На рис.3.15 видно два важных факта, которые следует отметить. Во-первых, большее число циклов, которое требуется при увеличении размеров рабочего набора. Машина позволяет получить доступ к основной памяти за 200-300 циклов, но здесь значение достигает 450 циклов и более. Мы сталкивались с таким феноменом ранее (сравните с рис 3.11). В действительности, использование автоматической предварительной загрузки приводит здесь к потерям.
Вторым интересным фактом является то, что у кривой нет ровных горизонтальных участков таких, как в случае последовательного доступа. Кривая продолжает расти. Чтобы объяснить это, нам нужно измерить доступ программы к кэш-памяти L2 при различных размерах рабочего набора. Результат виден на рис.3.16 и в таблице 3.2.
На рисунке показано, что, когда размер рабочего набора больше, чем размер кэш-памяти L2, начинает расти относительная величина промахов кэш-памяти (промах кэш-памяти L2 / доступ в кеш-память L2). На рис.3.15 кривая имеет аналогичную форму: она резко растет, затем немного уменьшает наклон, а затем снова начинает расти. Есть тесная взаимосвязь с графиком числа циклов для отдельного элемента списка. Показатель промахов для кэш-памяти L2 будет расти до тех пор, пока он, в конечном счете, не достигнет почти 100%. При достаточно большом рабочем наборе (и размере основной памяти) вероятность того, что любые случайным образом выбираемые кэш-строки находятся в кэш-памяти L2 или будут загружены процессом, может произвольным образом снижаться.
Увеличение количества промахов кэш-памяти указывает только на некоторые bp затрат. Но есть и другой показатель. Если вглянуть на таблицу 3.2, то в столбцах "Доступ к L2 на одну итерацию" видно, что растет общее количество кэш-памяти L2, используемой в каждой итерации программы. Каждый следующий рабочий набор в два раза больше, чем предыдущий. Таким образом, без кэширования можно было бы ожидать двойное увеличение затрат на доступ к основной памяти. При наличии кэш-памяти и (почти) идеальной предсказуемости мы видим в данных, относящихся к последовательному доступу, незначительное увеличение использования кэш-памяти L2. Это увеличение связано с увеличением размера рабочего набора и больше ни с чем.

Рис.3.16: Показатель промахов кэш-памяти L2d

Рис.3.17: Постраничный доступ в произвольном порядке, NPAD=7
При доступе в случайном порядке, время доступа к каждому элементу увеличивается более чем на 100% при каждом удвоении размера рабочего набора. Это значит, что среднее время доступа к каждому элементу списка увеличивается, т. к. размер рабочего набора только удваивается. Это обусловлено ростом числа промахов кэш-памяти TLB. На рис. 3.17 мы видим затраты при доступе в случайном порядке для значения NPAD = 7. Только на этот раз алгоритм рандомизации изменен. Тогда как в обычном случае весь список рандомизируется (устанавливается случайный порядок доступа к элементам списка --- прим.пер.) в виде единого блока (помечено символом ∞), с помощью остальных 11 кривых показаны варианты, когда рандомизация выполняется для более мелких блоков. Для кривой, помеченной как '60',отдельно рандомизируется каждый набор из 60 страниц (245 760 байт). Это значит, что перед тем, как перейти к элементу в следующем блоке, выполняется обход всех элементов списка текущего блока. Это приводит к ограничению числа записей кэш-памяти TLB, которые используются в каждый конкретный момент.
Размер элемента для NPAD=7 равен 64 байта, что соответствует размеру кэш-строки. Из-за того, что доступ к элементам списка выполняется в случайном порядке (рандомизирован), маловероятно, что аппаратная предварительная загрузка окажет какое-нибудь влияние, по крайней мере более чем на несколько элементов. Это значит, что показатель промахов кэш-памяти L2 не будет сильно отличаться от случая, когда весь список рандомизируется в виде одного блока. При увеличении размера блока результаты выполнения теста асимптотически приближаются к кривой, соответствующей рандомизации одного блока. Это значит, что выполнение этого последнего теста в значительной степени зависит от промахов кэш-памяти TLB. Если удастся снизить количество промахов кэш-памяти TLB, то производительность значительно увеличится (в одном из тестов мы позже увидим увеличение до 38%).
3.3.3 Запись данных
Прежде, чем переходить к изучению поведения кэш-памяти в случае, одна и та же память используется в нескольких контекстах исполнения (потоках или процессах), рассмотрим детали реализации кэш-памяти. Предполагается, что кэш-память однородная, а также предполагается, что ее однородность полностью прозрачна для кода пользовательского уровня. Код ядра это уже другая история; для него иногда требуется принудительное сохранение содержимого кэш-памяти.
В частности, это значит, что если кэш-строка изменена, то после этого момента результат для системы должен быть точно такой же, как если бы кэш-памяти вообще не было и изменялось содержимое основной памяти. Это можно реализовывать двумя способами или политиками:
- реализация кэш-памяти с прямой записью;
- реализация кэш-памяти с обратной записью.
Кэш-память с прямой записью является самым простым способом реализации однородности кэш-памяти. Если выполняется запись в кэш-строку, то процессор сразу же запишет кэш-строку в основную память. Это гарантирует, что в любой момент времени оперативная память и кэш-память будут синхронизированы. Всякий раз, когда происходит замена содержимого кэш-памяти, предыдущее содержимое может быть просто затерто. Такая политика работы с кэш-памятью очень проста, но не очень быстрая. Программа, которая, например, снова и снова изменяет локальные переменные, будет создавать большой объем трафика на шине FSB даже в случае, если данные, вероятно, нигде больше не используются и нужны на короткое время.
Политика с обратной записью является более сложной. Здесь процессор не будет сразу записывать модифицированную кэш-строку орбратно в основную память. Вместо этого, кэш-строка только помечается, как измененная. Когда кэш-строка удаляется из кэш-памяти в какой-то момент в будущем, то бит, указывающий на то, что данные изменились, будет указывать процессору записывать в этот момент данные обратно в основную память, а не просто их удалять.
У кэш-памяти с обратной записью есть шанс быть значительно эффективней и благодаря этому большая часть памяти в системе с приличным процессором кэшируется именно таким образом. Процессор перед тем, как кэш-строка будет переслана, может даже воспользоваться свободными ресурсами шины FSB для хранения содержимого кэш-строки. Благодаря этому можно сбросить бит, указывающий на изменение, и, когда в кэш-памяти потребуется место, то просто стереть содержимое кэш-строки.
Но с реализацией кэш-памяти с обратной записью есть серьезная проблема. Когда есть несколько процессоров (или ядер или гиперпотоков), имеющих доступ к одной и той же памяти, нужно еще обеспечить, чтобы в любой момент времени все процессоры видели одно и то же содержимое памяти. Если в одном процессоре кэш-строка изменена (т.е. она еще не была записана обратно в память), а второй процессор пытается прочитать это место памяти, операция чтения не может просто обратиться к основной памяти. Вместо нее требуется содержимое кэш-строки первого процессора. В следующем разделе мы увидим, как в настоящее время это реализуется.
Прежде, чем мы перейдем к этому, нужно упомянуть еще две политики работы с кэш-памятью:
- комбинированная запись и
- отсутствие кэширования.
Обе эти политики используются для специальных областей адресного пространства, которые не закреплены за реально существующей оперативной памятью. Ядро устанавливает эти политики для диапазонов адресов (в процессорах x86 используются регистры диапазонов типа памяти - Memory Type Range Registers или MTRR), а остальное происходит автоматически. Регистры MTRR также используются для выбора политик прямой и обратной записи.
Политика комбинированной записи является ограниченным вариантом оптимизации кэширования, который чаще используются для памяти таких устройств, как видеокарты. Поскольку затраты на передачу данных в устройство намного выше, чем затраты на локальный доступ к памяти, в случае, когда нужно сократить объем передаваемых данных, важность это политики становится еще большей. Если с помощью следующей операции изменяется следующее слово, то передача всей кэш-строки только потому, что в строку было записано слово, будет расточительным. Можно легко предположить, что когда память для соседних по горизонтали пикселей, расположенных на экране, в большинстве случаев будет также в памяти расположена по соседству друг с другом, является типичной ситуацией. Прежде, чем кэш-строка будет записана обратно в память, при комбинированной политике, как следует из названия, будут применены несколько режимов доступа. В идеальном случае вся кэш-строка изменяется слово за словом, и только после того, как будет записано последнее слово, кэш-строка будет переписана в устройство. В результате можно существенно увеличить скорость доступа к оперативной памяти устройства.
Наконец, есть некэшируемая память. Как правило, это означит, что эта память вообще не является оперативной памятью. Это может быть специальный адрес, который для того, чтобы к некоторым функциям можно было обращаться помимо процессора, указывается жестско. Что касается аппаратных средств, то это чаще всего связано с диапазонами адресов, отображаемых в память, которые используются для трансляции адресов при доступе к картам и устройствам через шину (PCIe и т.д.). Во встраиваемых устройствах иногда есть такие адреса памяти, которые можно использовать для включения и выключения светодиодного индикатора. Очевидно, что кэширование такого адреса будет плохим решением. Светодиоды в подобных случаях используется для отладки и информировании о состоянии устройства и эту информацию хочется увидеть как можно скорее. Содержимое памяти в картах PCIe может изменяться без вмешательства процессора, так что эта память не должна кэшироваться.
3.3.4 Поддержка многопроцессорности
В предыдущем разделе мы уже указывали на проблему, которая у нас возникает в случае, когда в игру вступают несколько процессоров. Даже в многоядерных процессорах есть проблемы для тех уровней кэш-памяти, к которым отсутствует совместный доступ (по крайней мере, для L1d).
Совершенно нецелесообразно предоставлять прямой доступ одного процессора к кэш-памяти другого процессора. Прежде всего, такой доступ недостаточно быстрый. Более практичной является альтернатива, когда в случае, когда это необходимо, содержимое кэш-памяти передается в другой процессор. Обратите внимание, что это относится и к кэш-памяти, к которой у процессора нет совместного доступа.
Вопрос теперь в том, когда должна происходить передача этой кэш-строки? На этот вопрос очень легко ответить: когда некоторому процессору нужно прочитать или записать кэш-строку, которая была изменена в кэш-памяти другого процессора. Но как процессор определит, изменена ли кэш-строка в кэш-памяти другого процессора? Если исходить только из того, что кэш-строка была загружена другим процессором, то такое решение будет (в лучшем случае) неоптимальным. Обычно, в большинстве случаев обращения к памяти доступ осуществляется для чтения и в результате этого кэш-строки не изменяются. Операции процессора над кэш-строками происходаят часто (конечно, почему бы и нет, если у нас есть такая возможность?), что означает, что широковещательная передача информации об измененных кэш-строках после каждого доступа на запись была бы непрактичной.
В течение ряда лет был разработан протокол согласования кэш-памяти MESI (Modified, Exclusive, Shared, Invalid). Протокол назван по названию четырех состояний, в которых может находиться кэш-строка при использовании протокола MESI:
- Modified - Модифицированный: Локальный процессор изменил кэш-строку. Также подразумевается, что в кэш-памяти находится только одна копия кэш-строки.
- Exclusive - Эксклюзивный: Кэш-строка не изменена, но известно, что она не загружена ни в какую-либо кэш-память другого процессора.
- Shared- Разделяемый: Кэш-строка не изменена, но она может быть в кэш-памяти какого-нибудь другого процессора.
- Invalid- Недействительный: Кэш-строка недействительна, т. е. не используется.
Этот протокол разрабатывался на протяжении многих лет на основе более простых вариантов, которые были менее сложными, но и менее эффективными. Используя эти четыре состояния можно эффективно реализовать кэш-память с обратной записью, обеспечивая при этом другим процессорам одновременный доступ к этим данным только для чтения.

Рис.3.18: Переходы между состояниями протокола MESI
Изменение состояний происходит без особых затрат за счет прослушивания или перехвата сигналов, что выполняется другими процессорами. Некоторые операции, которые выполняет процессор, анонсируются на внешних контактах и, следовательно, за пределами процессора становится известно о том, как происходит обработка кэш-памяти процессора. По запросу на адресной шине виден адрес кэш-строки. В следующем описании состояний и переходов между ними (смотрите рис.3.18), мы укажем, когда будет использована шина.
Первоначально все кэш-строки пусты, а, следовательно, и недействительны (состояние Invalid). Если данные будут загружены для записи, то кэш-строка станет модифицированной (состояние Modified). Если данные загружаются для чтения, то новое состояние зависит от того, будет ли та же кэш-строка также загружена другим процессором. Если будет, то новое состояние будет разделяемым (состояние Shared), в противном случае - эксклюзивным (состояние Exclusive).
Если кэш-строка модифицирована (состояние Modified) и чтение или запись выполняется локальным процессором, то инструкция может использовать содержимое текущее содержимое кэш-строки и ее состояние не изменяется. Если второй процессор хочет читать из кэш-строки, то первый процессор должен отправить содержимое кэш-строки во второй процессор, а затем изменить состояние на разделяемое (состояние Shared). Данные, переданные во второй процессор, также принимаются и обрабатываются контроллером памяти, который сохраняет данные в памяти. Если этого не произойдет, то кэш-строка не может быть помечена как Shared. Если второй процессор хочет сделать запись в кэш-строку, то первый процессор посылает содержимое кэш-строки и локально помечает кэш-строку как недействительную (состояние Invalid). Это печально известная операция "Request For Ownership" (RFO). Выполнение этой операции в кэш-памяти последнего уровня, например, переход I → M, является сравнительно дорогим. Для кэш-памяти с прямой записью мы также должны добавить время, необходимое для записи нового содержимого кэш-строки на следующий более высокий уровень или в оперативную память, что еще увеличит затраты.
Если кэш-строка находится в разделяемом состоянии (состояние Shared) и локальный процессор выполняет чтение, то нет необходимости изменять состояние и чтение можно выполнить из кэш-строки. Если в кэш-строке происходит локальная запись, то кэш-строка также может использоваться, но ее состояние изменится на модифицированное (состояние Modified). При этом также потребуется, чтобы все другие возможные копии кэш-строки в других процессорах были помечены как недействительные (состояние Invalid). Таким образом, операция записи должна с помощью сообщения RFO оповестить другие процессоры об этом. Если кэш-строка запрашивается вторым процессором для чтения, то ничего не происходит. Текущие данных находятся в основной памяти, а локальное состояние уже помечено как разделяемое (состояние Shared). В случае, если второй процессор захочет сделать запись в кэш-строку (RFO), то кэш-строка будет просто помечена как недействительная (Invalid). Операции с шиной не нужны.
Эксклюзивное состояние (Exclusive), в основном, идентично разделяемому состоянию (Shared) с одним важным отличием: сообщения о локальных операциях записи не должны передаваться по шине. Известно, что локальная копия кэш-памяти только одна. Это является огромным преимуществом, поэтому процессор будет пытаться сохранить столько кэш-строк в эксклюзивном (Exclusive) состянии, а не в разделяемом (Shared), сколько это будет возможно. Для случая в состоянии Shared нужно возвращать данные обратно, если они на данный момент недоступны. В случае эксклюзивного состояния (Exclusive) все можно оставить так, как оно есть, без возникновения каких-либо проблем с функционированием. Единственное, что будет страдать - это производительность, поскольку переход E → M выполняется намного быстрее, чем переход S → M.
Из этого описания переходов между состояниями должно быть ясно, где возникают затраты, характерные для многопроцессорных операций. Да, заполнение кэш-памяти по-прежнему дорого, но теперь мы также должны обратить внимание на сообщения RFO. Всякий раз, когда должно быть отправлено такое сообщение, дела будут идти очень медленно.
Есть две ситуации, когда необходимы сообщения RFO:
- Поток мигрирует с одного процессора на другой, и все кэш-строки должны быть сразу перенесены на новый процессор.
- Кэш-строка действительно необходима в двух разных процессорах. {В меньшей степени то же самое верно для двух ядер на одном процессоре. Затраты только немного меньше. Вероятно, что сообщение RFO будет отправляться много раз.}
В многопоточных или многопроцессорных программах всегда есть необходимость в синхронизации; эта синхронизация осуществляется с использованием памяти. Таким образом, есть некоторые действительно нужные сообщения RFO. Они по-прежнему должны быть максимально редкими настолько, насколько это окажется возможным. Хотя есть и другие источники сообщений RFO. В разделе 6 мы разъясним эти сценарии. Сообщения протокола однородности кэш-памяти должны распространяться между процессорами системы. Переходы между состояниями MESI не будут происходить до тех пор, пока не станет ясно, что все процессоры в системе имели возможность отреагировать на сообщение. Это значит, что скорость протокола однородности определяется максимально возможным временем ответа. {Именно поэтому мы видим сегодня, например, системы AMD Opteron с тремя сокетами. Если учесть, что в каждом процессоре используются только три гиперссылки и еще одна, необходимая для подключения южного моста, процессор может выполнить ровно один далекий переход.} На шине возможны коллизии, в системах NUMA могут быть большие задержки и, конечно, большой объем трафика может замедлить ход событий. Все это достаточно веские причины для того, чтобы постараться избежать ненужного трафика.
Есть еще одна проблема, связанная с использованием более одного процессора. Эффект проявляется на вполне конкретных машинах, но, в принципе, эта проблема существует всегда: шина FSB является общим ресурсом. В большинстве машин все процессоры подключены к контроллеру памяти с помощью одной шины (смотрите рис.2.1). Если один процессор может исчерпать пропускную возможность шины (как это обычно и бывает), то два или четыре процессора, совместно использующих одну и ту же шину, будут для каждого процессора еще больше ограничивать пропускную способность шины.
Даже если каждый процессор имеет свою шину к контроллеру памяти так, как это показано на рис.2.2, есть еще шина к модулям памяти. Обычно это одна шина, но даже для расширенной модели, показанной на рис.2.2, при одновременном доступе к одному и тому же модулю памяти будет возникать ограничение пропускной способности.
То же самое справедливо и для модели AMD, где каждый процессор может иметь локальную память. Да, все процессоры могут одновременно и быстро получить доступ к локальной памяти. Но многопоточные и многозадачные программы должны для синхронизации получать, по крайней мере, время от времени, доступ к одним и теми же областям памяти.
Распараллеливание серьезно ограничивается окончательной пропускной способностью, которая обусловлена тем, как реализуется требуемая синхронизация. Нужно тщательно разрабатывать программы для того, чтобы минимизировать доступ разных процессоров и ядер к одним и тем же местам памяти. В следующих измерениях будут показаны этот и другие эффекты кэш-памяти, возникающие в многопоточном коде.
Измерение многопоточности
Для того, чтобы понять всю важность проблем, возникающих при использовании одних и тех же самых кэш-строк в разных процессорах, мы здесь рассмотрим еще несколько графиков производительности той же самой программы, которую мы использовали раньше. Однако, на этот раз будет одновременно запускаться более одного потока. Измеряться будет наилучшее время выполнения любого из потоков. Это означает, что время, в течение которого будут выполнены все потоки, будет больше. Используемая машина имеет четыре процессора; в тестах используется до четырех потоков. Все процессоры для доступа к контроллеру памяти используют одну и ту же шину, для доступа к модулям памяти имеется только одна шина.

Рис.3.19: Последовательный доступ на чтение, многопоточный вариант
На рис.3.19 показана производительность последовательного доступа только на чтение записей размером в 128 байтов (NPAD = 15 для 64-разрядной машины). Как можно было ожидать, кривая для одного потока аналогична кривой на рис.3.11. При измерениях на различных машинах фактические цифры отличаются.
Важная часть на этом рисунке это, конечно, поведение графика при работе с несколькими потоками. Обратите внимание, что память не изменяется и попытки синхронизации потоков при проходе по связному списку отсутствуют. Хотя сообщения RFO не являются необходимыми и ко всем кэш-строкам можно обращаться одновременно, мы видим, что в случае, когда используется два потока, снижение производительности для самого быстрого потока доходит до 18%, а при использовании четырех потоков --- до 34%. Поскольку кэш-строки не должны пересылаться между процессорами, то это снижение производительности обусловлено исключительно одним из следующих или обоими узкими местами: общей шиной, используемой для доступа от процессора к контроллеру памяти, и общей шиной, используемой для при доступе от контроллера памяти к модулям памяти. Как только размер рабочего набора становится больше размера кэш-памяти L3 для этой машины, во всех трех потоках будет происходить предварительная загрузка новых элементов списка. Даже при двух потоках пропускной способности недостаточно для того, что масштаб изменений был линейным (то есть, что отсутствовали накладные расходы, связанные работой нескольких потоков).
Когда мы модифицируем содержимое памяти, то все выглядит еще хуже. На рис.3.20 показаны результаты теста, осуществляющего последовательное приращение значений.

Рис.3.20: Последовательное приращение, многопоточный вариант
На этом графике для оси Y используется логарифмическая шкала. Поэтому обратите внимание, что, на самом деле, различия существенные. Мы при выполнении двух потоков все еще теряем 18% производительности, а теперь, как ни странно, при выполнении четырех потоков теряем 93% производительности. Это значит, что когда используются четыре потока, трафик предварительной загрузки вместе механизмом обратной записи значительно быстрее насыщают шину.
Мы при показе результатов изменений для кэш-памяти L1d используем логарифмическую шкалу. Все, что в этом случае можно увидеть, это то, что если работает более одного потока, кэш-память L1d, как правило, неэффективна. Время доступа для одного превышает 20 циклов только в случае, когда кэш-памяти L1d недостаточно для хранения рабочего набора. Когда работает несколько потоков, время доступа увеличивается до таких значений сразу даже с самым маленьким размером рабочего набора.
Здесь не показан один из аспектов этой проблемы. Его трудно измерить при использовании этой конкретной тестовой программы. Даже если тест изменяет содержимое памяти и мы, таким образом, должны ожидать появление сообщений RFO, мы в случае, когда используется более одного потока, мы не видим более высоких затрат для диапазона кэш-памяти L2. Программа должна использовать больше памяти, и все потоки должны в параллель получать доступ к одной и той же памяти. Этого трудно достичь без большого количества синхронизаций, что должно оказать доминирующее влияние на время выполнения.

Рис.3.21: Тест Addnextlast с произвольным порядком доступа, многопоточный вариант
Наконец, на рис.3.21 у нас приведены значения для теста Addnextlast с произвольным доступом к памяти. Этот рисунок представлен, в основном, для того, чтобы показать необычайно большие значения. В экстремальном случае обработка одного элемента списка достигает 1500 циклов. Под вопросом становится еще большего количества потоков. Мы можем в следующей таблице подвести итог, связанный с эффективность использования нескольких потоков.
Таблица 3.3: Эффективность в многопоточном случае
| Количествопотоков | Последовательное чтение | Последовательное добавление | Добавление в произвольном порядке |
|---|---|---|---|
| 2 | 1.69 | 1.69 | 1.54 |
| 4 | 2.98 | 2.07 | 1.65 |
В таблице показана эффективность многопоточной работы для наибольшего размера рабочего набора из трех значений, изображенных на рис.3.21. Показаны наилучшие значения по скорости тестовой программы для наибольшего размера рабочего набора при использовании случая двух или четырех потоков. Для случая двух потоков теоретический предел ускорения составляет 2, а для четырех потоков --- 4. Для случая двух потоков значения выглядят не так уж и плохо. Но для четырех потоков значения последнего теста показывают, что результат почти не стоит того, чтобы число потоков увеличивать больше двух. Дополнительный выигрыш незначительный. Нам это будет проще увидеть, если мы немного по-другому представим данные с рис.3.21.

Рис.3.22: Увеличение скорости за счет распараллеливания
Кривые на рис.3.22 показывают коэффициент увеличения скорости, т.е. относительную производительность по сравнению с кодом, исполняемым в одном потоке. Нам следует игнорировать небольшие изменения, т. к. измерения недостаточно точные. Для кэш-памяти L2 и L3, мы видим, что мы действительно получаем почти линейное увеличение скорости. Мы почти достигаем коэффициентов 2 и 4, соответственно. Но как только размер кэш-памяти L3 становится недостаточным для хранения рабочего набора, значения сразу портятся. Они одинаково плохи как для двух, так и для четырех потоков (смотрите четвертый столбец в таблице 3.3). Это одна из причин, почему почти невозможно найти материнскую плату с разъемами для более чем для четырех процессоров, на которой все процессоры используют один и тот же контроллер памяти. Машины с большим количеством процессоров должны быть построены по-другому (смотрите раздел 5).
Эти значения не универсальны. В некоторых случаях даже для рабочих наборов, которые помещаются по размеру в кэш-память последнего уровня, увеличение скорости не будет линейным. Фактически это типичная ситуация, поскольку потоки, как правило, не отделены друг от друга так, как это имеет место в данной тестовой программе. С другой стороны, можно работать с большими рабочими наборами и по-прежнему получать выигрыш при наличии более, чем двух потоков. Однако, для этого требуется подумать. Мы поговорим о некоторых подходах в разделе 6.
Специальный случай: гиперпотоки
Гиперпотоки (Hyper-Threads), иногда называемые симметричными мультипотоками (Symmetric Multi-Threading или SMT), реализуются внутри процессора и представляют собой особый случай, поскольку в действительности отдельные потоки не могу работать одновременно. Все они совместно пользуются почти всеми ресурсами процессора за исключением набора регистров. Отдельные ядра и процессоры продолжают работать параллельно, но потоки, обрабатываемые каждым ядром, ограничены этой особенностью. В теории в каждом ядре может быть много потоков, но до сих пор процессоры Intel имеют для каждого ядра не более, чем два потока. Процессор самостоятельно реализует временное мультиплексирование потоков. Онако, в этом, само по себе, смысла мало. Реальное преимущество в том, что процессор может переключаться на другой гиперпоток в тех случаях, когда выполнение гиперпотока, обрабатываемого в настоящий момент, затягивается. В большинстве случаев это задержка, связанная с обращением к памяти.
Если два потока работают на одном ядре, позволяющем использовать гиперпотоки, то программа будет более эффективной, чем однопоточный код, только в случае, если совокупное время исполнения обоих потоков будет меньше, чем время исполнения однопоточного кода. Это может быть за счет перекрытия времени ожидания, затрачиваемого на доступ к различным областям памяти, что обычно выполняется последовательно. Простой расчет показывает минимальные требования к степени попаданий кэш-памяти, которые позволят повысить скорость работы программы.
Время выполнения программы можно аппроксимировать следующим образом с помощью простой модели с одним уровнем кэш-памяти (смотрите [htimpact]):
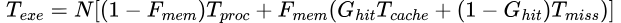
где:
- N = Количество инструкций.
- Fmem = Инструкции, обращающиеся в память.
- Ghit = Часть нагрузки, связанная с попаданиями в кэш-памяти.
- Tproc = Количество циклов на одну инструкцию.
- Tcache = Количество циклов при попадании в кэш-памяти.
- Tmiss = Количество циклов при промахе в кэш-памяти.
- Texe = Время выполнения программы
Чтобы имело смысл использовать два потока, время выполнения каждого из этих двух потоков должно быть не более половины от времени выполнения однопоточного кода. Единственная оптимизационная переменная для каждого потока - это количество попаданий в кэш-память. Если мы решим уравнение минимума коэффициента попаданий кэш-памяти с требованием не уменьшать скорость выполнения потока на 50% или более, мы получим график, показанный на рис.3.23.

Рис.3.23: Минимум коэффициента попаданий кэш-памяти при увеличении скорости
По оси X указываются значения показателя попаданий кэш памяти Ghit для однопоточного кода. По оси Y отображается требуемый показатель попаданий кэш-памяти для многопоточного кода. Это значение никогда не может быть больше, чем показатель попаданий для однопоточного кода, поскольку, в противном случае, в однопоточном коде можно будет также использовать этот улучшенный код. Если показатель попаданий для однопоточного кода ниже 55%, то программа может во всех случаях получить преимущество от использования потоков. Из-за промахов кэш-памяти у процессора достаточно времени простоя с тем, чтобы он мог запустить второй гиперпоток.
Целевой является зеленая область. Если спад для потока составляет менее 50%, а рабочая нагрузка для каждого потока уменьшается вдвое, то совокупное время выполнения может быть меньше, чем время выполнения однопоточного кода. Для моделируемой здесь системы (были использования значения для процессора P4 с гиперпотоками) программа с коэффициентом попаданий 60% для однопоточного кода потребует по крайней мере коэффициента попаданий 10% для программы с двумя потоками. Это, как правило, выполнимо. Но если однопоточный код имеет коэффициент попадания 95%, то для многопоточного кода необходим коэффициент попаданий не менее 80%. Это сложнее. Особенно, и это проблема гиперпотоков, из-за того, что эффективный размер кэша (здесь это L1d , на практике это также L2 и т. д.), доступный для каждого гиперпотока, сокращается вдвое. Оба гиперпотока используют для загрузки своих данных одну и ту же кэш-память. Если рабочий набор для двух потоков неперекрывается, то исходный кожффициент попадания в кэш-память в 95% также может быть сокращен в два раза и, следовательно, будет значительно меньше, чем требуемые 80%.
Следовательно, гиперпотоки полезны только в ограниченном диапазоне случаев. Показатель попаданий кэш-памяти для однопоточного кода должен быть достаточно низким с тем, чтобы учитывая приведенные выше уравнения и уменьшенный размер кэш-памяти, новый показатель попаданий все еще отвечал поставленной цели. Тогда и только тогда вообще будет какой-либо смысл использовать гиперпотоки. Будет ли результат лучше, на практике зависит от того, способен ли процессор перекрыть время ожидания, затраченное в одном потоке, временем исполнения другого потока. К новому общему времени исполнения следует добавить накладные расходы на распараллеливание кода и этими дополнительными расходами не всегда можно пренебречь.
В разделе 6.3.4 мы рассмотрим методики, в которых потоки тесно взаимодействуют друг с другом и непосредственное взаимодействие через общий кэш является, на самом деле, преимуществом. Эту методику можно применять во многих ситуациях, если только программисты готовы потратить время и энергию, чтобы изменить свой код.
Должно быть ясно то, что если в двух гиперпотоках выполняется абсолютно различный код (например, два потока рассматриваются операционной системой как отдельные процессоры для выполнения отдельных процессов), размер кэша действительно сокращается вдвое, что означает значительное увеличение промахов кэш-памяти. Такая практика планирования операционной системы сомнительна в случае, если кэш-память недостаточно большая. Если рабочая нагрузка машины не состоит из процессов, которые в силу своих конструктивных особенностей, могут действительно извлечь выгоду от использования гиперпотоков, может оказаться лучше просто отключить гиперпотоки в BIOS компьютера. {Еще одна причина держать гиперпотоки включенными --- это отладка. Режим SMT удивительно удобен при поиске некоторых проблем, возникающих в параллельном коде}.
3.3.5. Другие детали
До сих пор мы рассматривали адрес, состоящий из трех частей - тега, индекса кэш-набора и смещения кэш-строки. Но какой адрес действительно используется? Во всех рассматриваемых нами современных процессорах реализуется виртуальное адресное пространство процессов, а это значит, что существует два различных типа адресов: виртуальные и физические.
Проблема с виртуальными адресами в том, что они не являются уникальными. Виртуальный адрес может, с течением времени, относятся к разным физическим адресам памяти. Тот же самый адрес в другом процессе также, вероятно, будет относиться к другому физическому адресу. Так что всегда лучше использовать физический адрес памяти, не так ли?
Проблема здесь в том, что инструкции используют виртуальные адреса, и эти адреса должны быть перетранслированы с помощью блока управления памятью (Memory Management Unit - MMU) в физические адреса. Это нетривиальное дело. В конвейере возможность выполнить инструкцию с физическим адресом может появиться только на более позднем этапе. Это означает, что кэш-логика должна быть очень быстрой в случае, когда определяется, какой фрагмент памяти загружается в кэш-память. Если могут использоваться виртуальные адреса, то поиск в кэш памяти нужно выполнять в конвейере как можно раньше и как можно раньше обеспечить, чтобы содержимое памяти попало в кэш-память. В результате большая часть накладных расходов, связанных с доступом к памяти, может стать невидима для конвейера.
Разработчики процессоров используют в настоящее время теги виртуальных адресов для кэш-памяти первого уровня. Эта кэш-памяти достаточно мала и ее можно очистить без особых проблем. Частичное освобождение кэш-памяти необходимо, по крайней мере, в случае, если изменяется дерево таблицы страниц процесса. Можно избежать полного сброса содержимого кэш-памяти в память в случае, если процессор имеет инструкции, в которых задан диапазон изменившихся виртуальных адресов. Если учесть низкую латентность кэш-памяти L1i и L1d ( ~3 циклов), то использование виртуальных адресов является почти обязательным.
Для кэш-памяти большего объема, в том числе и L2, L3, ..., нужно использовать теги физических адресов кэш-памяти. Эта кэш-память имеют более высокую латентность и можно успеть выполнить преобразование виртуальных адресов в физические. Поскольку эта кэш-память имеет больший размер (то есть, теряется много информации, когда содержимое кэш-памяти сбрасывается в основную память) и занесение в нее данных занимает много времени из-за того, что доступ к основной памяти происходит с задержкой, может быть дорого часто сбрасывать информацию из такой кэш-памяти в основную память.
В общем случае нет необходимости знать о деталях обращения к адресам такой кэш-памяти. Их нельзя изменять и все факторы, которые могли бы влиять на производительность, как правило, именно то, чего следует избегать, либо это связано с высокими накладными расходами. Плохо, когда происходит превышение объема кэш-памяти, и в каждой кэш-памяти как можно раньше решаются проблемы, связанные с тем, чтобы большинство используемых кэш-строк попало в тот же самый набор. Последнего можно практически избежать с помощью виртуальной адресации кэш-памяти, но этого нельзя избежать для процессов пользовательского уровне, в которых адресация кэш-памяти осуществляется с помощью физических адресов. Единственное, что следует только помнить, что не следует отображать одно и то же место в физической памяти в два или более виртуальных адреса в одном и том же процессе, даже если это возможно.
Еще одной деталью кэш-памяти, которой программисты интересуются сравнительно мало, это стратегия замены кэш-памяти. В большинстве вариантов кэш-памяти в первую очередь удаляются те элементы, обращение к которым не было дольше всего (Least Recently Used - LRU). Это, по умолчанию, всегда хорошая стратегия. При наличии большей ассоциативности (и ассоциативность, действительно, в связи с добавлением большего количества ядер может в ближайшие годы расти и дальше) ведение списка элементов LRU становится все более и более дорогим, и нам следовало бы рассматривать другие подходящие стратегии.
Что касается смены содержимого кэш-памяти, то здесь программист может сделать не так много. Если в кэш-памяти используются теги физический адресов, то невозможно узнать, как виртуальные адреса коррелируют с кэш-наборами. Вполне может быть, что кэш-строки всех логических страниц будут отображаться в одни и те же кэш-наборы, причем большая часть кэш-памяти использоваться не будет. Во всяком случае, это работа операционной системы и надо добиться, чтобы это не происходило слишком часто.
С появлением виртуализации все становится еще сложнее. Теперь распределение физической памяти контролируется даже не операционной системой. За физическое назначение памяти ответственность несет монитор виртуальных машин (VMM, иначе гипервизор).
Программист-профессионал может сделать следующее: а) полностью использовать логические страницы памяти и б) использовать страницы настолько большого размера, чтобы имело смысл как можно больше варьировать физические адреса. Большие размеры страниц имеют и другие преимущества, но это уже другая тема (смотрите раздел 4).
3.4 Кэш-память инструкций
Кэшируются не только данные, используемые процессором; также кэшируются инструкции, выполняемые процессором. Но с этой кэш-памятью значительно меньше проблем, чем с кэшированием данных. Причины следующие:
- Объем исполняемого кода зависит от требуемого размера кода. Размер кода в целом зависит от сложности решение задачи. Сложность конкретной задачи фиксирована.
- В то время как обработку данных в программе разрабатывает программист, инструкции программы, как правило, генерируются компилятором. Создатели компиляторов знают о правилах генерации хорошего кода.
- Последовательность выполнения инструкций в программе гораздо более предсказуема, чем способы доступа к данным. Современные процессоры очень хорошо выявляют эти способы. Это помогает выполнять предварительную загрузку инструкций.
- Код всегда имеет неплохую пространственную и временную локализацию.
Есть некоторые правила, которым должны следовать программисты, но они, в основном, состоят из правила о том, как пользоваться инструментальными средствами. Мы обсудим их в разделе 6. Здесь мы говорим только о технических особенностях кэш-памяти для инструкций.
После того как частоты работы ядра процессоров резко возросли и увеличилась разница в скорости между кэш-памятью (даже кэш-памятью первого уровня), процессоры стали конвейерными. Это означает, что выполнение инструкций происходит в несколько этапов. Сначала инструкция декодируется, затем подготавливаются параметры и, наконец, инструкция выполняется. Такой конвейер может быть достаточно длинным (более 20 этапов для архитектуры Netburst фирмы Intel). Длинный конвейер означает, что если конвейер остановился (например, прерван проходящий через него поток инструкций), то требуется некоторое время, чтобы снова достичь требуемой скорости. Например, остановка конвейера происходит в случае, если место выполнения следующей инструкции предсказано неправильно, либо если для загрузки следующей инструкции потребуется слишком много времени (например, если она должна быть считана из памяти).
Разработчики процессоров потратили массу времени и состояние по предсказанию ветвлений сейчас таково, что остановка конвейера происходит настолько редко, насколько это возможно.
На процессорах CISC этап декодирования может занять некоторое время. Особенно это видно для процессоров X86 и x86-64. Поэтому в последние годы в этих процессорах последовательности необработанных байтов инструкций в кэш-память L1i не записываются, вместо этого в кэш-память L1i записываются декодированные инструкции. В этом случае кэш-память L1i называется "кэш трассы" ("trace cache"). Кэш трассы в случае попаданий в кэш-память позволяет процессору пропускать первые шаги конвейера, что особенно хорошо в случае, если конвейер останавливается.
Как уже говорилось ранее, кэш-память, начиная от уровня L2, является унифицированной, в которой находятся как код, так и данные. Очевидно, что здесь код кэшируется в виде последовательности байтов и не декодируется.
Есть всего несколько правил, относящихся к кэш-памяти инструкций, которые позволяют достичь наилучшей производительности:
- Нужно генерировать код, который будет иметь наименьший размер. Есть исключения, когда при конвейеризации программы ради использования конвейера приходится создавать дополнительный код или когда при использовании кода небольшого размера слишком высоки накладные расходы.
- Когда это возможно, следует помочь процессору принять правильное решение, связанное с предварительной загрузкой. Это можно сделать при помощи изменения порядка следования кода, либо с помощью явного использования предварительной загрузки.
Этих правил обычно придерживаются при генерации кода с помощью компилятора. Есть несколько вещей, которые может делать программист, и мы будем о них говорить в разделе 6.
3.4.1 Самомодифицирующийся код
В начале эры компьютеров память была дорогой. Люди шли на все, чтобы уменьшить размер программы и оставить больше места для данных. Одним из часто используемых трюков было изменение самой программы по ходу ее исполнения. Такой самомодифицирующийся код (Self Modifying Code - SMC) еще иногда встречается, причем сегодня это связано в основном с задачами повышения производительности или эксплойтами безопасности.
В целом, использование самомодифицирующегося кода следует избегать. Хотя, обычно, он выполняется правильно, есть граничные случаи, в которых это не так, и из-за этого в случае, если код сделан неправильно, возникают проблемы с производительностью. Очевидно, что код, который изменяется, нельзя сохранить в кэше трасс, в котором хранятся декодированные инструкции. Но даже если кэш трасс не используется из-за того, что код вообще не выполнялся (или в течение некоторого времени), в процессоре могут возникнуть проблемы. Если инструкции, которые должны исполняться, изменены после того, как они уже помещены в конвейер, процессор должен отказаться от уже выполненной работы и начать все заново. Есть даже ситуации, когда процессор должен отказаться от большей части работы.
Наконец, поскольку в процессоре для простоты и потому, что это верно в 99,9999999% всех случаев, предполагается, что страницы с кодом не изменяются, при реализации кэш-памяти L1i используется не протокол MESI, а упрощенный протокол SI. Это значит, что если обнаружены изменения, то будут сделаны многие пессимистические предположения.
Настоятельно рекомендуется всегда, когда это можно, избегать использовать самомодифицирующийся код. Память больше не является настолько дефицитным ресурсом. Лучше писать отдельные функции, а не менять одну функции в соответствие с конкретными потребностями. Может быть, однажды появится поддержка самомодифицирующегося кода, и мы сможем обнаруживать коды эксплойтов, которые пытаются подобным образом менять код. Если непременно требуется использовать самомодифицирующийся код, то для того, чтобы не создавать проблем с данными в кэш-памяти L1d, которые потребуются в кэш-памяти L1i, операции записи вообще не должны пользоваться кэш-памятью. Дополнительную информацию, касающуюся этих инструкций, смотрите в разделе 6.1.
Обычно в Linux легко распознать программы, в которых есть самомодифицирующийся код. Когда код программы создается с помощью обычных инструментальных средств, то он весь защищен от записи. Программист должен достаточно поколдовать для того, чтобы создать исполняемый файл, в котором можно выполнять запись в страницы с кодом. Когда происходит, в современных процессорах Intel x86 и x86-64 используются специализированные счетчики, подсчитывающие изменения самомодифицирующегося кода. С помощью этих счетчиков можно просто выявлять программы с самомодифицирующимся кодом даже в случае, когда из-за более слабых ограничений программа будет считаться допустимой.
3.5 Коэффициенты промахов кэш-памяти
Мы уже видели, что когда при доступе к памяти возникают промахи в кэше, накладные расходы резко увеличиваются. Иногда этого избежать не удается, и важно понять, какими будут фактические затраты, и что можно сделать, чтобы смягчить проблему.
3.5.1 Пропускная способность кэш-памяти и основной памяти
Чтобы получить более полное представление о возможностях процессоров, мы измерим пропускную способность в оптимальных условиях. Этот показатель особенно интересен, поскольку различные версии процессоров отличаются друг от друга. По этой причине в данном разделе будут приведены данные, полученные на различных машинах. Для измерения производительности взята программа, в которой используются инструкции SSE процессоров с архитектурой x86 и x86-64, с помощью которых за одно действие выполняется загрузка из памяти или сохранение в памяти 16 байт данных. Рабочий набор увеличивается с 1kB до 512MB точно также, как это было в других наших тестах, и измеряется, сколько байтов данных можно загрузить или сохранить за один цикл.

Рис.3.24: Пропускная способность процессора Pentium 4
На рис.3.24 показана производительность 64-разрядного процессора Intel NetBurst. Для рабочих наборов с примерами, которые помещаются в кэш-память L1d, процессор может прочитать все 16 байтов за один цикл, т. е. за один цикл выполняется одна инструкция загрузки (инструкция movaps перемещает за один раз 16 байтов данных). В тесте ничего не делается с прочитанными данными, мы тестируем только сами инструкции чтения данных. Как только кэш-памяти L1d станет не хватать, производительность резко падает до менее чем 6 байтов за цикл. Порог в 218 байтов связан с исчерпанием кэш-памяти DTLB, что означает дополнительную работу для каждой новой страницы. Поскольку чтение выполняется последовательно, предсказание доступа в предварительной загрузке работает прекрасно, а шина FSB может для всех размеров рабочего набора передавать содержимое памяти в потоке со скоростью 5,3 байта за цикл. Однако предварительная загрузка не распространяется на кэш-память L1d. Это, конечно, значения, которые никогда не будут достижимы в реальной программе. Считайте их практически предельными значениями.
Более удивительной по сравнению с производительностью при чтении является производительность при записи и копировании. Производительность при записи даже для рабочих наборов с небольшими размерами, никогда не поднимается выше 4 байтов за цикл. Это указывает на то, что в таких процессорах Netburst, Intel решила использовать в кэш-памяти L1d режим с прямой записью (Write-Through), при котором скорость, очевидно, ограничена скорость работы кэш-памяти L2. Это также означает, что производительность теста копирования, в котором данные копируются из одной области памяти в другую непересекающуюся области памяти, не намного хуже. Следовательно, требуемые операций чтения выполняются намного быстрее и могут частично перекрываться с операциями записи. Самым интересными деталями измерения записи и копирования является низкая производительность в случае, как только становится мало кэш-памяти L2. Производительность падает до 0,5 байта за цикл! Это значит, что операции записи в десять раз медленнее, чем операции чтения. Это означает, что оптимизация этих операций еще более важна для выполнения программы.
На рис.3.25 мы видим результаты для того же процессора, но с двумя работающими потоками по одному на каждом из двух гиперпотоков процессора.

Рис.3.25: Пропускная способность процессора Pentium 4 с двумя гиперпотоками
Для того, чтобы показать различия, график изображен в том же самом масштабе, что и предыдущий, а кривые немного варьируются просто из-за проблем измерения двух параллельных потоков. Результаты такие, как и ожидалось. Поскольку гиперпотоки совместно используют одни и те же ресурсы кроме регистров, каждый из них может использовать только половину кэш-памяти и половину пропускной способности процессора. Это значит, что, хотя каждый поток может долго находиться в режиме ожидания и предоставлять другому потоку возможность выполняться, это не окажет никакого влияния, поскольку другой поток может также ожидать доступ к памяти. Здесь действительно показан худший вариант использования гиперпотоков.

Рис.3.26: Пропускная способность процессора Core 2
По сравнению с рис.3.24 и 3.25 результаты на рис. 3.26 и 3.27 для процессора Intel Core 2 выглядят совсем иначе. Это двухядерный процессор с совместно используемой кэш-памятью L2, которая в четыре раза больше, чем кэш-память L2 на машине P4. Однако, этим объясняется только более позднее падение производительности при записи и копировании.
Различий гораздо больше. Производительность чтения во всем диапазоне рабочего набора колеблется вокруг оптимального значения 16 байтов за цикл. Падение производительности чтения после значения в 220 байтов опять же объясняется слишком большим размером рабочего набора для DTLB. Получение таких больших значений означает, что процессор не только может выполнять предварительную загрузку данных и осуществлять их своевременную передавать. Это также означает, что предварительная загрузка данных также осуществляется для кэш-памяти L1d.
Производительность записи и копирования также резко отличается. Процессор не использует политику прямой записи (Write-Through); записанные данные хранятся в кэш-памяти L1d и удаляются из нее только когда это необходимо. Это позволяет писать со скоростью, близкой к оптимальной в 16 байт за цикл. Как только оказывается мало кэш-памяти L1d, производительность резко падает. Как и в процессорах Netburst, скорость записи здесь значительно ниже. Благодаря высокой производительности при чтении, различия здесь еще больше. На самом деле, когда становится мало даже кэш-памяти L2, различие в скорости возрастает до 20 раз! Это не означает, что процессоры Core 2 работают плохо. Наоборот, их производительность всегда лучше, чем производительность ядер Netburst.

Рис.3.27: Пропускная способность процессора Core 2 с двумя потоками
На рис.3.27 тестовая программа запускает два потока, по одному для каждого из двух ядер процессора Core 2. Хотя оба потока получают доступ к одной и той же памяти, им не требуется синхронизация. Результаты по производительности чтения не отличаются от однопоточного случая. Видно еще несколько флуктуаций, которые ожидаемы в случае любого многопоточного теста.
Интерес представляет производительность записи и копирования для рабочих наборов с размерами, которые будут вписываться в кэш-память L1d. Как видно на рисунке, производительность такая же, как если бы данные считывались из основной памяти. Оба потока соревнуются за доступ к одному и тому же месту памяти и для кэш-строк должны отправляться сообщения RFO. Проблема состоит в том, что, хотя оба ядра используют общую кэш-память, эти запросы не обрабатываются со скоростью работы кэш-памяти L2. Как только становится недостаточно кэш-памяти L1d, все модифицированные записи удаляются из кэш-памяти L1d и помещаются в общую кэш-память L2. В этот момент производительность значительно возрастает, поскольку теперь промахи L1d разрешаются кэш-памятью L2, а сообщения RFO нужны только тогда, когда данные еще не были сброшены. Вот почему мы видим снижение скорости на 50% для рабочих наборов этих размеров. Асимптотическое поведение такое, как и ожидалось: поскольку оба ядра совместно используют одну и ту же шину FSB, каждое ядро получает половину пропускной способности шины FSB, что означает, что для больших рабочих наборов производительность каждого потока составляет примерно половину от однопоточного случая.
Поскольку имеются значительные различия между версиями процессоров одного производителя, безусловно, стоит также посмотреть на производительность процессоров других производителей. На рис.3.28 показана производительность процессора Opteron серии 10 фирмы AMD. Этот процессор имеет 64kB кэш-памяти L1d, 512kB кэш-памяти L2 и 2MB кэш-памяти L3. Кэш-память L3 является общей для всех ядер процессора. Результаты тестирования производительности можно увидеть на рис.3.28.
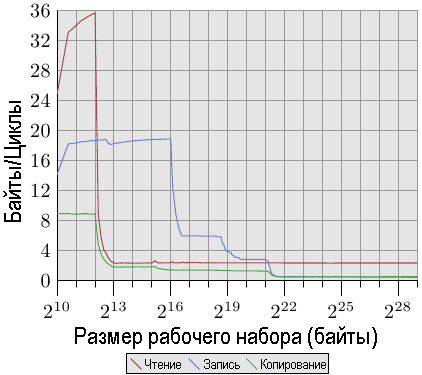
Рис.3.28: Пропускная способность процессора Opteron серии 10 фирмы AMD
Первое, что сразу видно, это то, что если достаточно кэш-памяти L1d, процессор может обрабатывать две инструкции за один цикл. Скорость чтения превышает 32 байта за цикл, а скорость записи даже более высокая - 18,7 байтов за цикл. Кривая чтения быстро выравнивается и становится довольно низкой - 2,3 байта за цикл. Процессор для этого теста не выполняет предварительную загрузку каких-либо данных, по крайней мере, не выполняет ее эффективно.
С другой стороны, кривая записи зависит от размеров кэш-памяти различных уровней. Пиковая производительность достигается до полного заполнения кэш-памяти L1d, уменьшаясь до 6 байтов на цикл для кэш-памяти L2, до 2,8 байта за цикл для кэш-памяти L3 и, наконец, до 0,5 байта за цикл в том случае, если все данные не помещаются даже в кэш-память L3. Производительность для кэш-памяти L1d превышает производительность (более старого) процессора Core 2, доступ к кэш-памяти L2 осуществляется одинаково быстро (в сравнении с Core 2, имеющим больший кэш), а доступ к кэш-памяти L3 и основной памяти происходит медленнее.
Производительность копирования не может быть лучше, чем производительность либо чтения, либо записи. Вот почему мы видим, что первоначально доминирует производительность чтения, а затем --- производительность записи.
На рис. 3.29 показана производительность процессора Opteron для многопоточного случая.

Рис.3.29: Пропускная способность процессора AMD серии 10 с двумя потоками
Производительность чтения осталась, в основном, неизменной. Кэш-память L1d и L2 для каждого потока работают как раньше, а кэш-память L3 в этом случае не выполняет предварительную загрузку достаточно хорошо. Два потока не должны в данном случае чрезмерно загружать кэш-память L3. Большой проблемой в этом тесте является производительности записи. Все данные, которые совместно используются потоками, должны пройти через кэш-память L3. Оказывается, что такое совместное использование весьма неэффективно, поскольку, даже если размер кэш-памяти L3 достаточен для хранения всего рабочего набора, затраты будут существенно выше, чем доступ к L3. Если сравнить этот график с рис.3.27, то мы увидим, что для соответствующего диапазона размеров рабочего набора два потока процессора Core 2 работают на скорости разделяемой кэш-памяти L2. Такой уровень производительности достигается для процессора Opteron только для очень небольшого диапазона размеров рабочего набора и даже здесь она соответствует только скорости кэш-памяти L3, которая работает медленнее, чем кэш-память L2 процессора Core 2.
3.5.2 Загрузка критических слов
Данные передается из основной памяти в кэш-память в блоках, размер которых меньше, чем размер кэш-строки. В настоящее время за один раз можно передать 64 бита данных, а размер кэш-строки составляет 64 или 128 байтов. Это означает, что потребуется 8 или 16 действий передач данных в кэш-строку.
Чипы DRAM могут передавать эти 64-битовые блоки пакетами (burst mode). Это поможет заполнить кэш-строку без дальнейших команд от контроллера памяти и возможных связанных с этим задержек. Когда процессор выполняет предварительную загрузку кэш-строк, то это, пожалуй, наилучший вариант.
Если при доступе в программе к кэш-памяти данных или кэш-памяти инструкций возникает промах (что означает, что это вынужденный промах кэш-памяти из-за того, что данные используются первый раз или недостаточная емкость кэш-памяти, либо из-за того, что ограниченный размер кэша требует удаления кэш-строки), то ситуация иная. Слово, находящееся в кэш-строке, которое требуется программе для продолжения работы, может оказаться не первым словом в кэш-строке. Даже в режиме передачи данных пакетами (burst mode) и с двойной скоростью передачи данных, отдельные 64-разрядные блоки оказываются на месте за заметно разное время. Каждый блок поступает после поступления предыдущего блока через 4 процессорных циклов или более. Если слово, которое нужно для продолжения работы программы, будет восьмым в кэш-строке, то после того, как поступит первое слово, программа должна ждать еще 30 циклов или более.
Ситуация не обязательно должна быть именно такой. Контроллер памяти может запрашивать слова кэш-строк в другом порядке. Процессор может определить, какое слово, оно будет называться критическим словом, ожидает программа, и контроллер памяти может запросить это слово в первую очередь. Как только это слово поступает, программа может продолжать работу, хотя остальная часть кэш-строки еще не поступила и находится в несогласованном состоянии. Эта методика называется предварительно ранней перезагрузкой критического слова (Critical Word First & Early Restart).
В настоящее время в процессорах используется эта методика, но бывают ситуации, когда ее использовать невозможно. Если процессор выполняет предварительную загрузку и ему не известно критическое слово. В случае, когда процессор запрашивает кэш-строки в процессе выполнения операции предварительной загрузки, ему приходится ждать, когда поступит критическое слово, и у него нет возможности повлиять на порядок загрузки.
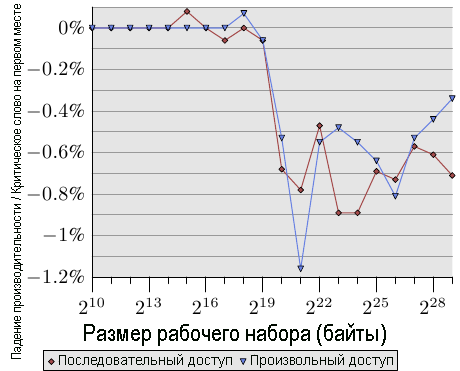
Figure 3.30: Critical Word at End of Cache LineРис.3.30: Критическое слово в конце кэш-строки
Даже при такой оптимизации имеет значение то, где в кэш-строке находится критическое слово. На рис.3.30 показан результат работы теста Follow для последовательного и случайного доступа. Показано замедление выполнения теста для случая, когда указатель находится в первом слове, по сравнению с ситуацией, когда указатель находится в последнем слове. Размер элемента равен 64 байта, что соответствует размеру кэш-строки. Значения сильно зашумлены, но видно, что как только кэш-памяти L2 становится недостаточным для того, чтобы хранить рабочий набор, производительность для случая, когда критическое слово находится в конце кэш-строки, будет приблизительно на 0,7% меньше. Похоже, что при последовательном доступе влияние немного больше. Когда происходит предварительная загрузка следующей кэш-строки, описанная выше проблема не исчезает.
3.5.3 Место размещения кэш-памяти
То, где относительно гиперпотоков, ядер и процессоров размещается кэш-память, выходит за рамки контроля программиста. Но программисты могут определить, где выполняются потоки, а затем, а это становится важным, как кэш-память соотносится с используемыми процессорами.
Здесь мы не будем вдаваться в подробности о том, как выбрать, какие ядра будут запускать потоки. Мы опишем только архитектурные детали, которые при настройке потоков программист должен принимать во внимание.
Гиперпотоки, по определению, использую совместно все ресурсы, кроме набора регистров. К этим ресурсам также относится кэш-память L1. Здесь об этом мало что можно сказать. Самое интересное начинается с отдельными ядрами процессора. Каждое ядро имеет, по крайней мере, свою собственную кэш-память L1. На сегодняшний день других конкретных особенностей, кроме этой, вообще не так много:
- Первые многоядерные процессоры имели отдельную кэш-память L2 и не имели кэш-память более высокого уровня.
- Более поздние модели Intel имели общую кэш-память L2, используемую в двухядерных процессорах. Для четырехядерных процессоров мы имеем дело с отдельной кэш-памятью L2 для каждой пары из двух ядер. Кэш-памяти более высокого уровня нет.
- Процессоры AMD серии 10 имеют отдельную кэш-память L2 и единую кэш-память L3.
Поставщиками процессоров было написано много пропагандистских материалов о преимуществе своих моделей. Отдельная кэш-память L2 дает преимущество в случае, если рабочие наборы, обрабатываемые отдельными ядрами, не перекрываются. Это хорошо работает в однопоточных программах. Поскольку однопоточные программы являются реалиями сегодняшнего дня, такой подход не слишком плох. Но некоторые перекрытия есть всегда. В кэш-памяти всегда находятся наиболее активно используемые части общих библиотек времени выполнения, что означает, что некоторое пространство кэш-памяти расходуется впустую.
Вся кэш-память, уровень которой ниже L1, является полностью разделяемой, что дает двухядерным процессорам фирмы Intel действительно большое преимущество. Если рабочий набор в потоках, работающих на двух ядрах, существенно перекрывается, то общий объем доступной кэш-памяти становится большим и рабочие наборы могут быть большего размера без потери производительности. Если рабочие наборы не не перекрываются, то интеллектуальная система управления кэш-памятью Advanced Smart Cache фирмы Intel должна предотвращать ситуацию, когда одно ядро может монополизировать всю кэш-память.
Но если оба ядра используют для своих рабочих наборов около половины кэш-памяти, то имеются некоторые потери. Кэш-память должна постоянно оценивать использование кэш-память двумя ядрами и освобождение, осуществляемое как часть такого балансирования, может выбираться неудачно. Чтобы рассмотреть проблему, мы посмотрим на результаты работы еще одной тестовой программы.

Рис.3.31: Пропускная способность при наличии двух процессов
В тестовой программе имеется один процесс, который постоянно читает или записывает с помощью инструкций SSE блоки памяти размером в 2MB. Размер в 2MB был выбран потому, что это в два раза меньше размера кэш-памяти L2 процессора Core 2. Процесс выполняется одним ядром, а за вторым ядром закреплен второй процесс. Этот второй процесс читает и записывает области памяти произвольного размера. На графике показано, сколько байтов за цикл читается или записывается. Изображены четыре различных графика --- по одному для каждой комбинации чтения и записи. Для графика чтения / записи фоновый процесс, который всегда использует рабочий набор размером 2MB, всегда выполняет запись, а измеряемый процесс, использующий рабочие наборы переменного размера, выполняет чтение.
Интересной является часть графика, расположенная между байтами 220 и 223. Если бы кэш-память L2 обоих ядер была бы полностью отдельной, то мы могли бы ожидать, что производительность всех четырех тестов упала между байтами 221 и 222, что означало бы, что кэш-память L2 исчерпана. Как видно на рис.3.31 это не так. Лучше всего это видно, когда фоновый процесс выполняет запись. Производительность начинает ухудшаться раньше, чем размер рабочего набора достигает 1MB. Эти два процесса не используют совместную память, поэтому не должны генерироваться сообщения RFO. Это проблемы исключительно освобождения кэш-памяти. В интеллектуальной системе управления кэш-памятью есть свои проблемы, с эффектом, который, как видно на примере, проявляется ближе к значению 1MB, а не к 2MB, которое доступно в каждом ядре. Можно только надеяться, что, если в будущих процессорах останется совместное использование кэш-памяти несколькими ядрами, алгоритм, применяемый в интеллектуальной системе управления кэш-памятью, будет исправлен.
Четырехядерный процессор с двумя кэшами уровня L2 был всего лишь временным решением, использовавшимся прежде, чем был введен кэш более высокого уровня. Такая конструкция не дает существенных преимуществ по сравнению с процессорами с отдельными подключениями и двумя ядрами. Два ядра взаимодействуют через ту же шину, которая, если смотреть извне, является шиной FSB. Какой-либо специальный механизм ускоренного обмена данными отсутствует.
Будущее дизайна кэш-памяти для многоядерных процессоров будет представлять собой добавление уровней. Старт был дан серией 10 процессора AMD. Еще предстоит выяснить, увидим ли мы кэш-память еще более низкого уровня, которая будет совместно использоваться некоторым подмножеством ядер процессора. Дополнительные уровни кэш-памяти необходимы, поскольку высокоскоростная и часто используемая кэш-память не может совместно использоваться большим количеством ядер. Это повлияет на производительность. Для этого также потребуется кэш-память очень большого размера с высокой ассоциативностью. Оба значения, размер кэш-памяти и ассоциативность, должны увеличиваться вместе с увеличением числа ядер, совместно использующих кэш-память. Разумным компромиссом является использование кэш-памяти L3 большого размера и кэш-памяти L2 разумного размера. Кэш-память L3 работает медленнее, но, в идеале, она используется не так часто, как кэш-память L2.
Для программистов все эти различия в дизайне усложняют принятие решений. Чтобы достичь наилучшей производительности, нужно знать, какова будет нагрузка, а также нужно знать особенности архитектуры машины. К счастью, у нас есть возможность определения архитектуры машины. Интерфейсы будут представлены в следующих разделах.
3.5.4 Влияние шины FSB
Шина FSB играет ключевую роль в производительности машины. Содержимое кэш-памяти может быть сохранено и загружено настолько быстро, насколько позволяет подключение к памяти. Мы можем это показать, запустив программу на двух машинах, которые отличаются только скоростью работы их модулей памяти. На рис.3.32 показаны результаты теста Addnext0 (добавление содержимого элемента pad[0] следующих элементов списка к pad[0] текущего элемента) для NPAD = 7 на 64-разрядной машине. В обеих машинах используются процессоры Intel Core 2, в первой машине используются модули памяти DDR2 с частотой 667 МГц, во второй - 800 МГц (больше на 20%).

Рис.3.32: Влияние скорости шины FSB
Цифры показывают, что когда по шине FSB действительно пересылаются рабочие наборы большого размера, мы действительно видим большую производительность. Максимальное увеличение производительности, измеренное в этом тесте, составляет 18,2%, что близко к теоретическому максимуму. Это говорит о том, что более быстрая шина FSB действительно может сэкономить время. Это не так важно, когда рабочий набор помещается в кэш-память (и в этих процессорах есть 4MB кэш-памяти уровня L2). Следует иметь в виду, что здесь мы измеряем работу только одной программы. В рабочий набор системы входит вся та память, которая нужна для всех одновременно запущенных процессов. Таким образом, размер памяти в 4MB или более может быть легко превышен существенно меньшими программами.
Сегодня некоторые из процессоров Intel поддерживают частоту шины FSB до 1333 МГц, что означает увеличение производительности еще на 60%. В будущем можно будет увидеть даже более высокие скорости. Если важна скорость и размер рабочего набора большой, то быстрая оперативная память и высокоскоростная шина FSB, безусловно, стоит затрачиваемых денег. Однако нужно быть внимательным, так как несмотря на то, что процессор будет поддерживать более высокие скорости шины FSB, материнская плата / северный мост могут не поддерживать подобную скорость. Внимательно изучайте спецификации.
4 Виртуальная память
Подсистема виртуальной памяти процессора реализует виртуальное адресное пространство для каждого процесса. Это позволяет каждому процессу думать, что он один в системе. Детальное описание преимуществ виртуальной памяти можно найти где угодно и здесь мы не будем его повторять. Вместо этого в этом разделе мы сосредоточимся на актуальных деталях реализации подсистемы виртуальной памяти и связанных с этим издержках.
Виртуальное адресное пространство реализовано блоком управления памяти (MMU - Memory Management Unit) процессора. Операционная система должна заполнить структуры данных таблицы страниц, но большинство процессоров делают остальную часть работы сами. Это на самом деле довольно сложный механизм. Наилучший способ понять его - это изучить структуры данных, используемые для описания виртуального адресного пространства.
Исходной информацией для преобразования адресов, выполняемого MMU, является виртуальный адрес. Обычно существует немного, если есть вообще, ограничений на его значение. Виртуальные адреса - это 32-битные значения в 32-битных системах и 64-битные значения в 64-битных системах. В некоторых системах, например в x86 и x86-64, используемый адрес включает еще один уровень переадресации: эти архитектуры используют сегменты, которые просто задают смещение, добавляемое к каждому логическому адресу. Мы можем игнорировать эту часть генерации адресов, она тривиальна и это не то о чем должен заботиться программист, думающий о производительности работы с памятью. (Ограничения сегментов в x86 влияют на производительность, но это уже другая история.)
4.1 Простейшее преобразование адресов
Интересная часть - преобразование виртуального адреса в физический. MMU может преобразовывать адрес постранично. Также как со строками процессорного кэша, виртуальный адрес разделяется на части. Эти части используются как индексы различных таблиц, которые в свою очередь используются для построения окончательного физического адреса. Для простейшей модели мы имеем только один уровень таблиц.

Рисунок 4.1: Одноуровневое преобразование адресов
Рисунок 4.1 показывает, как используются различные части виртуального адреса. Старшие разряды используются для выбора записи в каталоге страниц. Каждая запись в этом каталоге может быть индивидуально установлена операционной системой. Запись каталога страниц определяет адрес физической страницы памяти. На одну физическую страницу могут указывать несколько записей каталога страниц. Полный физический адрес ячейки памяти определяется как комбинация адреса страницы из каталога страниц с младшими битами виртуального адреса. Запись каталога страниц также содержит некоторую дополнительную информацию о странице, такую как разрешения на доступ.
Структура данных каталога страниц хранится в памяти. Операционная система должна выделить непрерывный участок памяти и сохранить базовый адрес этого участка в специальном регистре. Подходящие биты виртуального адреса затем используются как индекс каталога страниц, который является массивом записей каталога.
Конкретным примером может служить модель, используемая для страниц размером 4Мб на x86 машинах. Часть "смещение" виртуального адреса имеет размер 22 бита, как раз достаточный для адресации каждого байта в странице размером 4Мб. Оставшиеся 10 бит виртуального адреса выбирают одну из 1024 записей каталога страниц. Каждая запись содержит 10 бит базового адреса страницы размером 4Мб, что вместе со "смещением" дает полный 32-битный адрес.
4.2 Многоуровневые таблицы страниц
Страницы размером 4Мб не являются нормой. Они бы расходовали много лишней памяти, так как многие операции, которые выполняет операционная система, требуют выравнивания страниц памяти. Со страницами размером 4Кб (норма для 32-битных машин и все еще часто для 64-битных) часть виртуального адреса "смещение" имеет размер всего 12 бит. Это оставляет 20 бит для выбора из каталога страниц. Таблица с 220 записями непрактична. Даже если каждая запись будет размером всего 4 байта, размер таблицы будет 4Мб. Тогда большая часть физической памяти системы будет отдана на таблицы страниц, так как каждый процесс может иметь свою таблицу страниц.
Решение состоит в использовании нескольких уровней таблицы страниц. Они могут представлять огромный разреженный каталог страниц, где неиспользуемые регионы не требуют выделения памяти. Следовательно, представление намного более компактное и есть возможность для многих процессов в памяти иметь каталоги страниц без существенного влияния на производительность.
Сегодня наиболее сложные структуры таблиц страниц содержат 4 уровня. Рисунок 4.2 показывает схему такой структуры.

Рисунок 4.2: 4-уровневое преобразование адресов
Виртуальный адрес в этом примере разбит, по крайней мере, на 5 частей. 4 части являются индексами различных каталогов. Для ссылок на каталог 4-го уровня используется специальный регистр процессора. Содержимое каталога на уровнях с 4 по 2 - это ссылки на каталог уровня ниже на единицу. Если запись каталога помечена как пустая, она очевидно не должна указывать на низлежащий каталог. За счет этого достигается разреженность и компактность дерева таблиц страниц. Записи каталога уровня 1 - это часть физического адреса плюс дополнительные данные как, например, разрешения на доступ.
Чтобы определить физический адрес, соответствующий виртуальному адресу, процессор сначала определяет адрес наивысшего уровня в каталоге. Этот адрес обычно хранится в регистре. Затем процессор берет часть виртуального адреса, соответствующую индексу этого каталога, и использует этот индекс, чтобы выбрать подходящую запись. Эта запись - адрес следующего каталога, который проиндексирован с помощью следующей части виртуального адреса. Этот процесс продолжается, пока не достигнет каталога уровня 1, где значение записи каталога - это старшие разряды физического адреса. Младшие разряды физического адреса берутся из битов "смещения" виртуального адреса. Этот процесс называется прогулкой по дереву страниц. Некоторые процессоры (как x86 и x86-64) выполняют эту операцию аппаратно, другие прибегают к помощи операционной системы.
Каждому запущенному в системе процессу, возможно, понадобится собственное дерево таблиц страниц. Частичное разделение деревьев возможно, но это скорее исключение. Следовательно, для производительности и масштабируемости предпочтительно, чтобы память, отведенная под деревья таблиц страниц, была как можно меньше. Идеальный случай для этого, если используемая память расположена компактно в виртуальном адресном пространстве; какие именно физические адреса используются - значения не имеет. Маленькая программа может обойтись использованием на уровнях 2,3,4 только по одному каталогу и несколькими каталогами на уровне 1. На x86-64 со страницами размера 4Кб и 512 записями в каталоге это позволяет адресовать 2Мб с помощью 4-х каталогов (по одному на каждом уровне). 1Гб непрерывной памяти может быть адресован, используя по одному каталогу на уровнях со 2-го по 4-й и 512 каталогов на уровне 1.
Однако предполагать, что вся память может быть выделена одним куском, будет слишком большим упрощением. Из соображений гибкости области стека и кучи процесса в большинстве случаев выделяются на противоположных концах адресного пространства. Это позволяет каждой области при необходимости расти так как только возможно. Это означает, что скорее всего, будет 2 каталога на уровне 2 и соответственно больше каталогов на низлежащем уровне.
Но даже этот случай не всегда имеет место на практике. Из соображений безопасности различные части исполняемого процесса (код, данные, куча, стек, разделяемые библиотеки) отображаются на случайно выбранные (рандомизированные) адреса (см. [1]). Рандомизации подвергается относительное расположение разных частей, из этого следует, что используемые участки памяти могут быть в любой части виртуального адресного пространства. Если рандомизировать только несколько битов адреса, можно ограничить область, в которой находятся используемые участки виртуального адресного пространства; но, конечно, в большинстве случаев невозможно ограничить процесс использованием только одного или двух каталогов на уровнях 2 и 3.
Если производительность намного важнее безопасности, рандомизация может быть отключена. Тогда операционная система обычно, по крайней мере, загружает все исполняемые библиотеки в виртуальную память одним непрерывным куском.
4.3 Оптимизация доступа к таблицам страниц
Все структуры данных таблиц страниц хранятся в основной памяти, там операционная система создает и обновляет страницы. При создании процесса или изменении таблицы страниц оповещается процессор. Таблицы страниц, используемые для преобразования любого виртуального адреса в физический адрес методом прогулки по дереву таблиц страниц, описаны выше. Более того, показано, что в процессе нахождения адреса используется, по крайней мере, один каталог на каждом уровне преобразования адреса. Это требует до четырех обращений к памяти (за одно обращение к работающему процессу), что конечно медленно. Можно обращаться с записями каталогов таблиц как с обычными данными и кэшировать их в L1d, L2 и т. д., но все равно это будет медленно.
С ранних дней применения виртуальной памяти разработчики процессоров используют другую оптимизацию. Простое вычисление может показать, что только хранение записей каталогов таблиц в L1d и в более высоком кэше приведет к ужасным результатам. Вычисление каждого абсолютного адреса потребует многочисленного обращения к L1d в соответствии с глубиной таблицы страниц. Эти обращения не могут быть распараллелены, так как они зависят от результатов предыдущего поиска. Это одно потребует, по крайней мере, 12 циклов на машине с четырьмя уровнями таблиц страниц. Добавьте к этому вероятность непопадания в L1d, и никакой конвейер команд не сможет скрыть результат. Дополнительные обращения к L1d также расходуют драгоценную пропускную способность кэша.
Вместо кэширования записей таблицы каталогов кэшируется всё вычисление адреса физической страницы. Такое кэширование работает по той же причине, по какой работает кэширование данных и кода. Так как часть виртуального адреса "смещение" не участвует в вычислении адреса физической страницы, только оставшаяся часть виртуального адреса используется как тег кэша. В зависимости от размера страницы это означает, что сотни или даже тысячи инструкций или объектов данных разделяют один и тот же тег и, следовательно, префикс физического адреса.
Кэш, в котором хранятся вычисленные значения, называется "буфер ассоциативного преобразования адресов" (TLB - Translation Look-Aside Buffer). Обычно это маленький кэш, так как он должен быть очень быстрым. Современные процессоры имеют многоуровневые TLB кэши. Также как и для обычного кэша, чем больше номер кэша, тем он больше и медленнее. Часто маленький размер L1TLB задается преднамеренно, для того, чтобы сделать кэш полностью ассоциативным с политикой удаления страниц, которые дольше всего не использовались (LRU - least recently used). В настоящее время размеры таких кэшей увеличиваются, и они перестают быть ассоциативными. Как результат, может получиться, что при добавлении новой записи исключается не самая старая запись.
Как отмечалось ранее, тэг, используемый для доступа к TLB, - это часть виртуального адреса. Если тэг найден в кэше, окончательное значение физического адреса вычисляется добавлением смещения внутри страницы, взятым из виртуального адреса, к кэшированному значению. Это очень быстрый процесс. Он должен быть таким, так как физический адрес должен быть доступен любой инструкции, использующей абсолютные адреса, и в некоторых случаях запросам к L2, которые используют физический адрес как индекс. Если запрос к TLB заканчивается неудачей, процессор должен выполнить алгоритм прогулки по дереву таблиц страниц, что может быть довольно затратно.
Предварительная выборка кода или данных программно или аппаратно может повлечь предварительную выборку записей в TLB, если адрес находится на другой странице. Этого нельзя допускать для аппаратной предварительной выборки, так как это может инициировать ошибочные прогулки по таблицам страниц. Программисты, следовательно, не должны полагаться на аппаратную предварительную выборку для предварительной выборки записей в TLB. Это должно быть сделано явно, используя инструкции предварительной выборки. Кэши TLB, также как и кэши данных и кода, могут появляться на нескольких уровнях. Также как кэш данных, TLB обычно появляется в двух разновидностях: TLB для кода (ITLB - instruction TLB) и TLB для данных (DTLB - data TLB). TLB с более большими номерами, такие как L2TLB, обычно объединены, как и в случае с обычным кэшем.
4.3.1 Пояснения к использованию TLB
TLB - это глобальный ресурс ядра процессора. Все потоки и процессы, выполняемые в ядре, используют один TLB. Так как преобразование виртуального адреса в физический зависит от того, какое загружено дерево таблиц страниц, процессор не может слепо продолжать использовать кэшированные записи, если таблица страниц поменялась. Каждый процесс имеет своё дерево таблиц страниц (но не потоки одного процесса), также как и ядро ОС и монитор виртуальной машины (Virtual Machine Monitor, VMM), если таковой имеется. Также возможно изменение конфигурации адресного пространства процесса. Есть два подхода к решению этой проблемы:
- TLB очищается при каждом изменении дерева таблиц страниц.
- В тэги TLB добавляется информация так, чтобы можно было однозначно определить, на какое дерево таблиц страниц ссылается тэг.
В первом случае TLB очищается при каждом переключении контекста. Так как в большинстве ОС переключение с одного потока/процесса на другой требует выполнения некоторого кода ядра ОС, очищение TLB происходит при входе и выходе из адресного пространства ядра ОС. На виртуализованных системах это случается также, когда ядро ОС вызывает VMM, и по пути назад. Если ядро ОС и/или VMM не обязано использовать виртуальный адрес, или может использовать тот же виртуальный адрес, что и процесс или ядро, которое сделало вызов системы/VMM, TLB очищается только если покидая ядро ОС или VMM процессор начинает выполнение другого процесса или ядра.
Очищение TLB эффективно, но затратно. Например, когда ядро ОС выполняет системный вызов, его код может быть ограничен несколькими тысячами инструкций, которые затрагивают небольшое количество новых страниц (или одну огромную страницу, в случае использования Linux на некоторых архитектурах). Это заставит поменять ровно столько записей TLB, сколько новых страниц использовано. Для архитектуры Intel Core2, которая имеет 128 записей ITLB и 256 ITLB, полное очищение означает, что более 100 и 200 записей соответственно будут удалены без необходимости делать это. Когда система вернется к этому процессу снова, эти записи могут понадобиться, но их уже не будет. То же самое верно для часто используемого кода ядра ОС или VMM. При каждом входе в ядро ОС TLB придется заполнять заново, хотя таблицы страниц для ядра ОС или VMM обычно не изменяются и, следовательно, в теории, могут храниться очень долгое время. Это также объясняет, почему кэши TLB в современных процессорах не такие большие: программы, скорее всего, не будут работать настолько долго, чтобы заполнить все эти записи.
Этот факт, конечно, не ускользнул от разработчиков процессоров. Одно из возможных решений - использовать выборочное удаление записей для оптимизации очищения кэша. Например, если код и данные ядра ОС попадают в некоторый диапазон адресов, то из TLB удаляются только страницы из этого диапазона. Это требует только сравнения тэгов и, следовательно, не очень затратно. Этот метод также полезен в случае, когда изменяется только часть адресного пространства, например через вызов munmap.
Намного лучшим решением будет расширить тэг, используемый для доступа к TLB. Если к части виртуального адреса будет добавлен уникальный идентификатор дерева таблиц страниц (например адресного пространства процесса), то TLB можно будет полностью не очищать. Ядро ОС, VMM, и процессы могут иметь уникальные идентификаторы. Единственная трудность здесь это то, что количество бит, доступных для тэга TLB жестко ограничено, тогда как число адресных пространств нет. Это значит, что некоторые идентификаторы придется переназначать. Когда такое происходит, TLB должен быть частично очищен (если это возможно). Все записи с переназначенным идентификатором должны быть удалены, но их, скорее всего, будет очень мало.
Это расширение тэгов TLB имеет общее преимущество когда в системе запущено много процессов. Если объем памяти (и, следовательно, количество записей TLB) для каждого процесса ограничен, то велика вероятность того, что последние по времени использования записи TLB для процесса будут все ещё в TLB, когда они понадобятся. И ещё два дополнительных преимущества:
- Специальные адресные пространства, такие как у ядра ОС и VMM, часто используются только на короткое время, после чего управление обычно передается адресному пространству, которое инициировало вызов. Без тэгов было бы выполнено два очищения TLB. С тэгами преобразование адресов вызывающего адресного пространства сохраняется и, так как адресные пространства ядра ОС и VMM не часто изменяют записи TLB, преобразования адресов предыдущих системных вызовов и т.д. могут быть снова использованы.
- При переключении между потоками одного процесса очищение TLB не нужно вообще. Без расширенных тэгов TLB, вход в ядро ОС уничтожит записи в TLB первого потока.
На некоторых процессорах такие расширенные тэги уже стали появляться. AMD представило 1-битное расширение тэга на платформе аппаратной виртуализации Pacifica. Этот 1-битный идентификатор адресного пространства (ASID - Address Space ID) используется в контексте виртуализации, чтобы отличать адресное пространство VMM от адресных пространств гостевых операционных систем. Это позволяет ОС избежать удаления из TLB записей гостевой операционной системы каждый раз, когда управление передается VMM (например, при ошибке страницы) или записей VMM, когда управление возвращается гостевой операционной системе. Эта архитектура позволит использовать больше бит в будущем. Другие наиболее распространенные процессоры, скорее всего, также будут поддерживать это свойство.
4.3.1 Влияние на производительность TLB
Есть пара факторов, которые влияют на производительность TLB. Первый - это размер страниц. Очевидно, что чем больше страница, тем больше попадает в неё инструкций или объектов данных. Таким образом, больший размер страницы сокращает общее число необходимых преобразований адресов, что означает, что можно обойтись меньшим числом записей в кэше TLB. Большинство архитектур позволяют использовать разные размеры страниц. Некоторые размеры могут быть использованы одновременно. Например, процессоры 86/x86-64 имеют нормальный размер страницы 4Кб, но могут также использовать страницы размером 4Мб и 2Мб соответственно. IA-64 и PowerPC позволяют использовать в качестве базового размера страницы значение 64Кб.
Однако использование страниц большого размера несет в себе и некоторые проблемы. Область памяти, используемая для большой страницы, должна располагаться в памяти одним непрерывным куском. Если увеличить размер блока при администрировании физической памяти до размера страницы виртуальной памяти, то потери памяти будут расти. Все виды операций с памятью (например загрузка исполняемого кода) требуют выравнивания границ страниц. Это означает, что в среднем при каждом выделении памяти будет теряться половина размера страницы физической памяти. Эти потери легко могут накапливаться, что задает ограничение сверху на размер блока физической памяти.
Определенно можно сказать, что будет непрактично увеличивать размер блока до 2Мб на x86-64, чтобы получить большие страницы. Это слишком большой размер. Но это в свою очередь означает, что каждая большая страница должна состоять их множества маленьких страниц. Все эти страницы должны располагаться рядом в физической памяти. Выделение 2Мб непрерывной физической памяти может быть сложной задачей при размере блока 4Кб. Для этого требуется найти свободное пространство из 512 страниц, расположенных рядом. Это может быть очень сложно (или даже невозможно) после того как система работает некоторое время и физическая память фрагментирована.
На Linux, следовательно, нужно выделить эти большие страницы во время старта системы, используя специальную файловую систему hugetlbfs. Фиксированное количество физических страниц будут зарезервированы исключительно для использования в качестве больших виртуальных страниц. Это связывает ресурсы, которые могут вообще остаться неиспользованными. Их к тому же ограниченное количество - чтобы его увеличить потребуется перезагрузка. Но все равно это выход в ситуации, когда производительность на первом месте, ресурсов хватает, а долгая загрузка не страшна. Примером могут служить серверы баз данных.
Увеличение минимального размера виртуальной страницы (как альтернатива опциональному использованию больших страниц) тоже имеет свои проблемы. Операции, связанные с распределением памяти (например загрузка приложения), должны быть согласованы с этим размером страниц. Выделение памяти меньшего размера невозможно. Расположение различных частей исполняемого файла для большинства архитектур фиксировано. Если размер страницы увеличен больше того предела, на который ориентировались при компиляции исполняемого файла или библиотеки, загрузка будет невозможна. Важно держать это ограничение в голове. Рисунок 4.3 показывает, как можно определить требования к выравниванию по виду файла формата ELF. Это закодировано в его заголовке.
$ eu-readelf -l /bin/ls
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
...
LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x0132ac 0x0132ac R E 0x200000
LOAD 0x0132b0 0x00000000006132b0 0x00000000006132b0 0x001a71 0x001a71 RW 0x200000
...
Рисунок 4.3: Заголовок ELF, указывающий на требования к выравниванию
В этом примере бинарника на x86-64 значение выравнивания 0x200000 = 2,097,152 = 2Мб соответствует максимальному размеру страницы, поддерживаемому процессором.
Есть второй эффект от использования страниц большего размера - число уровней дерева таблиц страниц сокращается. Так как часть виртуального адреса, соответствующая смещению внутри страницы возрастает, остается не так много бит, которые требуется распределить по каталогам страниц. Это означает, что в случае отсутствия нужной записи в TLB, количество необходимой работы сократится.
Кроме использования большого размера страниц, возможно сократить необходимое количество записей TLB, перемещая данные, которые используются одновременно, на меньшее количество страниц. Это похоже на некоторые оптимизации кэша, о которых упоминалось ранее. Только теперь выравнивание большего размера. Учитывая, что количество записей TLB довольно мало, это может быть очень важной оптимизацией.
4.4 Значение виртуализации
Витруализация образов ОС становится все более распространенной. Это означает, что к картинке добавляется ещё один уровень работы с памятью. Виртуализация процессов (в основном jail) или контейнеры ОС не попадают в эту категорию, так как задействована только одна ОС. Такие технологии как Xen или KVM позволяют использовать ( с помощью или без помощи процессора) независимые образы ОС. В этих случаях есть только одно приложение, которое напрямую управляет доступом к физической памяти.
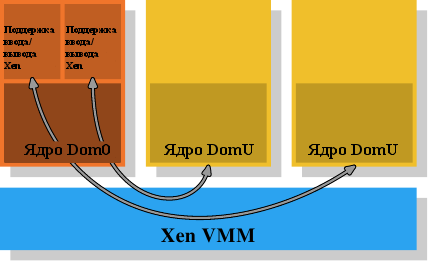
Рисунок 4.4: Модель виртуализации Xen
В случае Xen таким приложением является Xen VMM. Хотя VMM не реализует управление большой частью аппаратного обеспечения само. На более ранних системах (и на первом релизе Xen VMM) все аппаратное обеспечение, кроме процессора и памяти управлялось привилегированным доменом Dom0. Сейчас это в основном такое же ядро, как непривилегированные ядра DomU, и, когда речь идет об управлении памятью, они не различаются. Важно здесь то, что VMM выделяет физическую память для ядер Dom0 и DomU, которые реализуют обычное управление памятью, как если бы они работали непосредственно на процессоре.
Чтобы было реализовано разделение доменов, которое требуется для полной виртуализации, процессы управления памятью в ядрах Dom0 и DomU не имеют неограниченного доступа к физической памяти. VMM в XEN распределяет память не путем выдачи отдельных физических страниц и предоставления гостевой ОС права управлять адресацией; тогда не было бы никакой защиты от неисправных и вредоносных гостевых доменов. Вместо этого VMM создает для каждого гостевого домена его собственное дерево таблиц страниц и выделяет память, используя эти структуры. Преимущество такого способа в том, что доступ к административной информации дерева таблиц страниц можно контролировать. Если код не имеет соответствующих привилегий, он не сможет ничего сделать.
Этот контроль доступа применяется в виртуализации Xen независимо от того, какая используется виртуализация - аппаратная (или полная) или паравиртуализация. Гостевые домены строят деревья таблиц страниц для каждого процесса способом, который намеренно сделан практически идентичным для аппаратной и паравиртуализации. Всякий раз, когда гостевая ОС модифицирует таблицу страниц, вызывается VMM. VMM затем использует обновленную информацию из гостевого домена, чтобы обновить свои собственные теневые таблицы страниц. Это как раз те таблицы страниц, которые используются аппаратным обеспечением. Очевидно, что этот процесс довольно затратен: каждая модификация дерева таблиц страниц требует вызова VMM. Изменения в выделении памяти недешевы и без виртуализации, теперь они ещё затратнее.
Дополнительная стоимость может быть действительно высока, принимая во внимание, что сами по себе переходы из гостевой ОС в VMM и обратно имеют высокую стоимость. Вот почему процессоры стали получать дополнительную функциональность, позволяющую избежать создания теневых таблиц страниц. Это не только увеличивает скорость, но и сокращает количество памяти, потребляемой VMM. У Intel есть технология Extended Page Tables (EPTs), у AMD технология Nested Page Tables (NPTs). В обеих технологиях гостевые ОС создают виртуальный физический адрес. Затем адрес должен быть преобразован, используя для каждого домена своё EPT/NPT дерево, в настоящий физический адрес. Это позволяет работать с памятью на скорости, близкой к невиртуализованному случаю, так как большинство записей VMM для работы с памятью удалено. Это также снижает количество памяти, потребляемой VMM, так как теперь нужно поддерживать только одно дерево таблиц страниц на каждый домен (а не на каждый процесс).
Результаты дополнительного преобразования адресов также хранятся в TLB. Это означает, что TLB хранит не виртуальный физический адрес, а полный результат поиска. Как уже было сказано, технология компании AMD Pacifica использует ASID для каждой записи, чтобы избежать очищения TLB. Количество бит для ASID равно 1 в первоначальном релизе технологии, этого как раз достаточно, чтобы отличать VMM и гостевые ОС. Intel использует идентификаторы виртуального процессора (VPIDs - virtual processor IDs), которые служат той же цели, только их больше. VPID закреплен за каждым гостевым доменом и, следовательно, также не может быть использован для разделения процессов и предотвращения очищения TLB на этом уровне.
Одна из проблем виртуализации операционных систем - это количество работы, необходимое для модификации каждого адресного пространства. Есть, однако, еще одна проблема, присущая виртуализации, основанной на VMM: неизбежно использование двух уровней работы с памятью. Но работа с памятью тяжела (особенно если принять во внимание такие усложнения как NUMA, см. главу 5). Подход Xen, основанный на использовании отдельного VMM, затрудняет оптимальную (и даже просто хорошую) работу с памятью, так как все сложности управления памятью, включая такие "тривиальные" вещи, как поиск областей памяти, должны дублироваться в VMM. Операционные системы сами имеют зрелую и оптимизированную систему работы с памятью, хотелось бы избежать её дублирования.

Рисунок 4.5: Модель виртуализации KVM
Вот почему доведение модели VMM/Dom0 до её логического завершения представляется привлекательной альтернативой. Рисунок 4.5 показывает, как расширения ядра Linux KVM пытаются решить проблему. Здесь нет отдельного VMM, работающего с аппаратным обеспечением и управляющего всеми гостями. Вместо этого обычное ядро Linux берет на себя эту функциональность. Это означает, что полная и сложная функциональность ядра Linux используется для работы с памятью. Гостевые домены работают вместе с обычными процессами уровня пользователя в режиме, который разработчики называют "режим гостя". Функциональность виртуализации, полной или паравиртуализации, управляется другим процессом уровня пользователя - KVM VMM. Это просто ещё один процесс, который управляет гостевым доменом, с помощью специального устройства KVM, реализованного в ядре.
Преимущество этой модели над отдельным VMM модели Xen в том, что хотя при использовании гостевой ОС все равно работает два обработчика памяти, нужна всего одна реализация, а именно ядро Linux. Нет необходимости дублировать ту же функциональность в другом коде, таком как Xen VMM. Это приводит к меньшему количеству работы, ошибок и, возможно, к меньшим трениям между двумя обработчиками памяти, так как обработчик памяти в гостевой системе Linux делает те же предположения, что и обработчик памяти внешнего ядра Linux, которое работает непосредственно с аппаратным обеспечением.
Итак, программист должен иметь ввиду, что когда используется виртуализация, затраты на операции с памятью выше, чем без виртуализации. Любая оптимизация этой работы дает ещё большую отдачу в виртуализованном окружении. Разработчики процессоров со временем снизят эту разницу с помощью технологий, подобных EPT и NPT, но полностью она не исчезнет.
[1] Ulrich Drepper. Security Enhancements in Red Hat Enterprise Linux, 2004. URL http://people.redhat.com/drepper/nonselsec.pdf
4Поддержка устройств NUMA
Прим.ред.: Напомним, что NUMA (Non-Uniform Memory Access - "неравномерный доступ к памяти" или Non-Uniform Memory Architecture - "Архитектура с неравномерной памятью") - схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется её расположением по отношению к процессору.
В разделе 2 мы видели, что на некоторых машинах, стоимость доступа к конкретным областям физической памяти различается в зависимости от того, откуда происходит доступ. Для этого типа устройств требуется особое внимание со стороны операционной системы и приложений. Мы начнем с некоторых особенностей устройств NUMA, а затем рассмотрим некоторые средства поддержки, предлагаемые в ядре Linux для устройств NUMA.
5.1 Аппаратные устройства NUMA
Использование архитектуры с неравномерным доступом к памяти становятся все более и более распространенным явлением. В простейшем случае архитектуры NUMA процессор может иметь локальную память (смотрите рис.2.3), доступ к которой дешевле, чем доступ к этой локальной памяти из других процессоров. Различие в стоимости для данного типа системы NUMA невысокая, то есть показатель NUMA является низким.
Архитектура NUMA используется также, и в особенности, в больших машинах. Мы описали проблемы получения доступа к одной и той же памяти из различных процессоров. С точки зрения аппаратных средств, все процессоры будут использовать один и тот же северный мост (без учета на данный момент узлов NUMA для машин AMD Opteron, у которых есть свои собственные проблемы). Это делает северный мост одним из самых узких мест, поскольку весь трафик с памятью проходит через него. В больших машинах можно, конечно, вместо северного моста использовать специальные аппаратные средства, но, если используемые чипы памяти не имеют несколько портов, то есть они не могут использоваться из нескольких шин, то узкие места все еще остаются. Многопортовая память является сложной и дорогой для производства и эксплуатации и, поэтому, почти не используется.
Следующим шагом по сложности является использование модели AMD, в которой механизм взаимодействия (Hypertransport, в случае AMD, технология, лицензированная фирмой Digital) предоставляет доступ процессорам, которые не имеют непосредственного доступа к памяти. Для того, чтобы диаметр (т.е., максимальное расстояние между любыми двумя узлами) не увеличивался произвольным образом, размер структур, которые могут формироваться таким образом, должен быть ограничен.

Рис 5.1: Гиперкубы
Наилучшей топологией для узлов является гиперкуб, в котором количество узлов ограничено 2C, где С - количество интерфейсов взаимных соединений, которое есть в каждом узле. Гиперкубы для всех систем с числом процессоров, равным 2n, имеют маленький диаметр. На рис.5.1 показаны первые три гиперкуба. Каждый гиперкуб имеет диаметр С, что является абсолютным минимумом. В первом поколении процессоров Opteron фирмы AMD было по три гипертранспортных соединения на процессор. По крайней мере, к одному из соединений должен быть подключен южный мост, а это означает, что в настоящее время эффективно и без всяких ухищрений можно реализовать гиперкуб с C = 2. Объявлено, что в следующем поколении соединений будет четыре, благодаря чему удастся реализовать гиперкуб с C = 3.
Однако, это не означает, что нельзя поддерживать работу большего количества процессоров. Есть компании, которые разработали сборки, позволяющие использовать наборы с большим количеством процессоров (например, Horus фирмы Newisys). Но эти сборки имеют большой показатель NUMA и при определенном количестве процессоров они становятся неэффективными.
Следующий шаг состоит в подключении групп процессоров и реализация совместно используемой памяти для каждого процессора из группы. Для всех таких систем требуются специализированные аппаратные средства и такие системы не являются изделиями широкого спроса. Такие конструкции имеют несколько уровней сложности. Системой, которая все еще достаточно похожа на машину широкого спроса, является машина IBM X445 и аналогичные машины. Их можно купить как обычные машины, имеющие размер 4U, 8 каналов и процессорами x86 и x86-64. Две такие машины (а с некоторого момента и четыре такие машины) можно объединить для работы в виде одной машины с совместно используемой памятью. Используемые соединения имеют большой показатель NUMA, что должно учитываться как операционной системой, так и приложением.
На другом конце спектра находятся машины, такие как Altix фирмы SGI, которые специально предназначены для подключения друг к другу. Механизм соединения NUMA, реализованный SGI, очень быстрый и имеет более низкую латентность; оба этих свойства очень важны при высокопроизводительных вычислениях (high-performance computing - HPC), особенно в случаях, когда используются интерфейсы Message Passing Interfaces (MPI). Недостатком является, конечно, то, что такая сложность и специализация стоят очень дорого. С их помощью можно получить достаточно низкий коэффициент NUMA, но с тем числом процессоров, которые могут быть в этих машинах (а это - несколько тысяч), а также из-за ограниченных возможностей соединений, показатель NUMA фактически является динамическим и, в зависимости от нагрузки, может достичь неприемлемых уровней.
Наиболее часто используются решения, в которых с помощью высокоскоростных соединений создается кластер из широко распространенных машин. Но они не являются системами NUMA, у них нет общего адресного пространства и, следовательно, они не попадают в какую-нибудь из категорий, которые здесь обсуждаются.
5.2 Поддержка NUMA в операционной системе
Чтобы операционная система могла поддерживать машины NUMA, она должна принимать во внимание различную природу памяти. Например, если процесс запускается на данном процессоре, то физическая память, назначаемая адресному пространству процесса, должна выбираться из локальной памяти. В противном случае каждая команда должна иметь доступ к удаленной памяти как для кода, так и для данных. Есть особые случаи, присутствующие только в машинах NUMA, которые следует принять во внимание. Текстовый сегмент DSO, как правило, представлен в виде одной копии в физической памяти машины. Но если DSO используется процессами и потоками на всех процессорах (например, базовые библиотеки времени выполнения, такие как libc), то это означает, что у всех, кроме нескольких процессоров, должна быть возможность удаленного доступа. Операционная система в идеале должна "зеркалировать" такие разделяемые DSO в физическую память каждого процессора и использовать локальные копии. Это оптимизация, а не требование, и, в общем случае, трудно реализуемая. Ее либо вообще невозможно реализовать, либо ее можно поддерживать только в ограниченных ситуациях.
Чтобы не ухудшать общую ситуацию, операционная система не должна переносить процесс или поток с одного узла на другой. Операционная система должна пытаться избегать миграции процессов уже даже на обычных многопроцессорных машинах, поскольку переход с одного процессора на другой означает, что будет потеряно содержимое кэш-памяти. Если при перераспределении нагрузки требуется переместить процесс или поток из процессора, то операционная система, как правило, будет выбирать новый процессор произвольным образом, причем такой процессор, у которого достаточно оставшейся мощности. В среде NUMA при выборе нового процессора возникает немного больше ограничений. Затраты на доступ к памяти во вновь выбираемом процессоре не должны превышать аналогичных затрат на старом ранее использовавшемся процессоре, из-за чего происходит ограничение выбора. Если нет свободного процессора, соответствующего указанному критерию, то у операционной системы не остается другого выбора, кроме перехода на процессор, где доступ к памяти стоит дороже.
В такой ситуации есть два возможных выхода. Во-первых, можно надеяться, что ситуация носит временный характер и процесс можно будет перенести обратно на более подходящий процессор. Либо операционная система может перенести память, используемую процессом, на те физические страницы, которые находятся ближе к вновь используемому процессору. Это сравнительно дорогая операция. Возможно, потребуется скопировать огромный объем памяти, хотя и не обязательно за один шаг. Когда это будет происходить, то для того, чтобы старые страницы были перенесены правильно, процесс должен быть остановлен хотя бы и на короткий промежуток времени. Когда происходит перенос страниц памяти, то возникает ряд ограничений, необходимых для того, чтобы обеспечить эффективность и быстрое выполнение операции. В общем, операционная система должна этого избегать в случае, если это действительно не является необходимым.
Обычно нельзя предполагать, что все процессы на машинах NUMA используют один и тот же объем памяти, как также и то, что распределение процессов по процессорам и используемой памяти будет равномерным. На самом деле, если приложения, работающие на машинах, не является очень специализированными (что обычно в мире высокопроизводительных вычислений, но не за его пределами), использование памяти будет весьма неравномерным. Некоторые приложения будут пользоваться большими объемами памяти, другие - вряд ли. Если, в случае, когда возникает запрос, память для процессора выделается локально, то это, рано или поздно приведет к проблемам. В конечном итоге такая система исчерпает память на тех локальных узлах, где процессов работает больше.
Чтобы не возникало таких серьезных проблем, выделение памяти, по умолчанию, не происходит исключительно на локальном узле. Чтобы использовать всю память системы, стратегией, используемой по умолчанию, выбирается разбиение памяти на полосы. Это гарантирует равномерное использование всей памяти, имеющейся в системе. В качестве побочного эффекта, становится возможным свободно перемещать процессы между процессорами, поскольку, в среднем, стоимость доступа ко всей используемой памяти не меняется. Для небольших показателей NUMA, такое выделение полос памяти приемлемо, но оно, все же, не является оптимальным (смотрите данные в разделе 5.4).
Такое решение является пессимистичным; оно поможет системе избежать серьезных проблем и при нормальных условиях эксплуатации сделает ситуацию более предсказуемой. Но такой подход снизит общую производительность системы, причем в некоторых случаях - значительно. Вот почему в системе Linux есть правила распределения памяти, которые можно отдельно выбирать для каждого процесса. Процесс может для себя и порождаемых им процессов выбирать другую стратегию. В разделе 6 мы приведем интерфейсы, которые можно для этого использовать.
5.3 Предоставляемая информация
Ядро предоставляет в виртуальной файловой системе sys (Sysfs) информацию о кэш-памяти процессора
/sys/devices/system/cpu/cpu*/cache
В разделе 6.2.1 мы рассмотрим интерфейс, которым можно будет пользоваться при запросе о размерах различной кэш-памяти. Самое важное здесь - это топология кэш-памяти. В директории, указанном выше, находятся поддиректории (с названиями index*), в которых приводится информация о том, какая кэш-память есть в каждом процессоре. В этих директориях важны файлы type, level и shared_cpu_map, поскольку в них описывается топология. В таблице 5.1. приведена информация для процессора Intel Core 2 QX6700.
Таблица 5.1: Информация sysfs о кэш-памяти поцессора Core 2
| Файл type | Файл level | Файл shared_cpu_map | ||
|---|---|---|---|---|
cpu0 |
index0 | Data (Данные) | 1 | 00000001 |
| index1 | Instruction (Инструкции) | 1 | 00000001 | |
| index2 | Unified (Универсальная) | 2 | 00000003 | |
cpu1 |
index0 | Data (Данные) | 1 | 00000002 |
| index1 | Instruction (Инструкции) | 1 | 00000002 | |
| index2 | Unified (Универсальная) | 2 | 00000003 | |
cpu2 |
index0 | Data (Данные) | 1 | 00000004 |
| index1 | Instruction (Инструкции) | 1 | 00000004 | |
| index2 | Unified (Универсальная) | 2 | 0000000c | |
cpu3 |
index0 | Data (Данные) | 1 | 00000008 |
| index1 | Instruction (Инструкции) | 1 | 00000008 | |
| index2 | Unified (Универсальная) | 2 | 0000000c | |
Эти данные означают следующее:
- В каждом ядре {Из других источников известно, что cpu0 и cpu3 являются ядрами, о чем мы расскажем немного позже} есть три вида кэш-памяти: L1i, L1D, L2.
- Кэш-память L1d and L1i ни с кем не разделяется, в каждом ядре есть свой собственный набор кэш-памяти. Об этом свидетельствует битовая карта
shared_cpu_map, в которой установлен только один бит. - Кэш-память L2 совместно используется в
cpu0и вcpu1точно также, как и L2 --- вcpu2и вcpu3.
Если в процессоре больше уровней кэш-памяти, то директориев index* также будет больше.
В таблице 5.2 приведена информация о кэш-памяти двухядерной машины Opteron с четырьмя соединениями:
Таблица 5.2: Информация sysfs о кэш-памяти поцессора Opteron
| Файл type | Файл level | Файл shared_cpu_map | ||
|---|---|---|---|---|
cpu0 |
index0 | Data (Данные) | 1 | 00000001 |
| index1 | Instruction (Инструкции) | 1 | 00000001 | |
| index2 | Unified (Универсальная) | 2 | 00000001 | |
cpu1 |
index0 | Data (Данные) | 1 | 00000002 |
| index1 | Instruction (Инструкции | 1 | 00000002 | |
| index2 | Unified (Универсальная) | 2 | 00000002 | |
cpu2 |
index0 | Data (Данные) | 1 | 00000004 |
| index1 | Instruction (Инструкции) | 1 | 00000004 | |
| index2 | Unified (Универсальная) | 2 | 00000004 | |
cpu3 |
index0 | Data (Данные) | 1 | 00000008 |
| index1 | Instruction (Инструкции | 1 | 00000008 | |
| index2 | Unified (Универсальная) | 2 | 00000008 | |
cpu4 |
index0 | Data (Данные) | 1 | 00000010 |
| index1 | Instruction (Инструкции) | 1 | 00000010 | |
| index2 | Unified (Универсальная) | 2 | 00000010 | |
cpu5 |
index0 | Data (Данные) | 1 | 00000020 |
| index1 | Instruction (Инструкции) | 1 | 00000020 | |
| index2 | Unified (Универсальная) | 2 | 00000020 | |
cpu6 |
index0 | Data (Данные) | 1 | 00000040 |
| index1 | Instruction (Инструкции) | 1 | 00000040 | |
| index2 | Unified (Универсальная) | 2 | 00000040 | |
cpu7 |
index0 | Data (Данные) | 1 | 00000080 |
| index1 | Instruction (Инструкции) | 1 | 00000080 | |
| index2 | Unified (Универсальная) | 2 | 00000080 | |
Видно, что у этих процессоров также есть три вида кэш-памяти: L1i, L1D, L2. Ни одно из ядер не разделяет какую-либо кэш-память. Самым интересным в этой системе является топология процессоров. Без этой дополнительной информации невозможно разобраться в данных, связанных кэш-памятью. Эта информация представлена в файловой системе sys в следующем директории
/sys/devices/system/cpu/cpu*/topology
В таблице 5.3 приведены интересные файлы из этого директория, описывающие машину SMP Opteron.
Таблица 5.3: Информация sysfs, описывающая топологию процессора Opteron
| Файл physical_>package_id | Файл core_id | Файл core_siblings | Файл thread_siblings | |
|---|---|---|---|---|
cpu0 | 0 | 0 | 00000003 | 00000001 |
cpu1 | 1 | 00000003 | 00000002 | |
cpu2 | 1 | 0 | 0000000c | 00000004 |
cpu3 | 1 | 0000000c | 00000008 | |
cpu4 | 2 | 0 | 00000030 | 00000010 |
cpu5 | 1 | 00000030 | 00000020 | |
cpu6 | 3 | 0 | 000000c0 | 00000040 |
cpu7 | 1 | 000000c0 | 00000080 |
Если воспользоваться одновременно таблицей 5.2 и таблицей 5.3, то видно, что нет процессоров, имеющих гиперпотоки (в битовой карте thread_siblings установлен один бит), что система фактически имеет четыре процессора (physical_package_id от 0 и до 3), что в каждом процессоре есть два ядра и что ни одно из ядер не разделяет какую-либо кэш-память. Эти данные соответствуют ранним версиям процессора Opteron.
То, что до сих пор полностью отсутствовало в представленных данных, это информация об архитектуре NUMA для данной машины. Любая машина SMP Opteron является машиной NUMA. Данные об этом, которое есть в машинах NUMA, нам следует искать в другом месте файловой системы sys, а именно - в следующей иерархии
/sys/devices/system/node
В этом директории имеется поддиректорий для каждого узла NUMA, присутствующего в системе. В директориях конкретных узлов есть ряд файлов. В предыдущих двух таблицах и в таблице 5.4 описаны важные файлы и их содержимое для машины Opteron.
Таблица 5.4: Информация sysfs, касающаяся узлов Opteron
| Файл cpumap | Файл distance | |
|---|---|---|
node0 | 00000003 | 10 20 20 20 |
node1 | 0000000c | 20 10 20 20 |
node2 | 00000030 | 20 20 10 20 |
node3 | 000000c0 | 20 20 20 10 |
Эта информация связывает все остальные данные вместе и теперь у нас есть полное представление об архитектуре машины. Мы уже знаем, что машина состоит из четырех процессоров. Каждый процессор представляет собой узел --- это можно увидеть по установленным битам в файле cpumap директориев node*. В файлах distance в этих директориях содержится набор значений по одному для каждого узла, которые указывают стоимость доступа к памяти на соответствующих узлах. В этом примере стоимость доступа к любой локальной памяти равна 10, стоимость доступа ко всем удаленным узлам равна 20. {Это, кстати, неправильно. Информация ACPI, по-видимому, неверная, т.к., несмотря то, что у каждого процессора есть по три одинаковых соединения HyperTransport, по крайней мере, одно из них должно использоваться для подключения южного моста. Поэтому, по крайней мере, для одной пары узлов дистанция должна быть большей.} Это означает, что, несмотря на то, что процессоры организованы в виде двумерного гиперкуба (смотрите рис. 5.1), взаимодействие между процессорами, которые не связаны непосредственно, дороже не будет. Относительные значения расходов должны использоваться для оценки действительного различия времени доступа. Точность всей этой информации - это другой вопрос.
5.4 Стоимость удаленного доступа
Дистанция является релеватным значением. В работе [amdccnuma] фирма AMD приводит документацию по затратам NUMA для машин с четырьмя соединениями. На рис.5.3 приведены значения для операций записи.
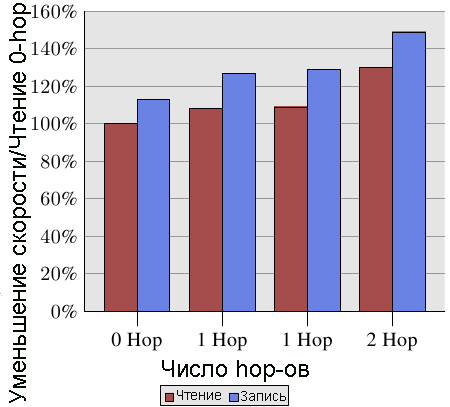
Рис.5.3: Приоизводительность записи / чтения для нескольких узлов
Запись, что не удивительно, осуществляется медленнее, чем чтение. Интересны значения затрат для случаев 1- hop и 2-hop. Случай с двумя значениями 1-hop немножко отличается. Подробности смотрите в [amdccnuma]. Мы из этого графика должны запомнить, что чтение и запись для 2-hop на 30% и 49% (соответственно) выполняется медленнее, чем чтение 0-hop. Запись для 2-hop на 32% медленнее, чем запись для 0-hop, и на 17% медленнее, чем запись для 0-hop. Большая разница может быть обусловлена взаимным расположением узлов процессора и памяти. В следующих поколениях процессоров фирмы AMD в каждом процессоре будет по четыре одинаковых соединения HyperTransport. В этом случае для машины с четырьмя соединениями значение диаметра будет одно и то же. При использовании восьми соединений проблема возникает снова с удвоенным эффектом, т.к. диаметр гиперкуба для восьми узлов равен трем.
Вся эта информация доступна, но она громоздка. В разделе 6.5 мы рассмотрим интерфейс, с помощью которого станет проще пользоваться этой информацией.
Последнюю часть информации система предоставляет в описании состояния самого процесса. Состояние процесса позволяет опререлить как в системе распределены по узлам файлы отображения памяти, страницы Copy-On-Write (COW) и анонимная память. { Copy-On-Write является способом, который часто используется в реализациях операционной в случаях, когда станица памяти принадлежит сначала одному владельцу, а затем эта страница должна копироваться другому пользователю. Во многих ситуациях копирование либо вообще не нужно, либо не нужно на начальном этапе. Оно имеет смысл в случае, когда кто-нибудь из пользователей изменяет содержимое памяти. Операционная система перехватывает операцию записи, делает копию страницы памяти, а затем позволяет продолжить операцию записи.} Для каждого процесса есть файл /proc/**PID**/numa_maps, где PID является идентификатором процесса, такой как показан на рисунке 5.2.
00400000 default file=/bin/cat mapped=3 N3=3
00504000 default file=/bin/cat anon=1 dirty=1 mapped=2 N3=2
00506000 default heap anon=3 dirty=3 active=0 N3=3
38a9000000 default file=/lib64/ld-2.4.so mapped=22 mapmax=47 N1=22
38a9119000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1
38a911a000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1
38a9200000 default file=/lib64/libc-2.4.so mapped=53 mapmax=52 N1=51 N2=2
38a933f000 default file=/lib64/libc-2.4.so
38a943f000 default file=/lib64/libc-2.4.so anon=1 dirty=1 mapped=3 mapmax=32 N1=2 N3=1
38a9443000 default file=/lib64/libc-2.4.so anon=1 dirty=1 N3=1
38a9444000 default anon=4 dirty=4 active=0 N3=4
2b2bbcdce000 default anon=1 dirty=1 N3=1
2b2bbcde4000 default anon=2 dirty=2 N3=2
2b2bbcde6000 default file=/usr/lib/locale/locale-archive mapped=11 mapmax=8 N0=11
7fffedcc7000 default stack anon=2 dirty=2 N3=2
Рис. 5.2: Содержимое файла /proc/PID/numa_maps
В файле важной информацией являются значения с N0 по N3, которые указывают на количество страниц, выделенных в качестве области памяти на узлах с 0 по 3. Ясно видно, что программа выполнялась в ядре на узле 3. Сама программа и измененные ею страницы располагаются на том же самом узле. Отображение, используемое только для чтения, такое, как первое отображение для ld-2.4.so и libc-2.4.so, а также общедоступный файл locale-archive, располагаются на других узлах.
Как мы видели на рисунке 5.3, скорость чтения между узлами падает на 9% и 30% соответственно для чтения в случаях 1-hop и 2-hop. Если при выполнении программы потребуется такое чтение, а в кэш-памяти L2 возникают промахи, то эти дополнительные затраты делят между собой кэш-строки. В случае, если память не является локальной памятью процессора, все затраты, измеренные для больших рабочих нагрузок, которые превышаю размер кэш-памяти, должны увеличиваться на 9% / 30%.

Рис.5.4: Использование удаленной памяти
Чтобы увидеть реально существующий эффект, мы точно также, как мы делали в разделе 3.5.1, можем измерить пропускную способность, но на этот раз с памятью, которая находится на удаленном узле на расстоянии в 1 hop. На рис.5.4 приведен результат этого теста в сравнении с данными, полученными при использовании локальной памяти. На графике есть несколько больших пиков в обоих направлениях, которые связаны с проблемой измерения многопоточного кода и которые можно проигнорировать. На этом графике важно то, что операции чтения всегда выполняются на 20% медленнее. Это значительно медленнее, чем 9% на рисунке 5.3, где, скорее всего, нет прерываний чтения и записи, что может особенностью старых версий процессоров. Об этом знает только фирма AMD.
Для рабочих наборов, которые по размерам вписываются в кэш-память, производительность записи и копирования также на 20% медленнее. Для рабочих наборов, размер которых превышает размер кэш-памяти, скорость записи по измерениям не сильно медленнее, чем операции на локальном узле. Скорость соединения достаточно быстрая для того, чтобы можно было работать с памятью. Доминирующим фактором является время ожидания в основной памяти.
5 Что могут делать программисты - оптимизация кэша
Исходя из изложенного в предыдущих главах ясно, что существует много, очень много возможностей для программиста влиять на производительность программы, позитивно или негативно. И это только для операций, связанных с использованием памяти. Мы будем описывать эти возможности снизу вверх - начнем с нижних уровней физического доступа к памяти и кэшу L1 и закончим функциональностью операционной системы, которая влияет на работу с памятью.
6.1 Обход кэша
Когда данные произведены и не (сразу) используются снова, тот факт, что операции сохранения в памяти требуют сначала чтения полной строки кэша, затем модификации кэшированных данных, отрицательно сказывается на производительности. Эта операция выталкивает из кэшей данные, которые могут понадобится снова, заменяя их на данные, которые не скоро понадобятся. Это особенно верно для больших структур данных, таких как матрицы, которые заполняются и затем используются позднее. Прежде чем заполнен последний элемент матрицы, из-за большого размера первые элементы выталкиваются, делая кэширование записи неэффективным.
Для этой и подобных ситуаций процессоры поддерживают запись данных методом "не промежуточного" (non-temporal) сохранения. "Не промежуточное" в этом контексте означает, что данные будут использоваться не скоро, поэтому нет смысла их кэшировать. Это "не промежуточное" сохранение не читает строку из кэша и не меняет её, вместо этого новые данные сохраняются непосредственно в память.
Это может показаться весьма затратным процессом, но это не обязательно так. Процессор попытается использовать политику записи write-combining (см. 3.3.3), чтобы заполнить целую строку кэша. Если это удастся, не нужно будет никаких операций чтения. Для архитектур x86 и x86-64 gcc предоставляет несколько встроенных функций компилятора:
#include <emmintrin.h>
void _mm_stream_si32(int *p, int a);
void _mm_stream_si128(int *p, __m128i a);
void _mm_stream_pd(double *p, __m128d a);
#include <xmmintrin.h>
void _mm_stream_pi(__m64 *p, __m64 a);
void _mm_stream_ps(float *p, __m128 a);
#include <ammintrin.h>
void _mm_stream_sd(double *p, __m128d a);
void _mm_stream_ss(float *p, __m128 a);
Эти инструкции работают наиболее эффективно, если они обрабатывают большие объемы данных за один раз. Данные загружаются из памяти, обрабатываются за один или более шагов, и затем записываются обратно в память. Данные идут "потоком" через процессор, отсюда и название функций.
Адреса памяти должны быть выравнены по 8 или 16 бит соответственно. В коде, использующем мультимедийные расширения, можно заменять обычные встроенные функции _mm_store_* этими "не промежуточными" версиями. В программе перемножения матриц в разделе 9.1 мы не делаем этого, так как записанные значения вскоре снова будут использованы. Это пример, когда потоковые инструкции не подходят. Подробнее об этой программе в разделе 6.2.1.
Буфер процессора, используемый для write-combining, может хранить запросы на частичную запись в строку кэша только небольшое время. В общем необходимо использовать инструкции, модифицирующие одну строку кэша, одну следом за другой, чтобы метод write-combining мог действительно работать. Вот пример того, как это делать:
#include <emmintrin.h>
void setbytes(char *p, int c)
{
__m128i i = _mm_set_epi8(c, c, c, c,
c, c, c, c,
c, c, c, c,
c, c, c, c);
_mm_stream_si128((__m128i *)&p[0], i);
_mm_stream_si128((__m128i *)&p[16], i);
_mm_stream_si128((__m128i *)&p[32], i);
_mm_stream_si128((__m128i *)&p[48], i);
}
Предполагая, что указатель p подходящим образом выравнен, вызов этой функции устанавит все байты адресуемой строки кэша равными c. Логика, управляющая write-combining, увидит четыре сгенерированные инструкции movntdq и выполнит команду на запись в память только когда последняя инструкция будет выполнена. Суммируя: эта последовательность кода позволит избежать не только чтения строки кэша перед записью, но и засорения кэша данными, которые могут не скоро понадобиться. Это может принести огромную пользу в определенных ситуациях. Примером обычного кода, использующего эту технику может служить функция memset из библиотеки C, которая должна использовать такую же последовательность кода для больших блоков.
Некоторые архитектуры предлагают специализированные решения. Архитектура PowerPC определяет инструкцию dcbz, которая может быть использована, чтобы очистить целую строку кэша. Эта инструкция не обходит кэш, так как для результата выделяется строка кэша, но данные из памяти не читаются. Она более ограничена, чем инструкции "не промежуточного" сохранения, так как строка кэша может быть заполнена только нулями и это загрязняет кэш (если данные не должны вскоре использоваться), но для неё не требуется логики write-combining.
Чтобы увидеть эти "не промежуточные" инструкции в действии, мы рассмотрим новый тест, измеряющий запись в матрицу, организаванную как двумерный массив. Компилятор располагает матрицу в памяти так, что левый (первый) индекс адресует строку, элементы которой располагаются в памяти последовательно. Правый (второй) индекс адресует элементы строки. Тестовая программа проходит матрицу двумя путями: сначала во внутреннем цикле увеличивается номер колонки, потом во внутреннем цикле увеличивается номер строки. Это означает, что мы имеем процесс как на рисунке 6.1.
Рисунок 6.1: Образцы доступа к матрице
Мы измеряем сколько потребуется времени для того чтобы инициализировать матрицу размером 3000×3000. Чтобы увидеть как ведет себя память, мы используем инструкции сохранения, которые не используют кэш. На процессорах архитектуры IA-32 для этого используется индикатор ⌠non-temporal hint■. Для сравнения мы измеряем также обычные операции сохранения. Результаты приведены в таблице 6.1.
| Приращение внутреннего цикла | ||
|---|---|---|
| Строка | Колонка | |
| Обычная | 0.048с | 0.127с |
| Не промежуточная | 0.048с | 0.160с |
Таблица 6.1: Инициализация матрицы
Для обычной записи, которая использует кэш, мы видим ожидаемый результат: если память используется последовательно, мы имеем гораздо лучший результат, 0.048с на всю операцию, что составляет примерно 750Мб/с, в сравнении с более или менее случайным доступом который занимает 0.127с (около 280Мб/с). Матрица достаточно велика, чтобы сделать кэш неэффективным.
Нас здесь больше интересует запись, делаемая в обход кэша. Может показаться удивительным, что последовательный доступ здесь такой же быстрый как в случае использования кэша. Причина этого в том, что процессор использует политику записи write-combining как объяснялось выше. К тому же правила упорядочивания памяти для "не промежуточной" записи ослаблены: программа должна явным образом указывать барьеры памяти (инструкция sfence для процессоров x86 и x86-64). Это означает, что процессор имеет больше свободы при записи данных и использует доступную пропускную способность наиболее эффективно.
В случае доступа по колонкам во внутреннем цикле ситуация другая. Результат значительно медленнее, чем при использовании кэша (0.16с, около 225Мб/с). Здесь мы видим, что write combining невозможно и каждая ячейка памяти адресуется индивидуально. Это требует постоянного выбора новых строк в чипе RAM с сопутствующими этому задержками. Результат на 25% хуже, чем при использовании кэша.
В отношении чтения, процессорам до недавних пор недоставало поддержки, если не считать слабых индикаторов, использующих инструкции предварительной выборки "не промежуточного" доступа (NTA, non-temporal access). Для чтения нет эквивалента политике write-combining, что особенно плохо для некэшируемой памяти, такой как отображаемый в память ввод/вывод. Intel в расширениях SSE4.1 вводит загрузки NTA. Они реализованы с использованием небольшого количества потоковых буферов загрузки, каждый буфер содержит строку кэша. Первая инструкция movntdqa для заданной строки кэша загружает строку кэша (т.е. строку, которая могла бы быть загружена в кэш) в буфер, возможно замещая там другую строку. Последующие обращения, выравненные по 16 байт, к этой строке будут обслуживаться буфером с небольшими затратами. Если для этого не будет других причин, то строка кэша не будет загружена в кэш, что позволит загружать большие объемы памяти, не загрязняя кэш. Компилятор предоставляет встроенную функцию для этой инструкции
#include <smmintrin.h>
__m128i _mm_stream_load_si128 (__m128i *p);
Эта встроенная функция должна быть использована много раз с адресами 16-байтовых блоков, передаваемых в качестве параметра, пока не прочитаны все строки кэша. Только тогда можно начинать следующую строку кэша. Так как буферов чтения несколько, возможно чтение из двух мест в памяти одновременно.
Из этого эксперимента мы должны вынести то, что современные процессоры очень хорошо оптимизируют некэшированный доступ на запись и (с недавних пор) на чтение, при условии что этот доступ последовательный. Это знание может быть очень полезно при работе с большими структурами данных, которые используются только один раз. Второе - кэши могут помочь покрыть некоторые, хотя и не все, затраты на произвольный доступ к памяти. Произвольный доступ в этом примере на 70% медленнее из-за особенностей устройства доступа к RAM. Пока эти устройства не поменяются, произвольного доступа следует по возможности избегать.
В разделе, посвященном предварительной выборке мы еще рассмотрим "не промежуточный" флаг.
6.2 Доступ к кэшу
Наиболее важные улучшения, которые программист может внести в работу с кэшами, относятся к кэшу уровня 1. Мы обсудим их первыми, до работы с другими уровнями. Очевидно, что оптимизация кэша уровня 1 повлияет и на другие кэши. Тема для любого доступа к памяти одна - улучшайте локальность (пространственную и временную) и выравнивайте код и данные.
6.2.1 Оптимизация доступа к кэшу данных 1 уровня
В разделе 3.3 мы уже видели насколько эффективное использование кэша L1d может повысить производительность. В этом разделе мы покажем, какие изменения в коде могут помочь её улучшить. В продолжение предыдушего раздела, мы сначала сконцентрируемся на оптимизации, которая позволит сделать доступ к памяти последовательным. Числа в разделе 3.3 показывают, что процессор автоматически делает предварительную выборку данных при последовательном доступе к памяти.
Для примера используется код перемножения матриц. Мы используем две квадратные матрицы размера 1000×1000. Для тех, кто забыл математику, произведение двух матриц A и B с элементами aij и bij, где 0 ≤ i,j < N, это матрица с элементами

Прямое использование этой формулы в программе на C может выглядеть так:
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
res[i][j] += mul1[i][k] * mul2[k][j];
Две исходные матрицы это mul1 и mul2. Матрица результата res изначально инициализирована нулями. Милая и простая реализация. Но должно быть очевидным, что мы имеем в точности ту же проблему, как на рисунке 6.1. Доступ к mul1 последовательный, а для mul2 внутренний цикл увеличивает номер строки. Это означает, что работа с mul1 идет как с левой матрицей на рисунке 6.1, а работа с mul2 идет как с правой матрицей. Это нехорошо.
Есть возможное решение, которое легко попробовать. Так как каждый элемент матрицы используется много раз, может стоит преобразовать ("транспонировать", говоря математическим языком) вторую матрицу mul2, перед тем как использовать её.

После транспозиции (традиционно обозначаемой верхним индексом 'T') мы обходим обе матрицы последовательно. В коде C это будет выглядеть так:
double tmp[N][N]; for (i = 0; i < N; ++i) for (j = 0; j < N; ++j) tmp[i][j] = mul2[j][i]; for (i = 0; i < N; ++i) for (j = 0; j < N; ++j) for (k = 0; k < N; ++k) res[i][j] += mul1[i][k] * tmp[j][k];
Мы создаем временную переменную, которая будет содержать транспонированную матрицу. Это потребует выделения большего количества памяти, но затраты, можно надеяться, окупятся, так как 1000 не последовательных обращений на колонку обойдутся дороже (по крайней мере на современном оборудовании). Пора сделать какой-нибудь тест производительности. Результат на Intel Core 2 с тактовой частотой 2666МГц (в циклах процессора):
| Исходная | Транспонированная | |
|---|---|---|
| Циклы | 16,765,297,870 | 3,922,373,010 |
| Относительно | 100% | 23.4% |
Простая трансформация матрицы дает выигрыш в 76.7%! Операция копирования более чем окупилась. 1000 не последовательных обращений к памяти - действительно проблема.
Следующий вопрос - наилучшее ли это решение? Мы определенно нуждаемся в альтернативном методе, который не требует дополнительного копирования. Не всегда можно позволить себе такую роскошь как копирование - матрица может быть слишком большой или доступная память слишком маленькой.
Поиск альтернативного метода нужно начать с пристального изучения используемой математики и операций, выполняемых в исходном решении. Тривиальные математические правила говорят, что порядок, в котором происходит суммирование для каждого элемента матрицы результата, не имеет значения, каждое слагаемое появляется только раз (мы игнорируем здесь арифметические эффекты, которые могут вызвать появление переполнения, потери значимости, округления). Это понимание позволяет нам искать решения, связанные с переупорядочиванием сложения, выполняемого во внутреннем цикле исходного кода.
Давайте посмотрим, в чем состоит проблема при исполнении исходного кода. Порядок, с которым происходит обращение к элементам mul2 такой: (0,0), (1,0), ..., (N-1,0), (0,1), (1,1), .... Элементы (0,0) и (1,0) находятся в одной строке кэша, но пока внутренний цикл будет пройден один раз, эта строка давно уже будет исключена из кэша. Для этого примера каждый проход внутреннего цикла требует для каждой из трех матриц 1000 строк кэша (размером 64 байта для процессора Core 2). Это гораздо больше, чем 32Кб кэша L1d.
Но что, если мы будем обрабатывать две итерации среднего цикла вместе при прохождении внутреннего цикла? В этом случае мы используем два значения double из строки кэша, которые гарантированно будут в L1d. Мы сократим показатель промахов в L1d наполовину. Это определенно улучшение, но, в зависимости от размера строки кэша, это все еще может быть не наилучшим решением. Процессор Core 2 имеер размер строки кэша L1d 64 байта. Это значение можно выяснить используя
sysconf (_SC_LEVEL1_DCACHE_LINESIZE)
во время выполнения, или используя getconf в командной строке, так что программу можно скомпилировать для специфического размера строки кэша. При sizeof(double) равном 8 это означает, что для того, чтобы полностью использовать строку кэша, мы должны делать 8 итераций среднего цикла за один раз. Продолжая эту мысль, чтобы эффективно использовать также и матрицу res, т.е. чтобы записывать 8 результатов одновременно, мы должны делать также и 8 итераций внешнего цикла за один раз. Мы предполагаем здесь размер строки кэша 64, но код будет работать так же хорошо на системах с 32-байтными строками кэша, так как обе строки кэша будут использованы на 100%. В общем случае лучше всего зафиксировать размер строки кэша во время компиляции, используя утилиту getconf:
gcc -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ...
Если бинарник предполагается к распространению, то нужно использовать наибольший размер строки кэша. Для очень маленького L1d это может означать, что не все данные попадут в кэш, но такие процессоры все равно не подходят для высокопроизводительных программ. Код, к которому мы приходим, должен выглядеть примерно так:
#define SM (CLS / sizeof (double))
for (i = 0; i < N; i += SM)
for (j = 0; j < N; j += SM)
for (k = 0; k < N; k += SM)
for (i2 = 0, rres = &res[i][j],
rmul1 = &mul1[i][k]; i2 < SM;
++i2, rres += N, rmul1 += N)
for (k2 = 0, rmul2 = &mul2[k][j];
k2 < SM; ++k2, rmul2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rmul1[k2] * rmul2[j2];
Выглядит устрашающе. Это потому, что код содержит некоторые трюки. Самое заметное изменение состоит в том, что мы имеем 6 вложенных циклов. Внешние циклы имеют приращение SM (размер строки кэша, деленный на sizeof(double)). Это разделяет умножение на несколько более мелких задач, которые могут быть решены с большей локальностью кэша. Внутренние циклы выполняют итерации для индексов, пропущенных во внешних циклах. Получается снова три цикла. Единственный трюк здесь в том, что циклы для k2 и j2 идут в другом порядке. Это сделано потому, что при вычислении только одно выражение зависит от k2, а от j2 зависят два.
Остальные сложности являются результатом того, что компилятор gcc недостаточно умен, когда речь идет об оптимизации индексов массива. Введение дополнительных переменных rres, rmul1 и rmul2 оптимизирует код, вытягивая обычные выражения из внутренних циклов настолько далеко, насколько это возможно. Правила по умолчанию для псевдонимов в языках C и C++ не могут помочь компилятору сделать эти решения (если не используется ключевое слово restrict, то любой доступ через указатели является потенциальным источником появления псевдонимов). Вот почему Fortran все еще является предпочтительным языком для численного программирования - он позволяет легче писать быстрый код. {В теории, ключевое слово restrict, введенное в язык С в ревизии 1999 года, должно решить эту проблему. Компиляторы, однако, пока этого не поддерживают. Причина, в основном, в том, что существует очень много некорректного кода, который бы ввел компилятор в заблуждение и заставил его генерировать некорректный объектный код.}
В таблице 6.2 мы видим как вся эта работа окупается.
| Исходная | Транспонированная | Подматрицы | Векторизированно | |
|---|---|---|---|---|
| Циклы | 16,765,297,870 | 3,922,373,010 | 2,895,041,480 | 1,588,711,750 |
| Относительно | 100% | 23.4% | 17.3% | 9.47% |
Таблица 6.2: Замеры времени умножения матриц
Исключая копирование, мы получаем еще 6.1% производительности. Плюс нам не нужна дополнительная память. Входящие матрицы могут быть сколько угодно большими, пока матрица результата помещается в памяти. Это требование общего решения, которого мы теперь достигли.
В таблице 6.2 есть одна колонка, которую мы еще не объяснили. Большинство современных процессоров имеют сегодня поддержку векторизации. Часто подаваемые как мультимедийные расширения, эти специальные инструкции позволяют обрабатывать 2,4,8 или более значений одновременно. Часто это операции SIMD (Single Instruction, Multiple Data - одна инструкция много данных), дополненные другими, для приведения данных в нужную форму. Инструкции SSE2, которые поддерживают процессоры Intel, могут обрабатывать два двойных слова за одну операцию. Справочное руководство содержит список встроенных функций компилятора, которые предоставляют доступ к этим инструкциям SSE2. Если используются эти функции, программа работает еще на 7.3% быстрее, по сравнению с оригиналом. В результате мы получаем программу, которая делает работу за 10% времени работы исходного кода. Переведя в цифры, понятные для людей мы перешли от 318 мегафлоп к 3.35 гигафлоп. Так как мы интересуемся здесь только эффектами в памяти, код программы помещен в раздел 9.1.
Следует отметить, что в последней версии кода мы все еще имеем проблемы кэширования mul2 - предварительная загрузка так и не работает. Это нельзя решить без транспонирования матрицы. Может быть модули предварительной загрузки кэша станут умнее и смогут узнавать такую ситуацию, тогда дополнительных изменений не потребуется. 3.19 гигафлоп на процессоре 2.66ГГц с одноядерным кодом все равно неплохо.
В этом примере с произведением матриц мы оптимизировали использование загруженных строк кэша. Все байты строки кэша всегда используются. Мы просто делаем так, что они используются до того, как строка кэша исключена. Это определенно частный случай.
Более распространена ситуация, когда мы имеем структуры данных, которые заполняют одну или более строк кэша, хотя программа испольует всего несколько членов такой структуры данных за раз. На рисунке 3.11 мы уже видели эффекты большого размера структуры, у которой используется только несколько членов.

Рисунок 6.2: Распостранение на несколько строк кэша
Рисунок 6.2 показывает результаты еще одного набора тестов, использующих хорошо теперь известную программу. На этот раз складываются два значения из одного элемента списка. В одном случае оба элемента находятся в одной строке кэша, в другом случае один элемент в первой строке кэша элемента списка, а второй элемент - в последней строке кэша. График показывает замедление, которое мы имеем.
Неудивительно, что во всех случаях нет отрицательных эффектов, если рабочее пространство помещается в L1d. Когда L1d больше не хватает, приходится платить использованием двух строк кэша вместо одной. Красная линия показывает данные, когда список лежит последовательно в памяти. Мы видим две обычные ступени: около 17% ухудшения, пока достаточно кэша L2, и 27% - когда нужно использовать основную память.
В случае произвольного доступа данные выглядят немного по-другому. Ухудшение при рабочем пространстве, которое помещается в L2, находится между 25% и 35%. Потом оно уменьшается до примерно 10%. Это не из-за того, что издержки уменьшаются, наоборот, реальный доступ к памяти становится непропорционально более дорогим. Данные также показывают, что в некоторых случаях расстояние между элементами имеет значение. Кривая "случайные 4 строки кэша" показывает большие издержки, так как используются первая и четвертая строки кэша.
Легкий способ увидеть расположение структуры данных в строках кэша - это использовать программу pahole (см. [1]). Эта программа исследует структуры данных, определенные в бинарнике. Возьмем программу, содержащую такое определение:
struct foo {
int a;
long fill[7];
int b;
};
При компиляции на 64-битной машине вывод pahole содержит (кроме всего прочего) информацию, показанную на рисунке 6.3.
struct foo {
int a; /* 0 4 */
/* XXX 4 bytes hole, try to pack */
long int fill[7]; /* 8 56 */
/* --- cacheline 1 boundary (64 bytes) --- */
int b; /* 64 4 */
}; /* size: 72, cachelines: 2 */
/* sum members: 64, holes: 1, sum holes: 4 */
/* padding: 4 */
/* last cacheline: 8 bytes */
Рисунок 6.3: Вывод pahole Run
Этот вывод говорит о многом. Во-первых, он показывает, что структура данных использует более одной строки кэша. Программа подразумевает размер строки кэша текущего процессора, но это значение можно изменить, используя параметры командной строки. В случаях, когда размер структуры немного превосходит размер строки кэша и в памяти распределяется много объектов этого типа, особенно имеет смысл поискать пути к сжатию такой структуры. Может быть некоторые элементы могут иметь тип меньшего размера, или может быть некоторые поля в действительности являются флагами, которые могут быть реализованы, используя отдельные биты.
В случае нашего примера сжатие получить легко, оно предлагается самой программой. Вывод показывает, что есть дыра в четыре байта после первого элемента. Дыра вызвана требованиями выравнивания структуры и элемента fill. Легко видеть, что элемент b, который имеет размер четыре байта (об этом говорит 4 в конце строки), идеально подходит к этому промежутку. Результатом в этом случае является то, что промежутка больше не существует и структура данных помещается в одну строку кэша. Программа pahole может делать такую оптимизацию сама. Если использовать параметр ---reorganize и добавить имя структуры в конце командной строки, выводом программы будет структура, оптимизированная по использованию строк кэша. Кроме перемещения элементов для заполнения промежутков, программа может оптимизировать битовые поля и комбинировать незначащие биты и дыры. Детали смотри в [1].
Иметь промежуток, достаточно большой для последующего элемента, - это, конечно, идеальная ситуация. Чтобы эта оптимизация была полезной, необходимо чтобы сам объект был выравнен по строке кэша. Остановимся на этом поподробнее.
Вывод pahole также позволяет легче определить, должны ли элементы быть переупорядочены так, чтобы элементы, которые вместе используются, вместе бы и хранились. Используя pahole, легко понять, какие элементы находятся в одной строке кэша и когда наоборот нужно переставить их, чтобы добиться этого. Это не автоматический процесс, но программа может сильно помочь.
Позиция индивидуальных элементов структуры и то, как они используются, тоже важны. Как мы уже видели в разделе 3.5.2, производительность кода с критическим словом в конце строки кэша хуже. Это означает, что программист всегда должен следовать следующим двум правилам:
- Всегда передвигать элемент структуры, который вероятнее всего будет критическим словом, в начало структуры.
- При обращении к структуре данных, когда порядок обращения не диктуется ситуацией, обращаться к элементам в том порядке, в котором они определены в структуре.
Для маленьких структур это означает, что программист должен располагать элементы в порядке, в котором они скорее всего будут использоваться. Это должно быть проделано гибко, с учетом других оптимизаций, таких как заполнение промежутков. Для более больших структур данных, эти правила должны применяться к каждому блоку размером в строку кэша.
Однако переупорядочивание элементов не стоит потраченного на него времени, если сам объект не выравнен. Выравнивание объекта определяется требованиями выравнивания типа данных. Каждый фундаментальный тип данных имеет свои требования выравнивания. Для структурных типов, наибольшие требования выравнивания из всех его элементов определяют выравнивание структуры. Это почти всегда меньше, чем размер строки кэша. Это означает, что даже если члены структуры выстроены так, чтобы попадать в одну строку кэша, сам размещенный объект может иметь выравнивание не подходящее к размеру строки кэша. Есть два пути проверить, что объект имеет выравнивание, которое использовалось при создании размещения структуры:
- объект может быть размещен в памяти с явным требованием выравнивания. При динамическом размещении вызов
mallocразместит объект с выравниванием совпадающим с выравниванием наиболее требовательного стандартного типа (обычноlong double). Однако можно использоватьposix_memalign, чтобы потребовать большего размера выравнивания.
#include <stdlib.h>
int posix_memalign(void **memptr,
size_t align,
size_t size);
Эта функция сохраняет указатель на только что выделенную память в переменной memptr. Блок памяти имеет размер size байтов и выравнен по границе в align байтов.
Для объектов, распределяемых компилятором (в .data, .bss, и т.д., в стеке) можно использовать переменную attribute:
struct strtype variable
__attribute((aligned(64)));
В этом случае variable выравнена по границе в 64 байт независимо от требования выравнивания структуры strtype. Это работает и для глобальных, и для автоматических переменных.
Однако это не работает для массивов. Только первый элемент массива будет выравнен, если размер каждого элемента массива не кратен размеру выравнивания. Это также означает, что каждая единичная переменная должна быть соответственно объявлена. Использование posix_memalign также не является полностью бесплатным, так как требования выравнивания обычно ведут к фрагментации и/или более высокому потреблению памяти.
- требование выравнивания типа может быть изменено, используя атрибут типа:
struct strtype {
...members...
} __attribute((aligned(64)));
Это заставит компилятор выделять все объекты с подходящим выравниванием, включая массивы. Однако программист должен позаботиться о запросе подходящего выравнивания для динамически размещаемых объектов. Следовательно, нужно снова использовать posix_memalign. Удобно использовать оператор alignof из gcc и передавать значение второго параметра posix_memalign.
Ранее упомянутые в этом разделе мультимедийные расширения почти всегда требуют, чтобы доступ к памяти был выравнен. То есть, для чтения из памяти по 16 байт, адрес предполагается выравненным по 16 байт. Процессоры x86 и x86-64 имеют специальные варианты операций с памятью, которые могут осуществлять невыравненный доступ, но они медленнее. Это жесткое требование выравнивания не является новым для большинства RISC архитектур, которые требуют полного выравнивания для любого доступа к памяти. Даже если архитектура поддерживает невыравненный доступ, он иногда медленнее, чем использование соответствующего выравнивания, особенно если невыравненное чтение или запись должны использовать две строки кэша вместо одной.

Рисунок 6.4: Отставание невыравненного доступа
Рисунок 6.4 показывает эффекты невыравненного доступа к памяти. Описанный выше тест измеряет время обращения к элементам данных (последовательным или произвольным в памяти), причем один раз список элементов выравнен в памяти, а один раз выравнивание намеренно нарушено. График показывает замедление программы, вызванное невыравненным доступом. Эффект более значительный для случая последовательного доступа по сравнению со случайным доступом потому что в последнем случае затраты на невыравненный доступ частично скрыты более высокими общими затратами на доступ к памяти. В случае последовательного доступа, для размеров рабочего пространства, умещающихся в кэш L2, замедление порядка 300%. Это может быть объяснено снижением эффективности кэша L1. Некоторые операции приращения теперь затрагивают две строки кэша, и обращение к элементу списка теперь требует чтения двух строк кэша. Соединение между L1 и L2 просто слишком перегружено.
Для очень больших размеров рабочего пространства эффект невыравненного доступа составляет от 20% до 30%, что все еще много, учитывая что выравненный доступ для таких размеров долог. Этот график должен показать, что к выравниванию нужно подходить серьезно. Даже если архитектура поддерживает невыравненный доступ, к нему не нужно относится так, как если бы он был так же хорош, как выравненный.
Однако, есть некоторые отступления от этих требований выравнивания. Если автоматическая переменная имеет требование выравнивания, то компилятор должен проследить, чтобы это происходило во всех случаях. Это нетривиальная задача, так как компилятор не имеет контроля над местами вызова и тем, как они обращаются со стеком. Эта проблема может быть решена двумя путями:
- Сгенерированный код активно выравнивает стек, вставляя промежутки при необходимости. Это требует от кода проверки на выравнивание, создания выравнивания и, позднее, отмены выравнивания.
- Требовать, чтобы все вызовы выравнивали стек.
Все обычно используемые двоичные интерфейсы приложений (ABI - application binary interface) идут вторым путем. Программы скорее всего дадут сбой, если вызов нарушает правило и вызываемое требует выравнивания. Однако поддержка выравнивания не дается бесплатно.
Размер стека функции не обязательно кратен размеру, по которому идет выравнивание. Это означает, что необходимо заполнение, если другие функции вызываются из этого стека. Другое дело, что размер стека в большинстве случаев известен компилятору и, следовательно, он знает как подстроить указатель стека, чтобы любая функция, вызываемая из стека была выравнена. На самом деле, большинство компиляторов просто округляют размер стека, чтобы сделать это.
Это простое решение невозможно, если используются массивы переменной длины или alloca. В этом случае общий размер стека известен только во время выполнения. В таком случае, возможно, понадобится активный контроль за выравниванием, что сделает сгенерированный код (немного) медленнее.
На некоторых архитектурах только мультимедийные расширения требуют выравнивания, стеки на таких архитектурах всегда минимально выравнены для обычных типов данных, обычно по 4 или 8 байт для 32- и 64-битовых архитектур соответственно. На таких системах принудительное выравнивание приносит ненужные затраты. Это означает, что в этом случае мы можем захотеть избавиться от строгих требований выравнивания, если мы знаем что от него ничего не зависит. Замыкающие функции (которые не вызывают другие функции), не исполняющие мультимедийных операций, не нуждаются в выравнивании. Также как и функции, которые вызывают только функции, не нуждающиеся в выравнивании. Если может быть идентифицирован достаточно большой набор функций, программа может захотеть ослабить требование выравнивания. Для бинарников x86 gcc имеет поддержку для ослабленных требований выравнивания стека:
-mpreferred-stack-boundary=2
Если в этой опции задано значение N, то требование выравнивания для стека будет задано как 2N байт. Так, если исползуется значение 2, то требование выравнивания для стека будет снижено со значения по умолчанию (которое равно 16 байт) до всего 4 байт. В большинстве случаев это означает, что не нужно никаких дополнительных операций выравнивания, так как обычные операции кэша push и pop и так работают по четырехбайтным границам. Эта машиннозависимая опция может помочь уменьшить размер кода и улучшить скорость выполнения. Но её невозможно применять на множестве других архитектур. Даже на x86-64 это в общем неприменимо, так как x86-64 ABI требует, чтобы параметры с плавающей точкой передавались в регистр SSE, а инструкции SSE требуют полного 16-байтного выравнивания. Тем не менее, когда эта опция применима, она может оказать заметное влияние.
Эффективное размещение элементов структуры и выравнивание - не единственные аспекты структур данных, которые влияют на эффективность кэша. Если используется массив структур, все определения структур влияют на производительность. Вспомните результаты на рисунке 3.11: в этом случае мы имели увеличивающийся размер неиспользуемых данных в элементах массива. Результатом было то, что предварительная выборка была все менее эффективной и программа, для больших объемов данных, стала менее эффективной.
Для больших размеров рабочего пространства важно использовать доступный кэш так хорошо, как это возможно. Чтобы добиться этого, возможно, будет необходимо преобразовать структуру данных. Хотя для программиста удобнее хранить все данные, которые концептуально объединены вместе, в одной структуре данных, это может оказаться не лучшим подходом с точки зрения производительности. Предположим, что у нас есть следующая структура данных:
struct order {
double price;
bool paid;
const char *buyer[5];
long buyer_id;
};
Далее, предположим, что эти записи хранятся в большом массиве и часто запускаемая процедура добавляет ожидаемые платежи по выставленные счетам. При таком сценарии, память, используемая для полей buyer и buyer_id, без необходимости загружается в кэш. Судя по данным рисунка 3.11, программа будет работать в 5 раз хуже, чем она могла бы.
Намного лучше разделить структуру данных order на две структуры, в первой используя первые два поля, остальные поля где-то еще. Это изменение определенно усложнит программу, но выигрыш в производительности может оправдать затраты.
И наконец, давайте рассмотрим еще одну оптимизацию использования кэша, которая, хотя и применима к другим кэшам, в первую очередь чувствуется при доступе к L1d. Как видно из рисунка 3.8, возрастающая ассоциативность кэша улучшает обычные операции. Чем больше кэш, тем обычно выше ассоциативность. Кэш L1d слишком велик, чтобы быть полностью ассоциативным, но не настолько велик, чтобы иметь такую же ассоциативность как L2. Это может быть проблемой, если много объектов рабочего пространства попадают в один и тот же набор кэша. Если это приводит к исключению из кэша из-за перегруженности набора, программа может испытывать задержки, даже если большая часть кэша свободна. Эти промахи кэша иногда называют конфликтные промахи. Так как адресация L1d использует виртуальные адреса, это то, над чем программист может иметь контроль. Если переменные, которые вместе используются, хранятся тоже вместе, то вероятность того, что они попадут в один набор минимальна. Рисунок 6.5 показывает как быстро проблема может появиться.

Рисунок 6.5: Эффекты ассоциативности кэша
На рисунке - знакомый теперь тест Follow с NPAD=15 {тест производился на 32-битной машине, следовательно NPAD=15 означает одну 64-байтную строку кэша на один элемент списка.}, измеренный специальным образом. На оси X - расстояние между двумя элементами списка, измеренное пустыми элементами списка. Другими словами, расстояние в 2 означает, что адрес следующего элемента находится через 128 байт от предыдущего. Все элементы размещены в виртуальном адресном пространстве на одном расстоянии друг от друга. Ось Y показывает общую длину списка. Используется только 16 элементов, что означает, что общее рабочее пространства будет составлять от 64 до 1024 байт. Ось Z показывает среднее количество циклов, необходимое для обхода каждого элемента списка.
Результат, показанный на рисунке, не должен вызвать удивления. Если используется мало элементов, то все они помещаются в L1d и время доступа составляет только 3 цикла на элемент списка. То же верно для почти всех размещений элементов списка: виртуальное адресное пространство отлично отображается в слоты L1d, почти без конфликтов. Есть два (на этом графике) особых значения расстояния, для которых ситуация другая. Если расстояние кратно 4096 байтам (т.е. дистанции в 64 элемента) и длина списка больше, чем восемь, то среднее количество циклов для доступа к элементу списка возрастает драматически. При такой ситуации все записи находятся в одном наборе и когда длина списка больше, чем ассоциативность, записи исключаются из L1d и должны быть заново считаны из L2 при следующем обходе. Результатом является 10 циклов на элемент списка.
Из этого графика мы можем определить, что процессор использует кэш L1d размером 32Кб и ассоциативностью 8. Это означает, что тест, при необходимости, может быть использован для определения этих значений. Те же эффекты могут быть измерены для кэша L2, но там ситуация сложнее, так как L2 использует физические адреса и он намного больше.
Для программистов это означает, что ассоциативность - это то, на что стоит обращать внимание. Размещать данные на границах, являющихся степенью двойки, в реальной жизни приходится достаточно часто, а это как раз та ситуация, которая может легко привести к описанным выше эффектам и снижению производительности. Невыравненные доступы могут увеличить вероятность конфликтных промахов, так как каждый доступ может потребовать дополнительной строки кэша.

Рисунок 6.6: Адреса банков L1d у AMD
Если выполнена такая оптимизация, то возможна ещё одна похожая оптимизация. Процессоры AMD, по крайней мере, реализуют L1d как несколько индивидуальных банков. L1d может получать два слова за цикл, но только если оба слова хранятся в разных банках, или в банке с одинаковым индексом. Адрес банка закодирован в младших битах виртуального адреса, как показано на рисунке 6.6. Если переменные, которые используются вместе, сохраняются также вместе, высока вероятность того, что они в разных банках, или в одном банке с одинаковым индексом.
[1] Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007.
[2] Drepper, Ulrich. Futexes Are Tricky., 2005. http://people.redhat.com/drepper/futex.pdf.
[3] Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. , 2005.
6.2.2 Оптимизация доступа к кэшу инструкций уровня 1
Для подготовки кода для правильного использования L1i необходимы приемы, похожие на те, что применяются при правильном использовании L1d. Проблема однако в том, что программист обычно не может прямо влиять на то, как используется L1i, если он не пишет код на ассемблере. Если используется компилятор, то программист может задать механизм использования L1i не напрямую, а руководя компилятором в составлении наилучшего устройства кода.
Код имеет то преимущество, что между переходами он линеен. В такие периоды процессор может эффективно делать предварительную загрузку памяти. Переходы нарушают эту идеальную картину из-за того что
- цель перехода может быть определена не статически;
- даже если она определена статически, загрузка памяти может занять длительное время, если эта цель отсутствует во всех кэшах.
Эти проблемы создают задержки при выполнении кода с возможным существенным снижением производительности. Вот почему современные процессоры плотно завязаны на предсказание ветвления (BP - branch prediction). Высокоспециализированные модули BP пытаются определить цель перехода настолько задолго до самого перехода, насколько возможно, так что процессор смог бы инициировать загрузку инструкций с нового места в кэш. Они используют статические и динамические правила и все лучше и лучше распознают шаблоны при исполнении кода.
Для кэша инструкций получить данные так скоро, как это возможно, еще более важно. Как упоминалось в разделе 3.1, инструкции должны быть декодированы, прежде чем они будут исполнены и, чтобы ускорить это (важно для x86 и x86-64), инструкции кэшируются в декодированной форме, а не в форме байт/слово, читаемой из памяти.
Чтобы достичь наилучшего использования L1i, программисты должны стремиться, по крайней мере, к следующим аспектам генерации кода:
- нужно уменьшать насколько возможно размер кода. Это должно быть сбалансировано с такими оптимизациями как развертывание цикла и использование встроенных функций
- исполнение кода должно быть линейным, без пузырей. {Пузырями называются дыры в конвейере процессора, которые появляются, когда процессор ожидает ресурсы. Подробности читатель может найти в литературе по дизайну процессоров.}
- нужно выравнивать код, когда это имеет смысл.
Теперь посмотрим на некоторые методы компиляторов, способные оптимизировать программы в соответствии с этими аспектами.
У компиляторов есть опции по установке уровней оптимизации, некоторые специфические оптимизации могут быть заданы отдельно. Много оптимизаций, установленных на высоких уровнях оптимизации (-O2 и -O3 для gcc), имеют дело с оптимизацией циклов и встраиванием функций. В общем, это хорошие оптимизации. Если код, оптимизированный таким образом, отвечает за значительную часть общего времени исполнения программы, общая производительность будет улучшена. Встраивание функций, в частности, позволяет компилятору оптимизировать за раз более крупные куски кода, что, в свою очередь, приводит к генерации машинного кода, который лучше использует конвейерную архитектуру процессора. Работа над кодом и данными (через dead code elimination или value range propagation и др.) идет лучше, когда более крупные части программы могут рассматриваться как единый модуль.
Более крупный размер кода означает большую нагрузку на кэши L1i (и также L2 и более высокие уровни). Это может ухудшать производительность. Маленький код может быть быстрее. К счастью gcc имеет связанную с этим опцию оптимизации. Если используется -Os, то компилятор оптимизирует размер кода. Те оптимизации, которые могут увеличить размер кода, отключаются. Использование этой опции часто приводит к неожиданным результатам. Эта опция может дать большой выигрыш, особенно если компилятор в действительности не может извлечь выгоды из развертывания циклов и использования встроенных функций.
Использованием встроенных функций можно также управлять индивидуально. У компилятора есть ограничения и эвристика, которые управляют использованием встроенных функций. Программист может управлять этими ограничениями. Опция -finline-limit определяет, насколько велика должна быть функция, чтобы считаться слишком большой для встраивания. Если функция вызывается из нескольких мест, то встраивание её во все эти места приведет к взрывному росту размера кода. И больше того. Предположим, что функция inlcand вызывается в двух функциях f1 и f2. Функции f1 и f2 сами вызываются последовательно
| Со встраиванием | Без встраивания | |
|---|---|---|
start f1 code f1 inlined inlcand more code f1 end f1 start f2 code f2 inlined inlcand more code f2 end f2 |
start inlcand code inlcand end inlcand start f1 code f1 end f1 start f2 code f2 end f2 |
Таблица 6.3: Со встраиванием и без
Таблица 6.3 показывает как может выглядеть сгенерированный код в случаях встраивания и отсутствия встраивания в обеих функциях. Если функция inlcand встроена и в f1 и в f2, то общий размер сгенерированного кода:
размер `f1` + размер `f2` + 2 × размер `inlcand`
Без встраивания общий размер меньше на размер inlcand. Вот настолько нужно больше кэша L1i и L2, если f1 и f2 вызываются одна за другой через небольшой промежуток времени. Плюс, если inlcand не встроена, то её код может быть все ещё в L1i и её не нужно будет снова декодировать. Плюс модуль предсказания ветвлений может работать лучше при предсказании переходов, так как он уже видел этот код. Если в компиляторе значение по умолчанию для верхнего предела размера встраиваемых функций не лучшее для программы, то его необходимо понизить.
Есть случаи, однако, когда встраивание всегда имеет смысл. Если функция вызывается один только раз, то её можно встроить. Это дает возможность компилятору выполнить другие оптимизации (такие как value range propagation, которая может значительно улучшить код). Такое встраивание может быть нарушено заданными ограничениями. В gcc для таких случаев имеется опция, позволяющая определить, что функция всегда встраивается. Добавление атрибута always_inline к функции заставляет компилятор всегда её встраивать.
В том же контексте, если функция никогда не должна быть встроена, несмотря на то, что она достаточно мала, можно использовать атрибут noinline. Использование этого атрибура имеет смысл даже для маленьких функций, если они вызываются часто и из разных мест. Если можно повторно использовать содержимое L1i и общий размер кода снижен, это часто оправдывает затраты на дополнительный вызов функции. Современное предсказание ветвления работает очень хорошо. Если встраивание может привести к более агрессивным оптимизациям, то все выглядит по-другому. Это то, что нужно решать в каждом конкретном случае.
Атрибут always_inline работает хорошо, если встраиваемый код всегда используется. А что если нет? Что если встраиваемая функция используется изредка?
void fct(void) {
... code block A ...
if (condition)
inlfct()
... code block C ...
}
Код, сгенерированный для такого кода, в целом совпадет со структурой источника. Это значит, что сначала будет блок A, затем условный переход, который, если условие будет вычислено как ложь, приведет к скачку вперед. Затем идет код, сгенерированный для встроенной функции inlfct и, в конце, блок кода C. Это все выглядит разумно, но есть проблема.
Если condition часто принимает значение ложь, то выполнение не будет линейным. Будет большой кусок неиспользуемого кода в центре, который не только загрязняет L1i из-за предварительной выборки, но и может вызвать проблемы с предсказанием ветвлений. Если предсказание ветвления неверно, то условный переход может быть очень неэффективным.
Это общая проблема, не специфическая только для встраиваемых функций. Всегда, когда есть однобокое условное выполнение (то есть когда выражение в условном переходе намного чаще выдает один результат, чем другой), есть потенциальная опасность неверного статического предсказания ветвления и, следовательно пузырей в конвейере. Это может быть предотвращено указанием компилятору передвинуть реже используемый код подальше от основного пути кода. В этом случае условная ветвь, сгенерированная для конструкции if, перескочит в другое место, так как показано на картинке.

Верхняя часть представляет собой простой план кода. Если часть B, то есть часть, сгенерированная для встраиваемой функции inlfct, часто пропускается при выполнении потому, что условие I перепрыгивает через него, то предварительная выборка процессором будет помещать в кэш строки, содержащие блок B, который редко используется. Используя перестановку блоков, можно изменить это и получить результат из нижней части картинки. Часто исполняемый код линеен в памяти, а редко исполняемый передвинут туда, где он не помешает предварительной выборке и эффективности L1i.
GCC предоставляет два метода, чтобы добиться этого. Во-первых, компилятор может учесть выводы программы сбора информации о выполнении при перекомпиляции кода и переставить блоки кода с учетом этого. Мы увидим как это работает в разделе 7. Второй метод использует явное предсказание ветвей. Gcc использует __builtin_expect:
long __builtin_expect(long EXP, long C);
Эта конструкция говорит компилятору о том, что выражение EXP скорее всего примет значение C. Возвращаемым значением будет EXP. Предполагается, что __builtin_expect будет использоваться с условным выражением. Почти всегда это будет выражение с булевым значением, поэтому удобно определить два вспомогательных макроса:
#define unlikely(expr) __builtin_expect(!!(expr), 0)
#define likely(expr) __builtin_expect(!!(expr), 1)
Эти макросы можно использовать так:
if (likely(a > 1))
Если программист использует эти макросы и потом использует опцию оптимизации -freorder-blocks, gcc переупорядочит блоки как на картинке выше. Эта опция включена для -O2, но выключена для -Os. Есть еще одна опция для перестановки блоков (-freorder-blocks-and-partition), но она имеет ограниченное применение, так как не работает с обработкой исключений.
Есть еще одно большое преимущество маленьких циклов, по крайней мере на некоторых процессорах. Интерфейс Intel Core 2 имеет специальное свойство, называемое Детектор Потока Цикла (Loop Stream Detector - LSD). Если цикл состоит не более чем из 18 инструкций (ни одна из которых не является вызовом подпрограммы), требует не более 4 вызовов декодера по 16 байт, имеет не более 4 инструкций ветвления и выполняется более 64 раз, то такой цикл иногда закрепляется в очереди инструкций и, следовательно, быстрее доступен при следующем использовании. Это применимо, например, к маленьким внутренним циклам, которые запускаются много раз через внешний цикл. И даже без такого специального железа компактные циклы имеют преимущества.
Встраивание - не единственный аспект оптимизации по отношению к L1i. Другой аспект - это выравнивание, так же как и для данных. Есть очевидные отличия: код является по большей части линейным двоичным объектом, который нельзя произвольным образом разместить в памяти и на который программист не влияет непосредственно, из-за того, что он генерируется компилятором. Есть, однако, некоторые аспекты, на которые программист может влиять.
Не имеет никакого смысла выравнивать каждую отдельную инструкцию. Цель состоит в том, чтобы поток инструкций был последовательным. Поэтому выравнивание имеет смысл только в стратегических местах. Чтобы решить, куда добавлять выравнивания, нужно понимать в чем могут состоять преимущества. Нахождение инструкции в начале строки кэша {Для некоторых процессоров строка кэша не совпадает с атомарными блоками инструкций. Интерфейс Intel Core 2 передает декодеру 16-байтные блоки. Они выравнены и поэтому не могут выйти за границы строк кэша. Выравнивание по началу строки кэша имеет однако преимущества, так как оптимизирует позитивный эффект предварительной выборки.} означает, что предварительная выборка строки кэша максимизирована. Для инструкций это также означает, что декодер более эффективен. Легко видеть, что если инструкция выполняется в конце строки кэша, то процессор должен подготовиться прочесть следующую строку кэша и декодировать инструкции. Но есть вещи, которые могут пойти неправильно (такие как промахи кэша), что означает, что в среднем инструкции в конце строки кэша выполняются не так эффективно, как в начале.
Соедините это с тем, что проблема может быть еще серьезнее, если управление только что было перенесено к рассматриваемой инструкции (и, следовательно, предварительная выборка неэффективна) и мы придем к окончательному заключению о том, где выравнивание наиболее полезно:
- в начале функций;
- в начале блоков, которые могут быть достигнуты только перескакиванием через предыдущий код;
- до некоторой степени в начале циклов.
В первых двух случаях выравнивание происходит с небольшими затратами. Выполнение кода продолжается с нового места, и если мы разместим его в начале строки кэша, то мы оптимизируем предварительную выборку и декодирование. {Для декодирования инструкций процессоры часто используют меньший чем размер строки кэша блок, 16-байтный в случае x86 и x86-64.} Компилятор выполняет выравнивание, вставляя где нужно инструкции no-op, чтобы заполнить пустые места, созданные выравниванием. Этот ⌠мертвый код■ занимает немного места и обычно не влияет на производительность.
Третий случай немного отличается: выравнивание начала каждого прохода цикла может создать проблемы для производительности. Проблема в том, что к началу цикла программа часто подходит последовательно. При неудачных обстоятельствах выравнивание начала цикла приведет к появлению пустоты между началом цикла и предыдущей инструкцией. В отличие от первых двух случаев, эта пустота не может быть мертвым кодом. После предыдущей инструкции должна исполняться первая инструкция цикла. Это означает, что после предыдущей инструкции нужно вставить или несколько инструкций no-op, или бузусловный переход к первой инструкции цикла. Ни то, ни другое не бесплатно. Если цикл выполняется немного раз, то эти инструкции no-op или безусловный переход могут стоить больше, чем выигрыш от выравнивания цикла.
Есть три способа, с помощью которых программист может влиять на выравнивание кода. Очевидно, что если код написан на ассемблере, то функция и все инструкции могут быть явным образом выравнены. Для этого ассемблер предоставляет для всех архитектур директиву .align. Для языков высокого уровня нужно сообщать компилятору о требованиях выравнивания. В отличие от типов данных и переменных, это невозможно сделать в исходном коде. Вместо этого используется опция компиляции:
-falign-functions=N
Эта опция заставляет компилятор выравнивать все функции по ближайшей большей N степени двойки. Это означает, что появляется дыра размером до N байт. Для маленьких функций использование большого значения N будет расточительством. Равно как и для кода, который выполняется редко. Последнее может часто происходить в библиотеках, которые могут содержать как популярные, так и не очень популярные интерфейсы. Мудрый выбор этой опции может ускорить выполнение или сохранить память избегая выравнивания. Все выравнивание может быть отключено используя единицу в качестве значения N или используя опцию -fno-align-functions.
Выравнивание для второго случая, упомянутого выше --- в начале блоков, которые могут быть достигнуты только перескакиванием через предыдущий код --- может контролироваться другой опцией
-falign-jumps=N
Все остальные детали эквивалентны, применимо то же предупреждение о ненужном расходе памяти.
Третий случай также имеет свою опцию:
-falign-loops=N
И снова применимы те же детали и предупреждения. Исключая то, что, как объяснялось выше, выравнивание отрицательно влияет на выполнение, так как либо инструкции no-op, либо бузусловный переход должны быть выполнены, если выравниваемый адрес достигается последовательно.
У gcc есть ещё одна опция для контроля над выравниванием, которую упомянем только для полноты. Опция -falign-labels выравнивает каждый ярлык в коде (в основном начало каждого блока). Это всегда, кроме редких исключений, замедляет код и, следовательно, не должно использоваться.
6.2.3 Оптимизация доступа к кэшу уровня 2 и выше
Все, что было сказано об оптимизации кэша уровня 1 также применимо и к уровню 2 и выше. Есть два дополнительных аспекта для кэша последнего уровня:
- промахи кэша всегда очень дороги. В то время как промахи L1 (вероятно) часто будут найдены в L2 или более высоких уровнях кэша, ограничивая, следовательно, ущерб, у кэша последнего уровня такого резерва, очевидно, нет.
- кэш уровня L2 и выше часто является общим для нескольких ядер и/или гиперпотоков. Следовательно эффективный размер кэша, доступный для каждого модуля исполнения, обычно меньше, чем общий размер кэша.
Чтобы избежать высоких затрат при промахах кэша, размер рабочего пространства должен соответствовать размеру кэша. Если данные используются только один раз, то и это необязательно, так как кэш все равно будет неэффективным. Мы говорим о такой работе, при которой набор данных используется больше, чем один раз. В этом случае использование рабочего пространства слишком большого, чтобы поместиться в кэш, приведет к большому количеству промахов кэша, которые, даже если предварительная выборка будет успешно работать, замедлят программу.
Программа должна делать свою работу, даже если набор данных очень велик. Это задача программиста - организовать работу так, чтобы минимизировать промахи кэша. Для кэшей последного уровня, так же как и для L1, это возможно, если разбивать задачу на маленькие кусочки. Это очень похоже на оптимизацию умножения матриц в таблице 6.2. Одно различие состоит в том, что блоки данных, над которыми нужно работать, могут быть больше. Код становится ещё сложнее, если оптимизация работы с L1 также нужна. Вообразите умножение матриц, при котором наборы данных (две исходные матрицы и матрица результата) не помещаются вместе в кэш последнего уровня. В этом случае возможно придется оптимизировать доступ к L1 и кэшу последнего уровня одновременно.
Размер строки кэша L1 обычно постоянен для многих поколений процессоров, и даже если это не так, то разница будет невелика. Не представляет большой проблемы предполагать больший размер. На процессорах с меньшим размером будет использоваться две или более строк кэша вместо одной. В любом случае будет разумным оптимизитовать код под размер строки кэша.
Для кэшей высокого уровня это не так, если предполагается, что программа будет универсальной. Размеры этих кэшей могут варьироваться в широких пределах. Различие в 8 раз не является чем-то необычным. Невозможно предположить большой размер кэша как значение по умолчанию, так как это будет означать, что код будет выполняться плохо на всех машинах, кроме тех, у которых действительно такой большой кэш. Противоположный выбор также плох - предполагая самый маленький кэш, мы отбросим 87% кэша или больше. Это плохо, как мы можем увидеть из рисунка 3.14, использование большого кэша может иметь огромный эффект на скорость программы.
Все это означает, что код должен динамически подстраиваться под размер строки кэша. Эта оптимизация индивидуальна для программы. Все что мы можем сказать здесь - это то, что программист должен корректно вычислить требования программы. Нужны не только сами наборы данных, кэши высшего уровня также используются для других целей, например все выполняемые инструкции загружаются из кэша. Если используются библиотечные функции, то использование кэша может подскочить до значительных размеров. Этим библиотечным функциям могут понадобиться собственные данные, что ещё более уменьшит доступную память.
Как только у нас есть формула требований памяти, мы можем сравнить её с размером кэша. Как упоминалось ранее, кэш может быть общим для нескольких ядер. В настоящее время {Определенно когда-нибудь будет лучшее решение!} единственный путь получить корректную информацию без знания тонкостей устройства аппаратуры - это через файловую систему /sys. В таблице 5.2 мы видим, что ядро сообщает об аппаратном обеспечении. Программа должна найти директорию:
/sys/devices/system/cpu/cpu*/cache
для кэша последнего уровня. Её можно узнать по наивысшему числовому значению в файле level этой директории. Когда директория идентифицирована, программа должна прочитать содержимое файла size в этой директории и разделить числовое значение на число бит, заданное в маске в файле shared_cpu_map.
Значение, подсчитанное таким образом - это безопасный нижний предел. Иногда программа знает немного больше о поведении остальных потоков и процессов. Если эти потоки запланированы при разделении кэша ядрами или гиперпотоками, и использование кэша при этом не полностью задействует свою долю общего размера кэша, тогда вычисленный предел может быть меньше оптимального. Нужно ли увеличивать эту долю, зависит от ситуации. Программист должен сделать выбор или позволить сделать выбор пользователю.
6.2.4 Оптимизация использования TLB
Есть два вида оптимизации использования TLB. Первый вид оптимизации - это снизить количество страниц, которые использует программа. Это автоматически приводит к снижению количества промахов TLB. Второй вид оптимизации - это сделать поиск TLB дешевле снижением количества страниц каталога высокого уровня, которые должны быть размещены в памяти. Меньшее количество страниц означает меньшее использование памяти, что может привести к более высокому проценту попаданий кэша при поиске в каталоге.
Первая оптимизация тесно связана с минимизацией ошибок страниц. Мы подробнее обсудим эту тему в разделе 7.5. В то время как ошибки страниц - это обычно одноразовые потери, промахи TLB - это потери постоянные, учитывая то, что кэш TLB обычно маленький и часто очищается. Ошибки страниц обходятся дороже на порядки, чем промахи TLB, но если программа выполняется достаточно долго и определенные части программы выполняются достаточно часто, то промахи TLB могут даже перевесить ошибки страниц. Следовательно, важно рассматривать оптимизацию страниц не только как связанную с ошибками страниц, но и с промахами TLB тоже. Разница здесь в том, что в то время как оптимизация ошибок страниц требует только группировки кода и данных по ширине страницы, оптимизация TLB требует, чтобы в каждый момент времени использовалось как можно меньше записей TLB.
Вторую оптимизацию TLB ещё тяжелее контролировать. Количество используемых каталогов страниц зависит от распределения диапазонов адресов, используемых в виртуальном адресном пространстве процесса. Широко варьирующиеся местоположения в адресном пространстве означают большее количество каталогов. Сложность состоит в том, что рандомизация местоположения адресов (ASLR - Address Space Layout Randomization) как раз и приводит к такой ситуации. Загрузка адресов стека, DSO, кучи и, возможно, исполняемого файла рандомизируется во время выполнения, для того чтобы предотвратить атаки на машину с помощью подбора адресов функций или переменных.
Для максимальной производительности ASLR определенно должна быть отключена. Однако стоимость дополнительных каталогов довольно низкая, чтобы сделать этот шаг ненужным всегда, кроме нескольких экстремальных случаев. Одна возможная оптимизация, которую ядро может выполнить в любое время, - это убедится, что каждое отображение не нарушает границы адресного пространства между двумя каталогами. Это немного ограничит ASLR, но не настолько, чтобы существенно ослабить её.
Единственный случай, когда программист непосредственно сталкивается с этим, - это когда регион адресного пространства запрашивается явным образом. Это получается при использовании mmap с MAP_FIXED. Распределять новый регион адресного пространства таким образом очень опасно и это редко используется. Это однако возможно и, если это используется, то программист должен знать о границах каталогов страниц последнего уровня и выбирать запрашиваемый адрес подходящим образом.
6.3 Предварительная загрузка
Цель предварительной загрузки состоит в том, чтобы спрятать задержку доступа к памяти. Конвейер команд и способность современных процессоров выполнять их не по порядку (OOO - out-of-order), позволяет прятать часть задержки, но, в лучшем случае, для тех доступов к памяти, которые находятся в кэше. Чтобы покрыть задержку доступа к основной памяти, очередь команд должна быть невероятно большой. Некоторые процессоры без OOO пытаются компенсировать это увеличением числа ядер, но это не равноценный обмен, если только весь используемый код не распараллелен.
Предварительная загрузка может помочь ещё больше скрыть задержку. Процессор выполняет предварительную загрузку сам, вследствие наступления определенных событий (аппаратная предварительная загрузка) или по запросу от программы (программная предварительная загрузка).
6.3.1 Аппаратная предварительная загрузка
Триггером аппаратной предварительной загрузки обычно являются два или более промаха кэша, соответствующие определенному образцу. Эти промахи кэша могут быть в последующей или предыдущей строке кэша. В старых реализациях распознавались только промахи кэша в смежных строках. В современной аппаратуре распознаются и более дальние промахи, то есть промах через фиксированное количество строк кэша тоже подходит под образец и обрабатывается соответственно.
Для производительности было бы плохо, если бы каждый промах кэша вызывал аппаратную предварительную загрузку. Случайный доступ к памяти, например к глобальным переменным, - дело обычное и предварительная загрузка привела бы только к ненужным тратам пропускной способности FSB. Вот почему для того, чтобы начать предварительную загрузку, требуется по крайней мере два промаха кэша. Современные процессоры всегда предполагают, что есть больше чем один поток доступов к памяти. Процессор пытается автоматически присвоить промах кэша такому потоку, и если достигнуто предельное значение, начинает аппаратную предварительную загрузку. Современные процессоры могут отслеживать от восьми до шестнадцати различных потоков для высших уровней кэша.
Модули, отвечающие за распознавание образцов, закреплены за соответствующими кэшами. Могут иметься модули предварительной загрузки для кэшей L1d и L1i. Очень большая вероятность того, что имеется модуль для кэшей L2 и выше. Этот модуль для L2 и выше разделяется между всеми ядрами и гиперпотоками, использующими общий кэш. Следовательно количество от восьми до шестнадцати отдельных потоков быстро уменьшается.
Предварительная загрузка имеет одну большую слабость - она ме может пересекать границы страницы. Причина должна быть очевидной, если вспомнить, что ЦПУ поддерживают выделение страниц по запросу. Если модуль предварительной загрузки сможет пересекать границы страницы, то такой доступ пожет породить событие операционной системы, делающее эту страницу доступной. Это само по себе плохо, особенно для производительности. Что еще хуже, это то, что модуль предварительной загрузки ничего не знает о семантике программы и самой операционной системы. Это может, следовательно, привести к предварительной загрузке страниц, которые в реальной жизни никогда бы не потребовались. Это означает, что модуль предварительной загрузки вышел бы край региона памяти, к которому процессор до этого имел доступ по узнаваемому образцу. Это не только возможно, так скорее всего и будет. Если процессор вызовет, как побочный эффект предварительной загрузки, запрос такой страницы, операционная система может быть совсем сбита с толку, если такой запрос в противном случая никогда бы не состоялся.
Следовательно важно понимать, что независимо от того, насколько хорош модуль предварительной загрузки в предсказании по образцу, программа будет получать промахи кэша на границе страницы, если она явно не делает предварительную загрузку или не читает из новой страницы. Это ещё одна причина оптимизировать размещение данных, как описано в разделе 6.2, чтобы минимизировать загрязнение кэша, не помещая туда несвязанные данные.
Из-за этого ограничения со страницами процессоры не имеют очень уж сложной логики распознавания образцов для предварительной загрузки. С все еще доминирующим размером страниц в 4Кб не имеет смысла делать логику сложнее. Диапазон адресов, в которых распознаются образцы, увеличивался с годами, но, возможно, не имеет смысла делать его больше чем 512 байт, как сегодня часто делают. В настоящее время модули предварительной загрузки не распознают нелинейные образцы доступа. Больше вероятность того, что такие образцы действительно случайного характера, или, по крайней мере повторяются достаточно редко, чтобы имело смысл пытаться распознать их.
Если аппаратная предварительная загрузка запускается не в нужный момент, то можно сделать немного. Одна возможность - это попытаться выявить эту проблему и немного изменить расположение данных и/или кода. С этим придется, наверное, повозиться. Могут быть специалные локализованные решения, как например использование инструкции ud2 {или не-инструкции. Это рекомендованный неопределенный машинный код.} на процессорах x86 и x86-64. Эта инструкция, которая сама по себе не выполняется, используется после неявной инструкции перехода. Она используется как сигнал загрузчику инструкций, что процессор не должен тратить усилия на декодирование последующей памяти, так как выполнение продолжится с другого места. Однако это очень особая ситуация. В большинстве случаев приходится жить с этой проблемой.
Возможно полное или частичное отключение аппаратной предварительной загрузки для всего процессора. На процессорах Intel для этого используется регистр MSR - Model Specific Register (IA32_MISC_ENABLE, бит 9 на многих процессорах; бит 19 отключает только предварительную загрузку смежных строк кэша). Это, в большинстве случаев, должно происходить в ядре, так как это привилегированная операция. Если профилирование показывает, что важное приложение, работающее в системе, страдает от нехватки полосы пропускания и преждевременного исключения из кэша, возникающего из-за аппаратной предварительной загрузки, то использование MSR возможно.
6.3.2 Программная предварительная загрузка
Преимущество аппаратной загрузки в том, что программу не нужно подстраивать. Недостатки, как только что было описано, в том, что образцы доступа должны быть тривиальными и предварительная загрузка не может пересекать границы страниц. По этим причинам у нас есть больше возможностей, программная предварительная загрузка - самая важная из них. Программная предварительная загрузка требует модификации исходного кода встраиванием специальных инструкций. Некоторые компиляторы поддерживают псевдокомментарии, для того чтобы более или менее автоматически вставлять инструкции предварительной загрузки. На x86 и x86-64 для того, чтобы вставлять эти специальные инструкции, используется соглашение Intel по встроенным функциям компилятора:
#include <xmmintrin.h>
enum _mm_hint
{
_MM_HINT_T0 = 3,
_MM_HINT_T1 = 2,
_MM_HINT_T2 = 1,
_MM_HINT_NTA = 0
};
void _mm_prefetch(void *p,
enum _mm_hint h);
Программы могут применять эту функцию _mm_prefetch к любому указателю программы. Большинство процессоров (определенно все процессоры x86 и x86-64) игнорируют ошибки, возникающие из-за недействительных указателей, что делает жизнь программиста существенно проще. Однако, если переданный указатель ссылается на действительную память, то модуль предварительной загрузки будет проинструктирован загрузить эти данные в кэш и, если нужно, вытеснить другие данные. Нужно избегать необязательных предварительных загрузок, так как они могут снизить эффективность кэша и потребляют пропускную способность памяти (возможно даже на величину двух строк кэша, если вытесняемая строка грязная).
То, какие следует использовать значения параметров функции _mm_prefetch, определяется её реализацией. Это означает, что каждая версия процессора реализует её (немного) по-разному. В общем можно сказать, что _MM_HINT_T0 загружает данные на все уровни инклюзивного кэша и на нижние уровни эксклюзивного кэша. Если элемент данных находится в высших уровнях кэша, то он загружантся в L1d. Индикатор _MM_HINT_T1 помещает данные в L2, но не в L1d. Если есть L3, то _MM_HINT_T2 делает нечто подобное. Есть однако детали, которые слабо документированы и нуждаются в проверке для каждого используемого процессора. В общем, если данные должны использоваться немедленно, то использование _MM_HINT_T0 будет правильным выбором. Конечно, это требует того, чтобы размер кэша L1d был достаточно велик, чтобы содержать все предварительно загруженные данные. Если размер немедленно используемого рабочего пространства слишком велик, то предварительная загрузка всего его в L1d будет прохой идеей и нужно использовать другие два индикатора.
Четвертый индикатор, _MM_HINT_NTA, особый, в том смысле, что он говорит процессору о том, чтобы обращаться с предварительно выбранной строкой кэша по-особому. Мы уже объясняли в разделе 6.1 что такое NTA (non-temporal aligned). Программа говорит процессору о том, что не нужно загрязнять кэш этими данными, так как они используются только короткое время. Процессор может, следовательно, во время загрузки, отказаться от чтения данных в кэш нижнего уровня для инклюзивных реализаций кэша. Когда данные выталкиваются из L1d, их не нужно помещать в L2 или выше, но можно наоборот записать прямо в память. Могут быть и другие трюки, внедренные дизайнерами процессоров, если задан этот индикатор. Программист должен быть осторожен при использовании этого индикатора: если размер немедленно испльзуемого рабочего пространства слишком велик и приводит к исключению из кэша строки, загруженной с индикатором NTA, произойдет перезагрузка из памяти.

Рисунок 6.7: Среднее с предварительной загрузкой, NPAD=31
Рисунок 6.7 показывает результаты теста, использующего знакомый теперь алгоритм погони за указателями. Список рандомизирован. Отличие от предыдущего теста в том, что программа теперь тратит некоторое время на каждый узел списка (около 160 циклов). Как мы знаем из данных рисунка 3.15, производительность программы сильно падает, когда размер рабочего пространства начинает превышать размер кэша последнего уровня.
Теперь мы можем попытаться улучшить ситуацию выпуская запросы на предварительную загрузку перед вычислением. То есть при каждом обходе цикла мы предварительно загружаем новый элемент. Расстояние между предварительно загружаемым узлом в списке и узлом, над которым идет работа, должно быть тщательно выбрано. Имея в виду, что каждый узел обрабатывается за 160 циклов и что мы должны предварительно загрузить две строки кэша (NPAD=31), расстояние в пять элементов списка будет достаточным.
Результаты на рисунке 6.7 показывают, что предварительная загрузка действительно помогает. Пока размер рабочего пространства не превышает размера кэша последнего уровня (машина имеет 512Кб = 219Б L2), числа совпадают. Инструкции предварительной загрузки не накладывают заметной дополнительной нагрузки. Как только размер L2 превышен, предварительная загрузка экономит от 50 до 60 циклов, или до 8%. Использование предварительной загрузки не прячет весь ущерб, но немного помогает.
AMD внедряет в 10 модели семейства Opteron другую инструкцию: prefetchw. Эта инструкция пока не имеет эквивалента у Intel и не доступна через встроенные функции компилятора. Инструкция prefetchw предварительно загружает строку кэша в L1 так же как и другие инструкции предварительной загрузки. Разница в том, что строка кэша немедленно переходит в состояние 'M'. Это будет недостатком, если потом не последует никакой записи в строку кэша. Если есть одна или более запись, то они будут ускорены, так как им не нужно будет изменять состояние кэша - оно уже было изменено, когда строка кэша была предварительно загружена.
Предварительная загрузка может дать гораздо больше, чем скромные 8%, которые мы получили. Но это очень трудно сделать правильно, особенно если один и тот же бинарник предполагается использовать на большом разнообразии машин. Счетчики производительности, предоставляемые ЦПУ, могут помочь программисту анализировать предварительные загрузки. События, которые могут быть подсчитаны и сравнены, включают аппаратные предварительные загрузки, программные предварительные загрузки, полезные программные предварительные загрузки, промахи кэша на разных уровнях и т.д. В разделе 7.1 мы опишем многие такие события. Все эти счетчики специфичны для каждой машины.
При анализе программ, в первую очередь нужно смотреть на промахи кэша. Когда найден большой источник промахов кэша, нужно попытаться добавить инструкции предварительной загрузки для проблематичных доступов к памяти. Добавлять эти инструкции нужно по одной за раз. Результат каждой модификации нужно проверять с помощью счетчиков, измеряющих полезные программные предварительные загрузки. Если результаты этих счетчиков не повышаются, то предварительная загрузка может быть неверна, у неё может быть слишком мало времени для загрузки из памяти, или она выталкивает из кэша память, которая все еще нужна.
Сегодня gcc может выпускать инструкции предварительной загрузки автоматически в одной ситуации. Если цикл проходит по массиву, то можно использовать следующую опцию:
-fprefetch-loop-arrays
Компилятор посчитает, имеет ли предварительная загрузка смысл, и если да, то насколько далеко вперед она должна смотреть. Для небольших массивов это может не быть полезным, если величина массива неизвестна, то результаты могут ухудшиться. Руководство по gcc предупреждает, что польза этого действия зависит от формы кода и в некоторых ситуациях код может выполняться медленнее. Программисты должны использовать эту опцию осторожно.
6.3.3 Специальный вид предварительной загрузки: условная загрузка
Способность процессора выполнять инструкции не по порядку позволяет передвигать инструкции, если они не конфликтуют друг с другом. Например (в этом примере используется IA-64):
st8 [r4] = 12
add r5 = r6, r7;;
st8 [r18] = r5
Этот код сохраняет 12 в адресе, заданном регистром r4, суммирует содержимое регистров r6 и r7 и сохраняет сумму в регистре r5. И в конце сумма сохраняется в адресе, заданном регистром r18. Смысл здесь в том, что инструкция суммирования может быть выполнена до, или одновременно, первой инструкции st8, так как нет зависимости данных. Но что произойдет, если одно из слагаемых нужно загрузить?
st8 [r4] = 12
ld8 r6 = [r8];;
add r5 = r6, r7;;
st8 [r18] = r5
Дополнительная инструкция ld8 загружает значение из адреса, заданного в регистре r8. Есть очевидная зависимость данных между инструкцией загрузки и последующей инструкцией add (вот почему после инструкции стоит ;;, спасибо за вопрос). Критично здесь то, что новая инструкция ld8, в отличие от инструкции add, не может быть помещена перед первой st8. Процессор не может достаточно быстро определить при декодировании инструкций, конфликтуют ли сохранение и загрузка, то есть имеют ли r4 и r8 одинаковое значение. Если они действительно имеют одинаковое значение, то инструкция st8 определяет значение, загружаемое в r6. Что ещё хуже, ld8 может сделать это с большой задержкой, если произойдет промах кэша. Для этого случая архитектура IA-64 поддерживает условную загрузку:
ld8.a r6 = [r8];;
[... other instructions ...]
st8 [r4] = 12
ld8.c.clr r6 = [r8];;
add r5 = r6, r7;;
st8 [r18] = r5
Новые инструкции ld8.a и ld8.c.clr связаны друг с другом и заменяют инструкцию ld8 из предыдущего примера кода. Инструкция ld8.a - это условная загрузка. Значение не может быть использовано сразу, но процессор может начать работу. К тому моменту, когда будет достигнута инструкция ld8.c.clr, содержимое уже наверное будет загружено (если в промежутке будет достаточное количество инструкций). Аргументы этой инструкции должны совпадать с аргументами инструкции ld8.a. Если предшествующая инструкция st8 не перезаписала значение (то есть r4 и r8 одинаковые), то ничего не нужно делать. Условная загрузка делает свое дело и задержка загрузки спрятана. Если загрузка и сохранение конфликтуют, то ld8.c.clr снова делает загрузку из памяти и мы имеем семантику обычной инструкции ld8.
Условная загрузка (пока?) не является распостраненной. Но, как показывает пример, - это простой и очень эффективный способ скрыть задержки. Предварительная загрузка в основном делает то же самое, поэтому для процессоров с небольшим количеством регистров условная загрузка вероятно не имеет большого смысла. Условная загрузка имеет (иногда большое) преимущество в том, что значение загружается непосредственно в регистр, а не в строку кэша, откуда оно может быть снова исключено (например когда процессор временно переключается на работу с другим потоком). Если условная загрузка доступна, её следует использовать.
6.3.4 Вспомогательные потоки
Если кто-то пытается использовать программную предварительную загрузку, он часто сталкивается со сложностью кода. Если код проводит итерацию по некоторой структуре данных (по списку в нашем случае), то придется строить две независимые итерации в том же цикле: обычная итерация проделывает работу, а вторая итерация смотрит вперед, обеспечивая предварительную загрузку. Это может усложнить код и привести к ошибкам.
Далее, нужно определить, насколько далеко вторая итерация должна смотреть вперед. Если ненамного, то память не будет загружена вовремя. Если слишком намного, то только что загруженные данные могут быть снова исключены из кэша. Ещё одна проблема состоит в том, что инструкции предварительной загрузки, хотя они и не блокируют и не ждут пока память загрузится, отнимают время. Инструкции нужно декодировать, что может стать заметным, если декодер очень занят, например из-за хорошо написанного/сгенерированного кода. И наконец, размер кода цикла увеличивается. Это снижает эффективность L1i. Если пытаться избежать части этих затрат, выпуская несколько запросов на предварительную выборку зараз (в случае если вторая загрузка не зависит от результата первой), то можно столкнуться с проблемой появления невыполненных запросов на предварительную выборку.
Альтернативный подход состоит в том, чтобы выполнять обычные операции и предварительную загрузку совершенно независимо. Этого можно добиться используя два стандартных потока. Потоки, очевидно, должны быть запланированы так, чтобы поток предварительной загрузки заполнял кэш, используемый обоими потоками. Есть два специальных решения, достойных упоминания:
- Использовать гиперпотоки (см. рисунок 3.22) на одном ядре. В этом случае предварительная загрузка пойдет в L2 (или даже L1d).
- Использовать ⌠глупые потоки, которые в отличие от потоков SMT могут делать только предварительную загрузку и другие простые операции. Это опция, которую производители процессоров должны исследовать.
Использование гиперпотоков особенно интересно. Как мы видели на рисунке 3.22, разделение кэша является проблемой, когда гиперпотоки выполняют независимый код. Если наоборот, один поток используется как вспомогательный для предварительной загрузки, то проблемы нет. Напротив, это желаемый эффект, так как предварительная загрузка идет в кэш низшего уровня. Кроме того, так как поток предварительной загрузки по большей части бездействует или ждет память, обычные операции другого вспомогательного потока не сильно страдают, если он не должен сам обращаться к основной памяти. Последнее - это в точности то, что вспомогательный поток предварительной загрузки предотвращает.
Единственная хитрость здесь в том, чтобы сделать так, что вспомогательный поток не будет убегать слишком далеко вперед. Он на должен полностью заполнить кэш, так что самые старые предварительно загруженные данные были бы снова исключены. На Linux синхронизация легко может быть сделана при помощи системного вызова futex (см. [2]) или, с немного большими затратами, используя примитивы синхронизации потоков POSIX.

Рисунок 6.8: Среднее с вспомогательными потоками, NPAD=31
Преимущества такого подхода можно видеть на рисунке 6.8. Это тот же тест, что и на рисунке 6.7, только добавлен ещё один результат. Новый тест создает вспомогательный поток, который идет примерно на 100 записей впереди и читает (а не только делает предварительную загрузку) все строки кэша каждого элемента списка. Для этого случая мы имеем по две строки кэша на каждый элемент списка (NPAD=31 на 32-битной машине с 64-байтной строкой кэша).
Два потока запланированы на гиперпотоках на одном ядре. Тестовая машина имела только одно ядро, но результаты будут примерно те же, если ядер будет больше. Функции родства, которые мы введем в разделе 6.4.3, будут использоваться для связывания потока с соответствующим гиперпотоком.
Чтобы определить какие два (или более) процессора, которые видит операционная система, на самом деле являются гиперпотоками, можно использовать интерфейс NUMA_cpu_level_mask из libNUMA (см раздел 12).
#include <libNUMA.h>
ssize_t NUMA_cpu_level_mask(size_t destsize,
cpu_set_t *dest,
size_t srcsize,
const cpu_set_t*src,
unsigned int level);
Этот интерфейс можно использовать для того, чтобы определить иерархию процессоров и то, как они соединены через кэш и память. Нам здесь интересен уровень 1, который соответствует гиперпотокам. Чтобы запланировать два потока на двух гиперпотоках можно использовать функции libNUMA (обработка ошибок для краткости опущена):
cpu_set_t self;
NUMA_cpu_self_current_mask(sizeof(self),
&self);
cpu_set_t hts;
NUMA_cpu_level_mask(sizeof(hts), &hts,
sizeof(self), &self, 1);
CPU_XOR(&hts, &hts, &self);
После того, как этот код выполнен, мы имеем два набора битов ЦПУ. Можно использовать self, чтобы задать родство текущего потока и маска hts может быть использована, чтобы задать родство вспомогательного потока. В идеале, это должно случиться перед тем, как поток создан. В разделе 6.4.3 мы опишем интерфейс для задания родства. Если в наличии нет гиперпотоков, то NUMA_cpu_level_mask вернет 1. Это можно использовать как сигнал о том, что данной оптимизации делать не нужно.
Результат этого теста может показаться удивительным (а может и нет). Если рабочее пространство помещается в L2, то накладные расходы на вспомогательный процесс снижают производительность от 10% до 60% (мы снова игнорируем самые маленькие размеры рабочего пространства, так как в этом случае результаты неразличмы на уровне шума). Этого можно было ожидать, так как если данные уже в кэше L2, то вспомогательный процесс предварительной загрузки не помогает выполнению, а только зря расходует системные ресурсы.
Однако когда L2 исчерпан, картина меняется. Вспомогательный поток предварительной загрузки помогает сократить время выполнения примерно на 25%. Мы все еще видим восходящую кривую просто потому, что предварительная загрузка не может быть обработана достаточно быстро. Однако арифметические операции, выполняемые основным потоком и операции загрузки памяти вспомогательного потока дополняют друг друга. Соревнование за ресурсы минимально, что дает этот синергетический эффект.
Результаты этого теста могут быть перенесены на многие другие ситуации. Гиперпотоки, часто бесполезные из-за загрязнения кэша, в таких ситуациях блистают, и их преимущества нужно использовать. Файловая система sys позволяет программе найти родственные потоки (см. колонку thread_siblings в таблице 5.3). Если информация доступна, то программе просто нужно задать родство потоков и затем обходить цикл в двух режимах: обычные операции и предварительная загрузка. Количество предварительно загружаемой памяти должно зависеть от размера разделяемого кэша. В этом примере имеет значение размер L2 и программа может запросить этот размер используя
sysconf(_SC_LEVEL2_CACHE_SIZE)
Нужно или нет ограничивать движение вспомогательного потока - зависит от программы. В общем случае лучше всего убедиться, что есть какая-то синхронизация, иначе детали планирования могут вызвать значительный упадок производительности.
[1] Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007.
[2] Drepper, Ulrich. Futexes Are Tricky., 2005. http://people.redhat.com/drepper/futex.pdf.
[3] Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. , 2005.
6.3.5 Прямой доступ к кэшу
Один из источников промахов кэша в современных операционных системах - это обслуживание внешнего потока данных. Современное аппаратное обеспечение, такое как сетевые карты и дисковые контроллеры, имеет способность записывать получаемые или читать данные прямо в память, не задействуя процессор. Это играет решающую роль для производительности устройств, которые мы сегодня имеем, но это также создает проблемы. Предположим из сети прибывает пакет и операционная система должна решить что с ним делать, посмотрев на его заголовок. Сетевая карта помещает пакет в память и оповещает процессор о его прибытии. У процессора нет шансов на предварительную загрузку этих данных, так как он не знает, когда эти данные прибудут, и может быть даже где конкретно они будут сохранены. Результатом будет промах кэша при чтении заголовка.
Intel добавил в свои чипсеты и процессоры технологию, призванную смягчить эту проблему (см.[3]). Идея состоит в том, чтобы заполнить кэш процессора, который будет извещен о прибытии пакета, данными этого пакета. Полезная загрузка пакета здесь не критична, эти данные, в общем, будут обрабатываться функциями более высокого уровня, или в ядре или на пользовательском уровне. Заголовок ядра используется для того, чтобы принять решение о том, что делать с этим пакетом, поэтому эти данные нужны немедленно.
У сетевой системы ввода/вывода уже есть прямой доступ к память, чтобы записать пакет. Это означает, что она взаимодействует непосредственно с контроллером памяти, который возможно интегрирован в Северный мост. Другая часть контроллера памяти - это интерфейс к процессорам через FSB (в предположении, что контроллер памяти не интегрирован в сам процессор).
Идея прямого доступа к кэшу (DCA - Direct Cache Access) состоит в том, чтобы расширить протокол между сетевой картой и контроллером памяти. На рисунке 6.9 первая картинка показывает начало передачи данных с прямым доступом к памяти на обычной машине с Южным и Северным мостами.
 |
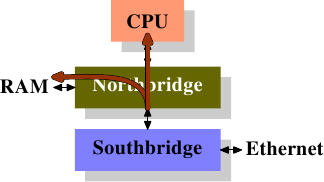 |
|---|---|
| DMA Initiated | DMA and DCA Executed |
Рисунок 6.9: Прямой доступ к кэшу
Сетевая карта присоединена к Южному мосту (или является его частью). Она начинает прямой доступ к памяти, но предоставляет новую информацию о заголовке пакета, которая должна быть помещена в кэш процессора.
Традиционное поведение предполагает, что на втором шаге прямой доступ к памяти просто завершается присоединением к памяти. Для передачи данных прямым доступом к памяти с включенным флагом DCA Северный мост дополнительно посылает данные по FSB со специальным новым флагом DCA. Процессор просматривает FSB и, если он обнаруживает флаг DCA, то он пытается загрузить данные, направленные процессору в нижний уровень кэша. Флаг DCA - это просто индикатор, процессор может просто игнорировать его. После того, как передача с прямым доступом к памяти завершена, процессор извещается об этом.
Когда операционная система обрабатывает пакет, ей в первую очередь нужно определить какого он типа. Если индикатор DCA не игнорируется, то загрузки, необходимые операционной системе для того, чтобы идентифицировать пакет, скорее всего приведут к попаданию в кэш. Умножте эту экономию сотен циклов на пакет на десятки тысяч пакетов, которые процессор обрабатывает за секунду, и экономия составит очень значительную величину, особенно когда дело касается задержки.
Без этой интеграции между аппаратурой ввода/вывода (в данном случае сетевой картой), чипсетом и процессорами, такая оптимизация невозможна. Следовательно, при выборе платформы нужно учитывать, понадобится ли эта технология.
[1] Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007.
[2] Drepper, Ulrich. Futexes Are Tricky., 2005. http://people.redhat.com/drepper/futex.pdf.
[3] Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. , 2005.
6 На что еще способны программисты
6.4 Многопотоковая оптимизация
Говоря о многопоточности, выделяют три разных аспекта использования кэша, на которые следует обращать внимание. Это:
- Параллельный доступ
- Атомарность
- Пропускная способность
Подобное деление справедливо и для многозадачных сценариев, но так как задачи (процессы) обычно выполняются независимо друг от друга, работу с ними не так легко оптимизировать. А возможные способы их оптимизации представляют собой лишь подмножество способов оптимизации многопотоковых сценариев. Поэтому мы будем рассматривать исключительно последние.
Под параллельным (совместным) доступом в нашем случае понимается организация работы с памятью для процессов, выполняющихся в несколько потоков. Одним из свойств потоков является тот факт, что они все используют одно и то же адресное пространство и потому могут получать доступ к одному и тому же участку памяти. В идеале каждый поток использует свою отдельную область памяти, при этом потоки почти не связаны между собой (разве что общими входами/выходами, к примеру). Если несколько потоков одновременно используют одни и те же данные, то необходимо согласование - тут в дело вступает атомарность. Наконец, доступные процессорам память и пропускная способность межпроцессорной шины ограничены типом используемой архитектуры. Ниже мы разберем все эти три аспекта по отдельности --- хотя они, конечно же, тесно между собой связаны.
6.4.1 Оптимизация параллельного доступа
Итак, начнем. В данном разделе мы обсудим две различные проблемы, требующие по сути принципально противоположных подходов к оптимизации. Пусть многопотоковое приложение использует общие данные для нескольких потоков. Стандартная оптимизация кэша требует нахождения таких данных в одной кэш-строке, чтобы приложение было компактнее - таким образом максимизируя количество памяти, которое кэш сможет вместить в любой момент времени.
Однако с таким подходом возникает следующая проблема: чтобы несколько потоков могли производить запись в память, строки кэшей L1d соответствующих ядер должны иметь статус 'E' (Exclusive). Это означает, что появится множество RFO-запросов, в худшем случае - по запросу на каждую попытку записи. В результате обыкновенная процедура записи внезапно становится очень ресурсоемкой. К тому же, если речь идет об одной и той же области памяти, то тут необходима синхронизация (при этом могут помочь атомарные операции, о них поговорим в следующем разделе). Но проблема остается даже когда все потоки используют разные области памяти и предположительно не зависят друг от друга.

Рисунок 6.10: Задержки при параллельном доступе с использованием общей кэш-строки
Описанная проблема получила название ⌠ложного совместного доступа■. На рисунке 6.10 наглядно показано, чем он опасен. Тестовая программа (см. листинг в разделе 9.3) создает некоторое количество потоков, которые увеличивают значение, хранящееся в памяти, на единицу (500 миллионов раз). Измеряется время, прошедшее с момента запуска программы и до момента ее завершения после того, как последний поток закончит работу. Для теста используется машина с четырьмя процессорами P4, при этом каждый поток закреплен за своим процессором. Синим цветом показаны результаты, когда данные каждого потока обслуживались отдельными кэш-строками. Красный цвет демонстрирует задержки, полученные при использовании одной общей кэш-строки для данных всех потоков.
Результаты, показанные синим цветом (отдельные кэш-строки для каждого потока) в точности совпадают с тем, что обычно ожидается в таких случаях. Программа выполняется в несколько потоков, фактически без потерь. Кэш-строка каждого потока находится в кэше L1d соответствующего процессора и отсутствуют проблемы с пропускной способностью, поскольку нет необходимости считывать большие куски кода или данных (по сути, всё уже кэшировано). А полученное небольшое увеличение во времени объясняется наличием системного шума и, возможно, эффектом упреждающей выборки (ведь потоки используют последовательные кэш-строки).
Задержка в процентном соотношении вычисляется делением времени, потраченного с использованием общей кэш-строки, на время, потраченное с использованием индивидуальных кэш-строк для каждого потока, и составляет 390%, 734% и 1147% соответственно. Настолько большие числа могут поначалу удивить, но если разобраться, как в нашем случае взаимодействуют кэши, всё становится понятно. "Общая" строка выгружается из кэша текущего процессора сразу после окончания записи. И все процессоры, кроме того, в кэше которого на данный момент находится кэш-строка, простаивают и ничего не могут делать. Каждый дополнительный процессор попросту увеличивает время таких простоев.
Естественно, что подобного сценария необходимо избегать при программировании. И хотя в большинстве случаев проблему будет легко определить по огромным задержкам (профилирование как минимум локализует проблему в коде), тут есть свои подводные камни. Один из них - современное аппаратное обеспечение. На рисунке 6.11 показаны те же измерения, только сделанные на машине с одним четырехъядерным процессором (Intel Core 2 QX 6700). Даже с учетом наличия двух раздельных кэшей второго уровня (L2), тест не выявил никаких проблем. При неоднократном использовании одной и той же кэш-строки имеется небольшая задержка, но она не зависит от количества ядер. {Я никак не могу объяснить уменьшение данной задержки при использовании всех четырех ядер, но данный результат легко воспроизводится.} Конечно, при использовании более чем одного такого процессора мы бы получили результаты, схожие с показателями рисунка 6.10. Несмотря на то, что многоядерные процессоры распространяются все шире, многопроцессорные машины пока никуда не денутся, и потому важно корректно обрабатывать вышеприведенный сценарий. А это значит, что придется проверять код на реальных многопроцессорных машинах.

Рисунок 6.11: Задержки при использовании четырехъядерного процессора
Навскидку, простейшее решение проблемы "в лоб": хранить каждую переменную в отдельной строке кэша. И вот здесь проявляется конфликт с первоначально описанным вариантом оптимизации, а именно - ни о какой компактности приложения речи уже не идет, объем занимаемой памяти в кэше сильно увеличится. Это неприемлемо, так что необходимо искать более изящный вариант.
Чтобы его найти, необходимо определить, какие переменные используются только одним потоком в каждый момент времени, какие используются вообще только одним потоком, ну и можно выделить те, к которым нужен совместный доступ лишь временами. Для каждого из этих сценариев возможны самые различные решения. Простейший критерий разделения переменных - ответ на вопрос, происходит ли вообще запись в данную переменную во время работы и если да, то как часто.
Переменные, в которые никогда не происходит запись и которые инициализируются лишь однажды - по сути являются константами. Так как запросы RFO необходимы только для операций записи, то константы можно сделать общими (статус 'S'). Они не требуют какого-то особого обращения, достаточно просто сгруппировать их вместе. Если корректно пометить нужные переменные как const, то toolchain сам отделит их от "нормальных" переменных и поместит в секции .rodata (данные только для чтения) или .data.rel.ro ("только для чтения" после перемещения). {секции, идентифицируемые по именам - это атомарные единицы, содержащие код и данные в файле ELF} Никаких других действий не потребуется. Если же по каким-то причинам переменные невозможно пометить как const, то на их размещение можно повлиять, объявив такие переменные в специальной секции.
При компоновке итогового исполняемого файла сначала собираются вместе секции с одинаковыми именами из всех входных файлов, затем эти секции располагаются в порядке, определяемом скриптом компоновщика. Это означает, что если все переменные, не помеченные как константы, но по сути являющиеся таковыми, объявлять в специальных (одинаково поименованных) секциях, то такие переменные окажутся сгруппированными вместе. Среди них не окажется переменной, в которую часто происходила бы запись. А выровняв первую переменную в такой секции нужным образом, можно гарантировать защищенность от ложного совместного доступа. Рассмотрим следующий небольшой пример:
int foo = 1;
int bar __attribute__((section(".data.ro"))) = 2;
int baz = 3;
int xyzzy __attribute__((section(".data.ro"))) = 4;
Будучи скомпилированным, такой входной файл определяет четыре переменные. Интересный момент заключается в том, что пары переменных foo и baz, bar и xyzzy соответственно будут сгруппированы вместе. Если бы не были определены атрибуты, компилятор расположил бы все четыре переменные в секции .data, причем в том порядке, в каком они определены в исходном коде. {Это не гарантируется ISO-стандартом для языка C, но тем не менее gcc работает именно так.} Наш же код расположит переменные bar и xyzzy в секции .data.ro. Имя секции, .data.ro, выбрано относительно произвольно. "Относительно" - ибо префикс .data. гарантирует, что компоновщик GNU поместит секцию вместе с другими секциями данных.
Этот же прием можно применить, чтобы выделить переменные "в основном для чтения", т.е. часто читаемые, но в которые редко происходит запись. Просто выберите другое имя секции. Но такое разделение имеет смысл лишь в некоторых случаях, например в ядре Linux.
Если переменная используется только внутри потока, можно использовать другой способ объявления. В этом случае можно и нужно использовать локальные переменные потока (см. mytls локально. Языки C и C++ в gcc позволяют определять переменные как принадлежащие потоку, используя ключевое слово __thread.
int foo = 1;
__thread int bar = 2;
int baz = 3;
__thread int xyzzy = 4;
Переменные bar и xyzzy не будут помещены в обычном сегменте данных. Вместо этого, каждый поток имеет свою отдельную область для хранения таких переменных. Хранящиеся подобным образом переменные могут иметь статические инициализаторы. Все локальные переменные потока адресуемы другими потоками, но пока поток-владелец не передаст им указатель на свою переменную, они никак не смогут ее найти. Поскольку переменная является локальной в пределах данного потока, проблема ложного совместного доступа попросту отсутствует --- если, конечно, не создать ее искусственно. Такое решение легко реализовать (всю работу делают компилятор и компоновщик), но и оно имеет свою цену. При создании потока, последнему необходимо инициализировать локальные переменные, а это требует и времени, и памяти. К тому же, адресация локальной переменной потока обычно более ресурсоемка, чем использование глобальных или автоматических переменных (в mytls локально объясняется, как происходит автоматическое снижение ресурсоемкости в случаях, когда это возможно).
Одним из недостатков использования локальной памяти потока (далее TLS = thread-local storage) является тот факт, что если переменная все-таки передается другому потоку, то текущее значение переменной в старом потоке недоступно для нового владельца. У него будет своя копия переменной, не связанная с оригиналом. Обычно это вообще не проблема, но если таки это важно, то передача переменной другому потоку потребует некоторой координации, для копирования текущего значения.
Второй недостаток посерьезней - возможна пустая трата ресурсов. Если переменную использует только один поток в каждый момент времени, все остальные потоки за это расплачиваются памятью. В случае, когда TLS-переменные не используются вообще, проблему решает отложенное ("ленивое") выделение памяти TLS (исключая локальную память в самом приложении). Но при использовании потоком всего одной переменной TLS в разделяемой библиотеке, будет выделена память и для всех остальных TLS-переменных этой библиотеки. При широком использовании переменных TLS это потенциально может вылиться в серьезную проблему.
В целом, можно дать следующие советы:
- Как минимум, разделяйте переменные "только для чтения" (после их инициализации) и "обычные" модифицируемые переменные. Можете также выделить переменные "в основном для чтения" в третью категорию.
- Группируйте модифицируемые переменные, используемые вместе, в структуру. Использование структуры - единственный способ гарантировать при использовании любой версии gcc, что области памяти для этих переменных находятся рядом друг с другом.
- Модифицируемые переменные, в которые часто происходит запись разными потоками, помещайте в отдельную кэш-строку. Место, которое останется в строке, можно заполнить незначащей информацией. В сочетании с шагом 2 это может оказаться отнюдь не столь расточительно, как кажется. Дополнив вышеприведенный пример и полагая, что
barиxyzzyдолжны использоваться вместе, получим следующий код:
int foo = 1;
int baz = 3;
struct {
struct al1 {
int bar;
int xyzzy;
};
char pad[CLSIZE - sizeof(struct al1)];
} rwstruct __attribute__((aligned(CLSIZE))) =
{ { .bar = 2, .xyzzy = 4 } };
Понадобятся небольшие исправления в коде (ссылки на `bar` поменять на `rwstruct.bar`, с `xyzzy` аналогично), но не более того. Компилятор с компоновщиком доделают остальное. {В командной строке этот код необходимо компилировать с `-fms-extensions`.}
- Если переменная используется множеством потоков, но каждый из потоков использует ее независимо от других, помещайте такую переменную в TLS.
6.4.2 Оптимизация работы с атомарными операциями
В ситуации, когда несколько потоков параллельно работают с одной и той же областью памяти, процессоры сами не предпринимают никаких действий и, соответственно, не гарантируют никаких определенных результатов. Это обдуманное и взвешенное решение, принятое с целью избежания затрат, лишних в 99,999% всех случаев. Например, пусть область памяти имеет статус 'S' и два потока параллельно пытаются увеличить значение, хранящееся в этой области, на единицу. Исполнительный конвейер не станет ждать, пока кэш-строка получит статус 'E', прежде чем считать старое значение. Вместо этого он сразу считывает текущее значение из кэша и, как только кэш-строка получает статус 'E', записывает новое значение обратно. Но результат может обмануть ожидания, если операции чтения кэша произойдут в двух потоках одновременно - тогда одно из увеличений будет потеряно.
Для предотвращения таких ситуаций в процессорах предусмотрены так называемые атомарные (неделимые) операции. Эти операции, например, никогда не станут считывать старое значение до тех пор, пока не станет ясно, что увеличение возможно осуществить как атомарное. Помимо ожидания остальных ядер и процессоров, некоторые процессоры даже предупреждают другие устройства материнской платы о таких операциях. Всё это замедляет работу с ними.
Наборы доступных атомарных операций различаются у разных производителей процессоров. Ранние процессоры RISC - где 'R' означает reduced, "сокращенный" (о наборе команд) - имели очень мало таких команд, иногда вообще лишь атомарные битовые set и test. {HP Parisc до сих пор только их и поддерживает...}. А на другом конце спектра у нас архитектуры x86 и x86-64 со множеством атомарных инструкций. Основные из них можно разделить на четыре класса:
Bit Test
Эти операции атомарно устанавливают либо сбрасывают бит и возвращают его предыдущее состояние.
Load Lock/Store Conditional (LL/SC) {Иногда предпочитают использовать ⌠linked вместо ⌠lock, это не суть важно.}
Тут у нас сразу пара операций: специальная инструкция загрузки (считывания) используется для начала транзакции, а инструкция сохранения (записи) завершает ее, причем успешное завершение возможно только если во время выполнения не произошло никаких изменений в целевой области. Программа может повторять попытки при необходимости, в зависимости от результата операции сохранения.
Compare-and-Swap (CAS)
Троичная (тернарная) операция "Сравнение и замена" записывает значение (переданное как первый параметр) по адресу (второй параметр), только если текущее значение, хранящееся по этому адресу, равно третьему параметру.
Атомарные арифметические операции
Доступны исключительно на архитектурах x86 и x86-64, которые могут осуществлять арифметические и логические операции над памятью. Эти процессоры поддерживают также и неатомарные версии данных операций, чем не могут похвастаться архитектуры RISC. Поэтому неудивительно, что они так мало распространены.
Любая архитектура может поддерживать либо LL/SC, либо CAS - третьего не дано. Оба подхода по сути эквивалентны, и в равной степени одинаково позволяют реализовывать атомарные арифметические операции. Однако в наши дни чаще предпочитают CAS. Используя эту инструкцию, можно косвенно реализовать все остальные операции. Например, атомарное сложение:
int curval;
int newval;
do {
curval = var;
newval = curval + addend;
} while (CAS(&var, curval, newval));
Значение, возвращенное CAS, показывает, успешно завершилась операция или нет. Если нет (возвращено ненулевое значение), цикл запускается по новой, выполняется сложение и снова проверяется результат вызова CAS. И так до успешного финала. Стоит отметить, что адрес области памяти необходимо вычислять с помощью двух отдельных инструкций. {Операционный код CAS на x86 и x86-64 может пропустить загрузку значения во второй и последующих итерациях, но на той платформе мы вообще сможем всю операцию атомарного сложения записать проще, с использованием лишь одной инструкции.} В случае использования LL/SC код почти не отличается:
int curval;
int newval;
do {
curval = LL(var);
newval = curval + addend;
} while (SC(var, newval));
Здесь мы используем специальную инструкцию загрузки (LL), и при этом нам не нужно передавать в SC текущее значение в памяти, поскольку процессор сам следит, изменялось ли оно во время выполнения программы.
Ситуация сильно меняется в случае x86 и x86-64, поскольку расширяется количество доступных атомарных инструкций, и для получения наилучших результатов очень важно выбрать подходящую. На рисунке 6.12 показаны три различных способа реализации атомарной операции инкремента.
for (i = 0; i < N; ++i)
__sync_add_and_fetch(&var,1);
1. Произвести сложение и вернуть результат ("сложение с обменом")
for (i = 0; i < N; ++i)
__sync_fetch_and_add(&var,1);
2. Произвести сложение и вернуть старое значение ("сложение со считыванием")
for (i = 0; i < N; ++i) {
long v, n;
do {
v = var;
n = v + 1;
} while (!__sync_bool_compare_and_swap(&var, v, n));
}
3. Атомарная замена новым значением (с использованием CAS)
Рисунок 6.12: Циклический атомарный инкремент
На x86 и x86-64 после интерпретации во всех трех случаях получится разный код, в то время как на других архитектурах он будет идентичен. В скорости выполнения разница огромна. Следующая таблица демонстрирует, сколько времени заняло выполнение одного миллиона инкрементов четырьмя параллельными потоками. В коде использовались встроенные примитивы gcc (__sync_*).
| 1. Сложение с обменом | 2. Сложение со считыванием | 3. CAS |
|---|---|---|
| 0.23s | 0.21s | 0.73s |
Сравнив первые два числа, видим, что они близки: сложение со считыванием старого значения лишь чуть-чуть быстрее. Но важно здесь то, что мы видим в третьем, выделенном поле - время, затраченное на выполнение с использованием CAS. Оно гораздо больше. Тому есть несколько причин: 1. В коде присутствуют две отдельные операции по работе с памятью; 2. Сама по себе операция CAS более сложна и даже содержит условный переход; 3. Вся операция сложения находится во вложенном цикле на случай, если произойдут две параллельные попытки доступа и CAS вернет ошибку.
Читатель может спросить: "А зачем вообще использовать CAS, если код получается сложнее и длиннее?". Ответ - вся сложность обычно спрятана. Выше упоминалось, что CAS сейчас присутствует во всех интересных архитектурах, по сути служит инструментом унификации. И поэтому люди считают разумным реализовывать все атомарные операции именно через CAS. Это упрощает программы. Но как показывают цифры, это далеко не оптимально с точки зрения производительности. Решения, построенные на CAS, крайне неэффективно обращаются с памятью. Далее показаны алгоритмы выполнения всего лишь двух потоков, каждого на своем отдельном процессоре ("П"):
| Поток #1 | Поток #2 | Статус кэша var |
|---|---|---|
| v = var | ‘E’ на П1 | |
| n = v + 1 | v = var | ‘S’ на П1+2 |
| CAS( var ) | n = v + 1 | ‘E’ на П1 |
| CAS( var ) | ‘E’ на П2 |
Видим, что даже за такой небольшой период статус строки кэша меняется минимум три раза, два из которых - в результате запросов RFO. К тому же, CAS во втором потоке выдаст ошибку, и потоку придется повторить операцию с начала. А пока она будет выполняться, снова может произойти та же ситуация.
Напротив, если использовать атомарные арифметические операции, то считывание и запись данных в память, необходимые для выполнения сложения (или другого действия) будут выполняться процессором последовательно. Гарантируется, что параллельные запросы к строке кэша будут блокированы до окончания выполнения атомарной операции. И тогда каждая итерация цикла в примере приведет максимум к одному запросу RFO, не более того.
Всё это значит, что крайне важно работать на таком уровне абстракции, на котором можно использовать преимущества атомарных арифметических и логических операций. Не стоит повсюду использовать CAS в качестве механизма унификации.
Для большинства процессоров атомарные операции сами по себе всегда атомарны, неделимы. В случае, когда в атомарности нет необходимости, для ее избежания программисту придется изворачиваться, искать "окольные пути". Соответственно, это значит - больше кода, условные и безусловные переходы к прямому выполнению.
С x86 и x86-64 ситуация иная. Одни и те же инструкции можно использовать и как атомарные, и как "обычные". Чтобы сделать их атомарными, используется специальный префикс: lock. Такой подход позволяет не использовать атомарность, когда в ней нет необходимости - и таким образом избежать связанных с ней затрат. Это очень полезно при, например, написании кода общего пользования в библиотеке, ведь такой код всегда должен обеспечивать потоковую безопасность. Причем во время написания кода можно еще не знать, потребуется это или нет, а выбор будет делаться уже при работе программы. Трюк заключается в том, чтобы перепрыгнуть префикс lock, когда нужно, и прием этот реализуем для всех инструкций, с которыми процессоры x86 и x86-64 позволяют использовать данный префикс.
cmpl $0, multiple_threads
je 1f
lock
1: add $1, some_var
Если этот ассемблерный код кажется непонятным, не волнуйтесь. Все просто. Первая инструкция проверяет, равна ли переменная нулю. В данном случае ненулевое значение будет означать, что запущено более одного потока. При нулевом значении вторая инструкция осуществляет переход к метке 1. Иначе просто выполняется следующая инструкция. Вот и весь трюк. Если перехода не было, инструкция add выполняется с префиксом lock. Иначе - без него.
Добавление относительно дорогой (в смысле ресурсов) операции вроде условного перехода (дорогим он становится в случае, когда предсказание переходов дает сбой) может показаться непродуктивным шагом. И несомненно, иногда это так: если большую часть времени идет работа в несколько потоков, то производительность действительно упадет, особенно в случае частых ошибок механизма предсказания переходов. Но если ситуация противоположна и чаще всего выполняется только один поток, такой код будет выполняться значительно быстрее. Альтернативой конструкции if-then-else в обоих случаях может послужить дополнительный безусловный переход. Учитывая, что затраты ресурсов на атомарную операцию соизмеримы с затратами на 200 циклов, можно сказать, что использование такого трюка (или блока if-then-else) часто оправдывает себя, и этот прием стоит иметь в виду. К сожалению, его использование означает невозможность применения примитивов __sync_*, предоставляемых gcc.
6.4.3 Решаем проблемы с пропускной способностью
Использование множества потоков, корректно работающих с кэшем (т.е. исключающих попытки доступа к одной и той же кэш-строке разными ядрами, приводящие к конфликту), не гарантирует отсутствия других проблем. Полоса пропускания канала между процессором и памятью имеет ограниченную ширину, которая к тому же делится между всеми ядрами и гиперпотоками данного процессора. А в зависимости от архитектуры (пример - рисунок 2.1), несколько процессоров также могут иметь общую шину памяти или северного моста.
Ядра современных процессоров работают на таких частотах, что даже работая на максимальной скорости и в идеальных условиях, соединение с памятью не позволяет обслуживать без задержек все запросы считывания и записи. А теперь вдобавок к этому разделите всю полосу пропускания на количество ядер, гиперпотоков и процессоров с общим доступом к северному мосту, и станет ясно, почему многопоточность внезапно может привести к серьезным проблемам. Производительность программ, в теории очень эффективных, на практике может быть ограничена пропускной способностью памяти.
На рисунке 3.32 мы видели, что повышение скорости шины процессора очень помогает в таких случаях. Поэтому с ростом количества ядер в процессорах наблюдается и увеличение скорости системной шины. Однако этого часто недостаточно, особенно если программа использует большие рабочие множества и недостаточно оптимизирована. Поэтому программист должен быть всегда готов распознать проблемы, связанные с пропускной способностью.
Счетчики производительности современных процессоров позволяют следить за загрузкой системной шины. Например, событие NUS_BNR_DRV процессоров Core 2 подсчитывает количество холостых тактов ядра, произошедших по причине неготовности шины. Это показывает, что шина перегружена и операции считывания/записи в основную память выполняются медленнее обычного. Процессорами Core 2 поддерживаются и другие события, позволяющие подсчитывать различные показатели, например запросы RFO или общую загрузку шины. Последнее, например, будет кстати, если при разработке приложения потребуется исследовать возможность его масштабируемости. Ясно, что когда уровень загрузки шины уже близок к единице, возможности масштабирования минимальны.
Допустим, диагноз ясен - проблема с пропускной способностью. Для ее решения существует несколько способов. Иногда они взаимоисключают друг друга, так что, быть может, придется поэкспериментировать. Ну, например, одно из решений - купить более быстрый компьютер, если такой существует. Поскольку это означает рост скорости системной шины и модулей памяти, а также возможное увеличение объема локальной памяти процессора, то такой способ может помочь - да и действительно, чаще всего помогает. Однако, подобное может влететь в копеечку. Конечно, если проблемная программа будет использоваться лишь на одной машине (или на небольшом их количестве), то разовая трата на оборудование может оказаться меньше, чем затраты на переработку программы. Но в абсолютном большинстве случаев лучше таки переделать программу.
Оптимизировав программу во избежание промахов кэша, остается лишь одна возможность уменьшить загрузку полосы пропускания - правильно распределить потоки по доступным ядрам. По умолчанию, планировщик в ядре распределяет потоки в соответствии со своей политикой. Перемещение потока между ядрами по возможности избегается. Тем не менее, планировщик ведь ничего не знает о рабочей нагрузке. Да, он может собирать информацию о промахах кэша и прочем, но в большинстве случаев это малоэффективно.

Рисунок 6.13: Нерациональное планирование
Один из вариантов, приводящих к большой загрузке шины - когда два потока выполняются на разных процессорах (или ядрах с разделенным кэшем), но используют при этом один и тот же набор данных. Такая ситуация показана на рисунке 6.13. Ядра 1 и 3 используют одни и те же данные (указатели доступа и области памяти показаны одним цветом). Аналогично для ядер 2 и 4. Но потоки распределены по разным процессорам. То есть каждый набор данных необходимо будет считать из памяти дважды. Эту ситуацию можно исправить.

Рисунок 6.14: Рациональное планирование
На рисунке 6.14 показано, как оно должно выглядеть в идеале. Общий размер используемого кэша уменьшен, так как пары ядер 1 + 2 и ядер 3 + 4 работают каждая со своим набором данных. Соответственно, наборы данных придется считать из памяти всего по разу.
Простой пример, конечно, но данный принцип действительно применим во многих ситуациях. Как упоминалось выше, планировщик в ядре не вникает в суть использования данных, поэтому на плечи программиста ложится задача - гарантировать эффективность планирования. Есть не так уж много интерфейсов ядра, с помощью которых можно выполнить это требование. Фактически, способ только один: использовать привязку потоков.
Под привязкой потоков понимается назначение потока одному или нескольким ядрам. И тогда, если планировщику будет необходимо решить, где запускать поток, он будет выбирать только из этих заданных ядер. Даже если другие ядра свободны, они не будут рассматриваться вообще. Это может показаться недостатком, но ведь всему есть своя цена. Если слишком много потоков привязано к конкретному набору ядер, то другие ядра будут частенько простаивать, и исправить такую ситуацию можно только поменяв привязку. По умолчанию привязка отсутствует, то есть потоки могут выполняться на любом ядре.
Интерфейсы, использующиеся для запросов о привязке и ее изменений, описаны ниже.
#define _GNU_SOURCE
#include <sched.h>
int sched_setaffinity(pid_t pid, size_t size, const cpu_set_t *cpuset);
int sched_getaffinity(pid_t pid, size_t size, cpu_set_t *cpuset);
Эти два интерфейса используются в однопоточном коде. Аргумент pid определяет, привязку какого процесса следует установить или изменить. Естественно, для вызова необходимы соответствующие привилегии. Второй и третий параметры определяют битовую маску для ядер. Первая функция требует заполненную битовую маску для того, чтобы установить привязку. Вторая - заполняет битовую маску информацией о распределении (привязке) выбранного потока. Оба интерфейса объявлены в заголовочном файле <sched.h>.
В том же файле объявлен тип cpu_set_t, а с ним и соответствующие макросы для управления и использования объектов данного типа.
#define _GNU_SOURCE
#include <sched.h>
#define CPU_SETSIZE
#define CPU_SET(cpu, cpusetp)
#define CPU_CLR(cpu, cpusetp)
#define CPU_ZERO(cpusetp)
#define CPU_ISSET(cpu, cpusetp)
#define CPU_COUNT(cpusetp)
Константа CPU_SETSIZE определяет максимальное количество процессоров, которое может быть представлено в структуре данных. Следующая тройка макросов используется для управления объектами cpu_set_t. CPU_ZERO инициализирует объект, а оставшаяся пара используется соответственно для включения во множество и исключения из него отдельных ядер либо процессоров. CPU_ISSET проверяет, входит ли процессор во множество, а CPU_COUNT возвращает текущее их количество во множестве. Максимальное число процессоров в cpu_set_t, установленное по умолчанию, вполне достаточно для работы. Но со временем, несомненно, этого станет мало, и придется вносить правки. В процессе написания программы всегда необходимо помнить об этом ограничении. Вышеприведенные макросы удобны, но, в соответствии с описанием cpu_set_t, управляют размером множества лишь косвенно. Для более динамичного управления следует использовать расширенный набор макросов:
#define _GNU_SOURCE
#include <sched.h>
#define CPU_SET_S(cpu, setsize, cpusetp)
#define CPU_CLR_S(cpu, setsize, cpusetp)
#define CPU_ZERO_S(setsize, cpusetp)
#define CPU_ISSET_S(cpu, setsize, cpusetp)
#define CPU_COUNT_S(setsize, cpusetp)
Эти интерфейсы принимают размер множества (массива) в виде дополнительного параметра. Для работы с динамическими массивами процессоров используется следующая тройка макросов:
#define _GNU_SOURCE
#include <sched.h>
#define CPU_ALLOC_SIZE(count)
#define CPU_ALLOC(count)
#define CPU_FREE(cpuset)
CPU_ALLOC_SIZE возвращает число байтов, которое необходимо выделить структуре cpu_set_t, могущей обработать количество процессоров, указанное в count. Для собственно выделения такого блока используется CPU_ALLOC. Память, выделенная подобным образом, освобождается через CPU_FREE. Скорее всего, внутри этих функций используются malloc и free, но это далеко не обязательно.
Над множествами процессоров определены также следующие операции:
#define _GNU_SOURCE
#include <sched.h>
#define CPU_EQUAL(cpuset1, cpuset2)
#define CPU_AND(destset, cpuset1, cpuset2)
#define CPU_OR(destset, cpuset1, cpuset2)
#define CPU_XOR(destset, cpuset1, cpuset2)
#define CPU_EQUAL_S(setsize, cpuset1, cpuset2)
#define CPU_AND_S(setsize, destset, cpuset1, cpuset2)
#define CPU_OR_S(setsize, destset, cpuset1, cpuset2)
#define CPU_XOR_S(setsize, destset, cpuset1, cpuset2)
Имеем две группы по четыре макроса. Они могут сравнивать пары множеств, а также производить логические операции И, ИЛИ, исключающее ИЛИ (XOR). Это пригодится при использовании некоторых функций libNUMA (см. раздел 12).
Процесс может определить, на каком процессоре он в данный момент выполняется, используя интерфейс sched_getcpu:
#define _GNU_SOURCE
#include <sched.h>
int sched_getcpu(void);
Как результат возвращается номер процессора в массиве. В связи с самой природой планирования, этот номер не всегда 100% верен. Есть вероятность, что поток был перемещен на другой процессор между моментом возвращения результата и моментом возвращения потока на уровень пользователя. Программы всегда должны принимать эту вероятность во внимание. В любом случае, гораздо важнее само множество процессоров, на которых потоку разрешено выполняться. Его можно получить, используя sched_getaffinity. Множество привязки наследуется дочерними потоками и процессами. Но неизменность данного множества во время жизненного цикла потока ничем не гарантируется. Маска привязки может быть установлена извне (см. параметр pid в прототипах выше); к тому же Linux поддерживает горячую замену процессоров, а это значит, что процессор может исчезнуть из системы --- и, таким образом, из множества привязки.
В соответствии с требованиями POSIX, в многопоточных программах отдельные потоки официально не имеют своего отдельного PID, и поэтому вышеуказанные две функции использовать не получится. Вместо них в <pthread.h> объявлено четыре других интерфейса:
#define _GNU_SOURCE
#include <pthread.h>
int pthread_setaffinity_np(pthread_t th, size_t size,
const cpu_set_t *cpuset);
int pthread_getaffinity_np(pthread_t th, size_t size, cpu_set_t *cpuset);
int pthread_attr_setaffinity_np(pthread_attr_t *at,
size_t size, const cpu_set_t *cpuset);
int pthread_attr_getaffinity_np(pthread_attr_t *at, size_t size,
cpu_set_t *cpuset);
Первые два интерфейса - по сути те же две функции, с которыми мы уже знакомы, за исключением того, что они принимают дескриптор (HANDLE) потока вместо идентификатора процесса (PID). Это позволяет адресовать отдельные потоки в процессе, а также означает, что данные интерфейсы никак не могут быть использованы из другого процесса, они предназначены строго для внутрипроцессного использования. Далее, третий и четвертый интерфейсы принимают атрибут потока. Атрибуты используются при создании нового потока. Устанавливая атрибут, мы можем прямо при запуске потока определить его множество привязки. Выбор целевых процессоров на таком раннем этапе во многом выгоднее выбора уже в процессе работы потока, и особенно это преимущество заметно при выделении памяти (см. NUMA в разделе 6.5).
Кстати, в программировании NUMA интерфейсы привязки также играют большую роль. Скоро мы к этому вернемся.
Пока что мы говорили только о той ситуации, когда рабочие множества двух потоков совпадают, и поэтому имеет смысл выполнение обоих потоков на одном ядре. Но бывают и противоположные случаи. Если два потока работают с совсем разными наборами данных, то их выполнение на одном ядре наоборот может стать проблемой. Во-первых, оба потока будут сражаться за один кэш, мешая друг другу эффективно его использовать. Во-вторых, оба набора данных должны находиться в одном и том же кэше, что фактически означает увеличение количества данных для загрузки, и в итоге доступная пропускная способность урезается вдвое.
Решение - привязать потоки таким образом, чтоы они не могли выполняться вместе на одном ядре. Это противоположность случаю, описанному прежде. И поэтому прежде чем что-то менять, необходимо полностью разобраться в ситуации, которую взялся оптимизировать.
Оптимизация работы с кэшем ради увеличения пропускной способности на деле является аспектом программирования NUMA, о нем пойдет речь в следующем разделе. Чтобы убедиться в справедливости этого утверждения, необходимо свои представления о таком понятии, как ⌠память■ в NUMA, распространить на кэш. И чем больше уровней имеет кэш-память, тем актуальнее становится такой подход. И именно в связи с этим решения по многопроцессорному планированию можно найти во вспомогательных библиотеках NUMA; взятые оттуда примеры по определению масок привязки без применения хардкодинга или углубления в файловую систему /sys находятся в разделе 12.
6.5 Программирование NUMA
Итак, все, что было сказано об оптимизации работы с кэшем, применимо и к программированию NUMA. Но дальше начинаются отличия. В дело вступает такой факт, как разные затраты при доступе к разным областям адресного пространства. С однородным доступом к памяти мы можем оптимизацией добиться уменьшения ошибок отсутствия страниц (см. раздел 7.5), и на этом все. Все создаваемые страницы памяти одинаковы.
Совсем иначе с NUMA. Затраты на доступ зависят от адресуемой страницы, и это еще больше увеличивает важность оптимизации расположения страниц памяти. Использования архитектуры неоднородного доступа к памяти (именно так расшифровывается NUMA) не избежать на большинстве многопроцессорных машин, поскольку и Intel с CSI (на x86, x86-64 и IA-64), и AMD (на Opteron) используют именно ее. Правда, с увеличением числа ядер на отдельно взятом процессоре количество используемых многопроцессорных машин резко уменьшится (исключение составят дата-центры и ведомства с крайне высокими требованиями к ЦПУ). Для абсолютного большинства домашних машин будет достаточно одного процессора и, соответственно, не будет проблем, связанных с NUMA. Но это: а) не означает, что программисты могут игнорировать архитектуру NUMA и б) не означает исчезновения характерных для этой архитектуры проблем.
Ведь если задуматься, что общего NUMA имеет с другими архитектурами, можно легко увидеть, что это в точности концепция процессорной кэш-памяти. Два потока на ядрах с общим кэшем будут выполнены быстрее, чем потоки на ядрах с кэшем раздельным. За примерами далеко ходить не надо:
- ранние двухъядерные процессоры не имели общего кэша L2.
- процессоры Core 2 QX 6700 и QX 6800 от Intel, к примеру, имеют четыре ядра и два раздельных кэша L2.
- как недавно упоминалось, рост числа ядер на одном чипе и стремление к объединению кэшей в итоге приводят к увеличению количества уровней кэша.
Кэши формируют свою собственную иерархическую структуру, что повышает важность зависимости между разделением (или наоборот) кэшей и распределением потоков по ядрам. Такое положение дел фактически не отличается от проблем, стоящих перед NUMА, и в этом данные концепции едины. Вот почему даже тем людям, кто заинтересован исключительно в однопроцессорных машинах, следует прочесть данный раздел.
В разделе 5.3 мы увидели, что ядро Linux может дать нам много полезной - и нужной - информации для программирования NUMA. Однако, собрать эту информацию не так уж легко. Текущая версия Linux-библиотеки NUMA абсолютно непригодна для такой цели. На данный момент автор работает над новой, гораздо более удобной версией.
Существующая библиотека NUMA, libnuma, являющаяся частью пакета numactl, не дает доступа к информации об архитектуре системы. Все, что она делает - собирает в одной упаковке доступные системные вызовы и предоставляет удобные интерфейсы для часто применяемых операций. Итак, на сегодняшний день в Linux доступны следующие системные вызовы:
mbind
Выборочная привязка указанных страниц памяти к узлам.
set_mempolicy
Установить политику выделения памяти по умолчанию.
get_mempolicy
Запросить информацию о политике выделения памяти по умолчанию.
migrate_pages
Переместить все страницы процесса с данного множества узлов на другое множество.
move_pages
Переместить выбранные страницы на указанный узел либо запросить адреса текущих узлов (т.е. на которых на данный момент находятся выбранные страницы).
Эти интерфейсы объявлены в заголовочном файле <numaif.h>, поставляемом с библиотекой libnuma. Но прежде чем углубиться в детали, необходимо понять саму концепцию политик выделения памяти.
6.5.1 Политика выделения памяти
Основная идея, лежащая в основе определения политик памяти - позволить уже написанному коду достаточно успешно функционировать в среде NUMA без серьезных модификаций. Политика наследуется дочерними процессами, поэтому возможно использование numactl. Помимо прочих возможностей, данный инструмент позволяет запустить программу с определенной политикой.
Ядром Linux поддерживаются следующие политики:
MPOL_BIND
Память выделяется только из указанного множества узлов. Если это невозможно, память не выделяется.
MPOL_PREFERRED
Память выделяется предпочтительно из указанного множества узлов. Если это невозможно, используется память других узлов.
MPOL_INTERLEAVE
Память выделяется в равной степени поочередно из определенных узлов. Узлы определяются либо смещением в области виртуальной памяти (для политик VMA), либо независимым счетчиком в случае политик задач.
MPOL_DEFAULT
Использовать способ выделения, применяемый по умолчанию для данной области.
Может показаться, что политики в этом списке определяются рекурсивно. Это верно только наполовину. На деле, политики выделения памяти образуют иерархическую структуру (см. рисунок 6.15).

Рисунок 6.15: Иерархическая структура политик выделения памяти
Если адрес принадлежит виртуальной памяти, то применяется соответствующая политика VMA. Для сегментов памяти общего доступа также применяется своя особая политика. Когда такие "специальные" политики для данного адреса отсутствуют, используется политика задач. Ну а если и последняя не назначена, то остается системная политика по умолчанию.
В качестве системной политики по умолчанию используется выделение памяти, локальной по отношению к запрашивающему потоку, и не определено никаких политик задач и виртуальной памяти. Для многопоточного процесса локальным узлом считается его ⌠домашний■ узел - тот, на котором был запущен процесс первоначально. Вышеперечисленные системные вызовы могут быть использованы для выбора нужных политик, что мы далее и рассмотрим.
6.5.2 Установка политик
Вызов set_mempolicy можно использовать, чтобы установить политику задач для текущего потока (поток, с точки зрения ядра, является задачей), причем устанавливается она только и исключительно для него, а не для всего процесса.
#include <numaif.h>
long set_mempolicy(int mode,
unsigned long *nodemask,
unsigned long maxnode);
Параметр mode может принимать одно из значений констант, представленных в предыдущем разделе. nodemask определяет необходимые узлы памяти, а maxnode - число этих узлов (т.е. битов) в nodemask. При использовании MPOL_DEFAULT параметр nodemask игнорируется. Если при использовании MPOL_PREFERRED в качестве nodemask передается пустой указатель, то выбирается локальный узел. Иначе MPOL_PREFERRED использует наименьший номер узла в соответствующем битовом множестве nodemask.
Установка политики никак не влияет на уже выделенную память, и страницы автоматически никуда не перемещаются. Политика повлиет только на последующие выделения памяти. Обратите внимание на различия между выделением памяти и резервированием адресного пространства: область адресного пространства, установленная с использованием mmap, обычно автоматически не выделяется. При первой операции чтения или записи произойдет выделение соответствующей страницы. Поэтому если политика изменится в какой-то момент между попытками доступа к разным страницам одной и той же области адресного пространства, или если политика позволяет выделение памяти из разных узлов, то однородное на вид адресное пространство может оказаться разбросанным по разным узлам памяти.
6.5.3 Свопинг и политики выделения памяти
Когда заканчивается физическая память, системе приходится выгружать чистые страницы и загружать в файл подкачки грязные (измененные). При загрузке страниц информация об узлах памяти стирается, это особенность реализации свопинга в Linux. Это означает, что когда страница снова задействуется, узел для нее будет выбран с нуля. Скорее всего, будет выбран узел, ближайший к соответствующему процессору, и наверняка это будет уже не тот узел, который использовался первоначально.
Такая смена привязки означает, что информацию о привязке к узлу нельзя хранить в свойствах страницы, ибо привязка со временем поменяется. Для страниц совместного доступа это также справедливо, поскольку будут происходить запросы от процессов (см. описание mbind ниже). Да и само ядро может переместить страницы, если на узле заканчивается память, а на соседних узлах есть свободное место.
Из вышесказанного следует, что любая информация о привязке узлов, полученная на пользовательском уровне, может оставаться верной лишь в течение короткого промежутка времени. Такая информация - скорее подсказка, чем абсолютная истина. Когда нужны достоверные данные, следует использовать интерфейс get_mempolicy (см. раздел 6.5.5)
6.5.4 Политика VMA
Чтобы установить политику VMA для определенного диапазона адресов, нужно использовать следующий интерфейс:
#include <numaif.h>
long mbind(void *start, unsigned long len,
int mode,
unsigned long *nodemask,
unsigned long maxnode,
unsigned flags);
В результате регистрируется новая политика VMA для диапазона [start, start + len). Поскольку память оперирует страницами, начальный адрес должен быть выровнен по границе страницы, а значение len округлено до размера следующей страницы.
Уже знакомый нам параметр mode так же определяет политику, значение нужно выбрать из списка в разделе 6.5.1. Аналогично с set_mempolicy, параметр nodemask используется не всеми политиками. Тут ничего не изменилось.
Семантика интерфейса mbind определяется значением параметра flags. По умолчанию, если flags равен нулю, данный системный вызов просто устанавливает политику VMA для указанного диапазона адресов. Уже существующие привязки и соответствия не затрагиваются. Если этого не достаточно, можно использовать один из трех доступных на сегодня флагов для изменения поведения. Флаги могут использоваться как по отдельности, так и вместе:
MPOL_MF_STRICT
Вызов mbind завершится неудачей в случае если не все страницы находятся на узлах, определенных через nodemask. При использовании данного флага совместно с MPOL_MF_MOVE и/или с MPOL_MF_MOVEALL вызов завершится неудачей, если хоть одна страница не может быть перемещена.
MPOL_MF_MOVE
Ядро попытается переместить любую страницу адресного пространства, находящуюся на узле, не указанном в nodemask. По умолчанию перемещаются только страницы, используемые таблицами страниц исключительно текущего процесса.
MPOL_MF_MOVEALL
Данный флаг похож на MPOL_MF_MOVE, но в отличие от последнего, ядро попытается переместить все страницы, а не только используемые исключительно текущим процессом. Это приводит к последствиям для всей системы, поскольку влияет на доступ других процессов (которые могут иметь разных владельцев) к данным страницам. Поэтому для выполнения операции необходимы соответствующие привилегии (в частности, CAP_NICE).
Обратите внимание, что поддержка MPOL_MF_MOVE и MPOL_MF_MOVEALL была добавлена только в ядре Linux 2.6.16.
Вызов mbind без флагов наиболее полезен, когда нужно определить политику для только что зарезервированного адресного диапазона, прежде чем будут выделены какие-либо страницы.
void *p = mmap(NULL, len, PROT_READ|PROT_WRITE, MAP_ANON, -1, 0);
if (p != MAP_FAILED)
mbind(p, len, mode, nodemask, maxnode, 0);
Данный код резервирует диапазон адресного пространства в len байт и устанавливает политику mode в отношении узлов памяти nodemask. Если в mmap не использовался флаг MAP_POPULATE, то к моменту вызова mbind не было выделено никакой памяти и поэтому новая политика без проблем будет применена ко всем страницам в указанной области адресного пространства.
Флаг MPOL_MF_STRICT может быть использован для определения, присутствуют ли в адресном диапазоне страницы, находящиеся на узлах, не указанных в nodemask. Никаких изменений не производится. Если все страницы "на своих местах" - то есть находятся на указанных узлах, политика VMA для области адресного пространства успешно меняется на mode.
В случае, если требуется ребалансировка памяти, может появиться необходимость в перемещении страниц с одного узла на другой. Для этого вызывается mbind с флагом MPOL_MF_MOVE, причем перемещению могут быть подвергнуты только страницы, используемые исключительно текущим процессом. Если теми же данными пользуются другие потоки или процессы, то такие страницы переместить с помощью даннного флага невозможно.
Пусть функции mbind переданы сразу два флага, MPOL_MF_STRICT и MPOL_MF_MOVE. Тогда ядро попытается переместить все страницы, находящиеся "не на тех" узлах. В случае невозможности такой операции вызов закончится неудачей. Такой способ можно применять для поиска узла (или множества узлов), способного вместить все страницы. Прежде чем подходящий узел будет найдет, понадобится сделать несколько вызовов подряд.
Использование MPOL_MF_MOVEALL оправдано только если выполнение текущего процесса - основное предназначение компьютера. Причина тому - при использовании данного флага перемещаются даже те страницы, которые хранятся сразу в нескольких таблицах страниц, и такое поведение негативно отразится на других процессах. Так что данный флаг следует применять с осторожностью.
6.5.5 Запросы информации об узлах
Интерфейс get_mempolicy можно использовать для запросов различной информации об указанном адресе.
#include <numaif.h>
long get_mempolicy(int *policy,
const unsigned long *nmask,
unsigned long maxnode,
void *addr, int flags);
Когда get_mempolicy вызывается без установленных флагов в параметре flags, информация об используемой политике для адреса addr сохраняется в слове, на которое указывает policy и в битовой маске узлов, на которую указывает nmask. Если addr попадает в область адресного пространства, для которой установлена политика VMA, то возвращается информация о данной политике. Иначе возвращается информация о политике задач либо - при необходимости - о системной политике по умолчанию.
Если установлен флаг MPOL_F_NODE и addr обслуживается политикой MPOL_INTERLEAVE, то в слово, на которое указывает policy, записывается номер узла, на котором произойдет следующее выделение памяти. Эта информация впоследствии может быть использована для привязки потока, который будет выполняться на "свежевыделенной" памяти, что позволит минимизировать расходы на достижение "соседства", особенно если поток еще только предстоит создать.
Флаг MPOL_F_ADDR применяется для получения еще одного типа информации. При его установке, в слово, на которое указывает policy, записывается номер узла, на котором была выделена память для страницы, содержащей addr. Эту информацию можно использовать для принятия решений о возможном перемещении страниц; для выбора потока, который сможет работать с данной областью наиболее эффективно, и для многих других целей.
Процессор (а с ним и узел памяти), на котором выполняется поток, меняется гораздо чаще, чем выделенная для потока память. Перемещение страниц памяти происходит только в крайних случаях или в случае явных запросов на данное действие. Поток может быть назначен другому процессору в результате ребалансировки загрузок ЦПУ. В связи с этим, информация о текущем процессоре и узле быстро утрачивает актуальность. Но тем не менее, планировщик будет стараться держать поток на одном и том же процессоре, может даже на одном и том же ядре, для минимизации потерь производительности, связанных с понятием "холодного кэша". Следовательно, следить за информацией о текущем процессоре и узле может быть полезно, но все-таки нельзя забывать о том, что данная информация может измениться в любой момент.
Для запросов информации об узлах данного диапазона виртуального адресного пространства libNUMA предоставляет два интерфейса:
#include <libNUMA.h>
int NUMA_mem_get_node_idx(void *addr);
int NUMA_mem_get_node_mask(void *addr,
size_t size,
size_t __destsize,
memnode_set_t *dest);
NUMA_mem_get_node_mask устанавливает в dest биты всех узлов памяти, на которых выделены (или будут выделены) страницы диапазона [addr, addr+size) в соответствии с установленной для данной области политикой. А NUMA_mem_get_node_idx лишь обращается к адресу addr и возвращает номер узла памяти, на котором выделен (либо будет выделен) данный адрес. Эти интерфейсы использовать проще, чем get_mempolicy, и в общем случае, пожалуй, следует как раз их и применять.
Процессор, используемый потоком на данный момент, можно узнать, используя sched_getcpu (см. раздел 6.4.3). Основываясь на полученной информации, программа сможет определить узлы памяти, локальные по отоношению к процессору, используя интерфейс libNUMA NUMA_cpu_to_memnode:
#include <libNUMA.h>
int NUMA_cpu_to_memnode(size_t cpusetsize,
const cpu_set_t *cpuset,
size_t memnodesize,
memnode_set_t *
memnodeset);
Вызов этой функции установит (во множестве узлов памяти, на которое указывает четвертый параметр) все биты, соответствующие узлам памяти, локальным по отношению к процессорам во множестве, на которое указывает второй параметр. Так же как и сведения о процессоре, данная информация будет актуальна лишь до того момента, пока не изменится конфигурация машины (например, будут удалены либо добавлены процессоры)
Биты в объектах memnode_set_t могут быть использованы в вызовах низкоуровневых функций вроде get_mempolicy. Хотя в целом удобнее использовать другие функции libNUMA. Обратное отображение можно выполнить через:
#include <libNUMA.h>
int NUMA_memnode_to_cpu(size_t memnodesize,
const memnode_set_t *
memnodeset,
size_t cpusetsize,
cpu_set_t *cpuset);
Множество битов в итоговом cpuset определяет процессоры, локальные по отношению к узлам памяти в соответствующем битовом множестве memnodeset. В случае обоих интерфейсов программист должен помнить о том, что со временем данные сведения меняются (особенно при использовании горячей замены ЦПУ). Часто во входящем множестве установлены все биты. Казалось бы, бессмысленно, но нет: таким образом можно получить весь набор доступных процессоров, который затем можно передать в sched_getaffinity и NUMA_cpu_to_memnode, чтобы определить, к каким узлам памяти поток вообще может иметь прямой доступ.
6.5.6 Наборы ЦПУ и узлов памяти
Подгонка кода под определенные среды - SMP и NUMA - путем использования описанных интерфейсов может оказаться задачей непомерно дорогой, а то и невозможной вовсе, если недоступны исходники. К тому же, системный администратор может ограничить ресурсы, доступные для использования пользователям и/или процессам. Для таких ситуаций ядро Linux поддерживает так называемые наборы ЦПУ (CPU sets). Название немного обманчиво, поскольку включает в себя не только процессоры, но и узлы памяти. К тому же, наборы ЦПУ не имеют ничего общего с типом данных cpu_set_t.
На данный момент интерфейсом к наборам ЦПУ служит специальная виртуальная файловая система. Обычно по умолчанию она не смонтирована (по крайней мере, на сегодня это именно так). Исправить этот недочет можно, используя
mount -t cpuset none /dev/cpuset
Естественно, точка монтирования /dev/cpuset должна уже существовать. Внутри этой директории находится описание корневого (root) набора ЦПУ. Поначалу он включает в себя все процессоры и узлы памяти. Файл cpus там же показывает процессоры, находящиеся на данный момент в наборе, файл mems показывает узлы памяти и файл tasks - процессы.
Для создания нового набора достаточно просто создать новую директорию в любом месте иерархии. Созданный набор унаследует все настройки от родителя, и затем их можно поменять, записывая новые значения в псевдофайлы cpus и mems в новой директории.
Если процесс принадлежит набору ЦПУ, то настройки процессоров и узлов памяти используются в качестве битовых масок привязки к процессорам и политики выделения памяти соответственно. Это означает, что программа не может выбрать никаких других процессоров, кроме прописанных в файле cpus "своего" набора ЦПУ (т.е. в файле tasks которого находится данный процесс). Аналогично для узлов памяти и файла mems.
Программа будет функционировать без ошибок, если только битовые маски не окажутся пустыми, и поэтому наборы ЦПУ фактически невидимы для управляющей программы. Этот подход особенно эффективен на больших машинах с огромным количеством ЦПУ и/или узлов памяти. Перемещение процесса на другой набор ЦПУ заключается лишь в записи его идентификатора в файл the tasks соответствующего набора, вот и вся сложность.
Директории наборов ЦПУ содержат и другие файлы, которые используются для указания различных особенностей конкретного набора - например, для определения поведения при нехватке памяти или для определения исключительного доступа к процессорам и узлам памяти. Заинтересованный читатель может обратиться за подробностями к файлу Documentation/cpusets.txt в дереве исходников ядра.
6.5.7 Явные оптимизации NUMA
Никакая локальная память и никакие правила привязки не помогут, если все потоки на всех узлах требуют доступа к одним и тем же областям памяти. Конечно, можно попросту ограничить количество потоков числом, которое поддерживают процессоры, напрямую соединенные с узлом памяти. Но при этом теряются преимущества многопроцессорных машин с архитектурой NUMA, а значит - не вариант.
Если данные, о которых идет речь, доступны только для чтения, есть простое решение: тиражирование. Раздаем каждому узлу по своей копии данных и исчезает вся необходимость в межузловых попытках доступа. Код, реализующий идею, может выглядеть так:
void *local_data(void) {
static void *data[NNODES];
int node =
NUMA_memnode_self_current_idx();
if (node == -1)
/* Cannot get node, pick one. */
node = 0;
if (data[node] == NULL)
data[node] = allocate_data();
return data[node];
}
void worker(void) {
void *data = local_data();
for (...)
compute using data
}
Функция worker начинает работу с получения указателя на локальную копию данных (для этого происходит вызов local_data). Затем выполняется цикл, использующий полученный указатель. Функция local_data хранит список уже распределенных копий данных. В каждой системе число узлов данных ограничено, поэтому и размер массива указателей на копии данных для каждого узла также ограничен. Взятая из libNUMA функция NUMA_memnode_system_count возвращает как раз это число. Если указатель для текущего узла, определяемый вызовом NUMA_memnode_self_current_idx, не существует, создается новая копия.
Важно понять, что не случится ничего страшного, если потоки после системного вызова sched_getcpu будут назначены другому процессору, находящемуся на другом узле памяти. Это просто означает, что при использовании переменной data в функции worker будет происходить доступ к памяти другого узла. Программа замедлится до следующего вычисления data, но не более. Ядро никогда не будет зазря ребалансировать очереди процессорных запросов, и если это произошло, значит тому была уважительная причина и подобное в ближайшем будущем не повторится.
Все усложняется, если данные, за которые идет конкуренция, предназначены не только для чтения, но и для записи. Тиражирование в данном случае не сработает. В зависимости от конкретной ситуации возможны различные решения.
Например, если данная область памяти используется для сбора результатов, можно сначала создать отдельные области в каждом узле памяти, где происходит сбор локальных результатов. А затем, когда эта работа закончена, все такие локальные области объединяются для получения общего результата. Данный прием работает и в случае, если работа на деле никогда не останавливается, но необходимы промежуточные результаты. Требование такого подхода - должно отсутствовать последействие, то есть текущие результаты не должны зависеть от прошлых результатов.
Хотя, конечно же, всегда лучше иметь прямой доступ к области памяти для записи. Если количество попыток доступа к данной области значительно, то стоит заставить ядро переместить эти страницы памяти на локальный узел. Такой шаг оправдает себя, если число попыток доступа действительно велико и операции записи на разные узлы не происходят параллельно. Только не забывайте, что ядро не может творить чудеса: перемещение страниц включает недешевую операцию копирования, и потому кой-какую цену придется заплатить.
6.5.8 Используем всю полосу пропускания
Цифры на рисунке 5.4 демонстрируют, что доступ к удаленной памяти напрямую ("мимо кэша", т.е. при работе без использования кэша) не особо медленнее доступа к локальной памяти. Это означает, что программа может освободить полосу пропускания к локальной памяти, записывая данные, которые уже не придется считывать, в удаленную память (локальную для другого процессора). Полоса пропускания канала к модулям DRAM и полоса пропускания внутреннего соединения обычно независимы, и поэтому параллельное их использование может повысить общую производительность.
Возможно это на практике или нет, зависит от множества факторов. Необходимо быть уверенным, что запись действительно идет мимо кэша, иначе замедление, связанное с удаленным доступом, будет очень даже ощутимо. Другая проблема возникает, если удаленному узлу самому нужен свой канал памяти полностью. Такая вероятность есть, и она должна быть подробно исследована перед применением предложенного подхода. В теории, несомненно, использование всей доступной процессору полосы пропускания может дать положительный эффект. Например, процессор Opteron семейства 10h может быть напрямую соединен с четырьмя другими процессорами, и использование всей этой увеличенной полосы, дополненное соответствующей предвыборкой (особенно prefetchw), просто обязано улучшить производительность. Если, конечно, система уже работает на полную мощность и не имеет других узких мест.
7 Инструменты для повышения производительности памяти
Существует множество инструментов, помогающих программисту понять, как программа использует кэш и память. Современные процессоры позволяют оценивать производительность на аппаратном уровне. Но некоторые вещи не измеришь напрямую, поэтому нельзя отказаться и от программного моделирования. На верхнем функциональном уровне также имеются специальные инструменты контроля за выполнением процесса. Далее представлен набор широко используемых средств, доступных на большинстве Linux-систем.
7.1 Профилирование памяти
Для профилирования памяти необходима аппаратная поддержка. Конечно, можно собрать какую-то информацию исключительно программными средствами, но то будут либо грубые подсчеты, либо только моделирование. Примеры подобного моделирования можно наблюдать в разделах 7.2 и 7.5. В текущем же разделе сосредоточимся на том, что можно измерить напрямую аппаратными средствами.
В Linux доступ к аппаратному мониторингу производительности обеспечивается через oprofile, который предоставляет возможности по непрерывному профилированию (см. [continuous]); осуществляет статистическое общесистемное профилирование с удобным интерфейсом. Oprofile - далеко не единственный способ использования функциональности процессоров для оценки производительности; разработчики Linux работают над pfmon, который в перспективе может достаточно широко распространиться, став достойным представителем своего класса.
Oprofile предоставляет низкоуровневый интерфейс, простой и минималистичный, c возможностью использования графической оболочки. Из списка всех событий, которые может отслеживать процессор, пользователь должен выбрать нужные ему. В руководствах по архитектуре процессоров эти события описаны, но частенько для верного истолкования необходимо обладать обширными знаниями о самих процессорах. Дальше - больше: возникает проблема с интерпретацией собранных данных. Счетчики измерения производительности содержат абсолютные значения и могут возрастать произвольно. Отсюда вопрос: а насколько большим должно быть значение данного счетчика, чтобы оно действительно считалось большим?
Частичное решение проблемы: не обращать внимания на абсолютные значения, а вместо этого сравнивать значения счетчиков друг с другом. Процессоры могут отслеживать более чем одно событие; получив абсолютные значения, можно вычислить их отношения. Таким образом получаем сравнимые коэффициенты, с которыми можно работать. Часто в качестве делителя берется единица измерения длительности обработки, т.е. количество тактов либо количество команд. Для начала полезно сравнить хотя бы эти два параметра между собой.

Рисунок 7.1: Количество тактов на команду (случайная выборка)
На рисунке 7.1 показано количество тактов на команду (Cycles Per Instruction, CPI) для простого теста в виде выборки из памяти, выполняемой случайным образом для рабочих множеств разных размеров. В большинстве процессоров Intel события, получающие эту информацию, называются CPU_CLK_UNHALTED и INST_RETIRED. Имена говорят сами за себя: первое событие считает количество тактов, второе - количество команд. Наблюдается картина, схожая с проделанными ранее измерениями количества тактов на элемент списка. Для небольших рабочих множеств отношение равно 1 или даже меньше. Измерения проводились на мультискалярном процессоре Intel Core 2, который может работать одновременно с несколькими командами. Если программа не ограничена пропускной способностью памяти, отношение может быть значительно ниже единицы, но в нашем случае и единица - очень хороший результат.
Когда рабочее множество перестает помещаться в кэш L1d, коэффициент CPI возрастает до 3.0. Обратите внимание, что данный коэффициент усредняет расходы на доступ к кэшу L2 всех команд, а не только инструкций памяти. Используя данные отношения "тактов на элемент", можно вычислить, сколько команд тратится на доступ к элементу списка. Ну а когда и кэша L2 становится недостаточно, коэффициент CPI перешагивает планку в 20. Что вполне ожидаемо.
Но счетчики измерения производительности позволяют и глубже взглянуть на происходящее внутри ЦП. При этом следует помнить о различиях в реализации процессоров. Сейчас нас интересуют подробности работы с кэшем, так что соответствующие события и нужно рассматривать. Эти события, их имена и что именно они считают - всё зависит от конкретного процессора. Вот почему так сложно разобраться с использованием oprofile, несмотря на его простой интерфейс: пользователю приходится самостоятельно искать информацию о счетчиках производительности. В разделе 10 мы подробно рассмотрим несколько различных ЦП.
В случае использования Core 2 нам нужны события L1D_REPL, DTLB_MISSES и L2_LINES_IN. Последнее может измерять как все промахи разом, так и отдельно промахи, к которым привели инструкции, а не аппаратная предвыборка. На рисунке 7.2 показаны результаты выполнения теста случайной выборки.

Рисунок 7.2: Промахи кэша (случайная выборка)
Коэффициенты вычислены с использованием количества всех выполненных команд (INST_RETIRED). Это значит, что считались также и те команды, которые не касаются памяти. А это, в свою очередь, значит, что число команд, связанных с памятью и вызвавших промах кэша, еще больше, чем показано на графике.
Число промахов L1d гораздо выше всех остальных потому, что в процессорах Intel используются инклюзивные (включающие, inclusive) кэши, то есть каждый промах L2 включает в себя также и промах L1d. Размер кэша L1d нашего ЦП составляет 32 Кб и мы видим, что, как и ожидалось, промахи L1d начинаются как раз когда рабочее множество достигает этого размера (промахи между отметками в 16 и 32 Кб вызваны использованием кэша, не связанным со структурой списка данных). Обратите внимание, что благодаря аппаратной предвыборке коэффициент промахов L1d держится на 1% при размерах рабочего множества до 64 Кб включительно, а затем прямо-таки взлетает.
Коэффициент промахов L2 держится на нуле до полного исчерпания объема кэша L2; пара промахов в связи с побочными использованиями кэша особо погоды не делают. Но как только размер L2 (221 байт) превышается, коэффициент промахов возрастает. Важно отметить, что коэффициент промахов запросов L2 (L2 demand miss rate) нулю не равен. Это говорит нам о том, что устройство аппаратной предвыборки загружает не все строки кэша, необходимые инструкциям в дальнейшем. И это ожидаемо: идеальная предвыборка невозможна ввиду случайности запросов доступа. Сравните с данными по последовательному чтению, показанными на рисунке 7.3.

Рисунок 7.3. Промахи кэша (последовательная выборка)
Здесь мы видим, что промахи запросов L2 фактически отсутствуют (обратите внимание - масштаб рисунков 7.2 и 7.3 различен). То есть в случае последовательного доступа аппаратная предвыборка работает идеально и почти все промахи L2 вызваны самим устройством предвыборки. Коэффициенты промахов L1d и L2 одинаковы - это значит, что все промахи L1d обрабатываются в L2 без дальнейших задержек. Случай идеальный для любых программ, но, естественно, едва ли достижимый в реальных условиях.
Четвертый график на обоих рисунках - коэффициент промахов DTLB (Intel использует отдельные буферы TLB для кода и данных, и DTLB - это буфер данных). При случайном доступе его значение достаточно велико и заметно влияет на задержки. Любопытно, что эти промахи начинаются еще до появления промахов L2. В случае последовательного доступа промахи DTLB отсутствуют.
Вернувшись к примеру с перемножением матриц (в разделе 6.2.1) и примеру кода в разделе 9.1, сможем задействовать еще три счетчика. А именно, SSE_PRE_MISS, SSE_PRE_EXEC и LOAD_HIT_PRE могут быть использованы для оценки эффективности программной предвыборки. Запустив код из раздела 9.1, получим следующие результаты:
| Описание | Коэффициент |
|---|---|
| Полезные предвыборки NTA | 2.84% |
| Поздние предвыборки NTA | 2.65% |
Низкое значение коэффициента полезной предвыборки NTA говорит о том, что многие команды предвыборки выполняются для уже загруженных строк кэша, когда никаких действий не требуется. То есть на декодирование таких команд и просмотр кэша процессор тратит время впустую. Тем не менее, слишком сильно придираться к коду не стоит. Многое зависит от объема кэшей в используемом процессоре, к тому же свою лепту вносит и само устройство аппаратной предвыборки.
Низкое значение коэффициента поздней предвыборки NTA на самом деле обманчиво. Этот коэффициент показывает, что 2,65% всех команд предвыборки выполняются слишком поздно. Инструкция, которой нужны данные, выполяется еще до того, как данные успевают оказаться в кэше. Нужно помнить, что всего лишь 2,84%+2,65%=5,5% всех команд предвыборки оказались полезными. А из всех полезных, 48% были выполнены с опозданием. Следовательно, код можно оптимизировать, учитывая следующие моменты:
- большинство команд предвыборки бесполезны.
- команды предвыборки следует использовать с учетом аппаратной основы.
В качестве упражнения пусть читатель попробует определить лучшее решение для доступного ему оборудования. Точная спецификация аппаратной части играет очень большую роль. На процессорах Core 2 задержка арифметических операций SSE составляет 1 такт. В прошлых версиях она составляла 2 такта, следовательно, устройство аппаратной предвыборки и команды предвыборки имели больше времени для загрузки данных.
Чтобы определить, нужно в данном случае использовать предвыборку или нет, используется программа opannotate. Она показывает исходники или ассемблерный код программы и выделяет команды с опознанным событием. Обратите внимание, что возможны два источника неопределенности:
- Oprofile выполняет вероятностное профилирование. Это значит, что записывается только каждое N-ое событие (порог N свой для каждого события, при этом имеется некое минимальное значение), дабы не слишком замедлять работу системы. Может случиться так, что какие-то строки кода вызывают сотню событий и тем не менее их не будет в отчете.
- Не все события записываются верно. К примеру, значение счетчика инструкций на момент записи определенного события может оказаться неправильным. Дать стопроцентно верное значение мешает мультискалярность процессоров. Хотя на некоторых процессорах есть и точные события.
Аннотированные листинги могут быть полезны не только для определения информации касательно предвыборки. Каждое событие записывается с указателем команды, а значит, можно найти и другие "горячие точки" программы. Области кода с большим количеством событий INST_RETIRED выполняются часто и потому заслуживают пристального внимания. Области, где происходит много промахов кэша, требуют использования инструкций предвыборки для избежания последних.
Есть тип событий, который можно отслеживать без аппаратной поддержки. Это ошибки отсутствия страниц, или страничные ошибки (page faults). За исправление этих ошибок отвечает операционная система, и в случае появления таковых, она же их и подсчитывает. Системой выделяются два вида страничных ошибок:
Легкие страничные ошибки (Minor Page Faults)
К ним относятся ошибки отсутствия анонимных (например, не связанных с файлами) страниц, которые пока еще не были использованы, ошибки копирования при записи (copy-on-write), а также ошибки страниц, содержимое которых уже находится где-то в памяти.
Значительные страничные ошибки (Major Page Faults)
Для разрешения этих ошибок необходим доступ к диску для получения связанных с файлами (или находящихся в файле подкачки) данных.
Очевидно, что значительные страничные ошибки обходятся системе значительно дороже легких. Но и последние тоже нельзя сбрасывать со счетов. В обоих случаях необходимо обратиться к ядру, найти новую страницу, очистить ее либо заполнить соответствующими данными, после чего отразить изменения в дереве таблиц страниц. Последний шаг потребует синхронизации с другими задачами чтения или изменения дерева таблиц страниц, что приведет к еще большим задержкам.
Легче всего получить информацию о количестве страничных ошибок - использовать инструмент time. Только заметьте: оригинальный инструмент, а не тот, что встроен в оболочку. Результаты вывода можно лицезреть на рисунке 7.4. {Обратная косая (бэкслэш) в начале предотвращает вызов встроенных команд.}
$ \time ls /etc
[...]
0.00user 0.00system 0:00.02elapsed 17%CPU (0avgtext+0avgdata 0maxresident)k
0inputs+0outputs (1major+335minor)pagefaults 0swaps
Рисунок 7.4. Вывод утилиты time
Нас интересует последняя строка. Утилита докладывает о том, что произошла одна значительная и 335 легких страничных ошибок. Точные цифры постоянно меняются; в частности, если сразу же запустить программу повторно, скорее всего не будет обнаружено ни одной значительной страничной ошибки. Если программа выполняет одно и то же действие и окружающие условия не меняются, то общее количество страничных ошибок будет постоянной величиной.
Особенной фазой по отношению к страничным ошибкам является запуск программы. Каждая используемая страница вызовет страничную ошибку; внешне это проявляется (особенно в приложениях с графическим интерфейсом) в том, что чем больше страниц памяти используется, тем дольше программа запускается. В разделе 7.5 познакомимся с утилитой, позволяющей оценивать именно этот момент.
Заглянув внутрь time, можно обнаружить, что используется функциональность rusage. Системный вызов wait4 заполняет объект struct rusage, пока родитель ожидает завершения дочернего процесса; это именно то что нужно для инструмента, подобного time. Но процесс также может запросить информацию об использовании ресурсов (отсюда и пошло название rusage - Resource Usage, использование ресурсов) как своих, так и ресурсов завершенных дочерних процессов.
#include <sys/resource.h>
int getrusage(__rusage_who_t who, struct rusage *usage)
Параметр who определяет процесс, о котором запрашивается информация. На данный момент, определены значения RUSAGE_SELF (о себе) и RUSAGE_CHILDREN (о дочерних процессах). Коэффициент использования ресурсов дочерними процессами определяется в момент завершения каждого из них. Эта величина - общая для всех дочерних процессов, а не для каждого из них по отдельности. В ближайшем будущем планируется реализовать возможность запроса информации об отдельных потоках, в связи с чем появится и третье значение - RUSAGE_THREAD. Структура rusage определена таким образом, что может содержать все типы показателей, включая время выполнения, количество посланных сообщений IPC, используемую память и число страничных ошибок. Последнее можно найти в членах ru_minflt и ru_majflt данной структуры.
Программист, желающий определить, снижается ли производительность его программы из-за страничных ошибок и где именно это происходит, может регулярно проверять данные члены и затем сравнивать полученные значения с предыдущими.
Такую информацию видно и "снаружи", если запрашивающий имеет необходимые привилегии. Псевдофайл /proc/<PID>/stat, где <PID> - идентификатор интересующего нас процесса, содержит информацию (в виде пар чисел) о страничных ошибках в полях с десятого по четырнадцатое. Эти пары представляют собой общее количество легих и значительных страничных ошибок процесса и его дочерних процессов соответственно.
7.2 Моделирование кэшей ЦПУ
В то время как техническое описание работы кэша относительно легко понять, гораздо тяжелее разобраться, как именно с ним взаимодействует конкретная программа. Программисты не работают напрямую с адресами, ни с абсолютными, ни с относительными. Адреса определяются, во-первых, компоновщиком; а во-вторых - уже во время выполнения программы, ядром и динамическим компоновщиком. Ожидается, что полученный в результате компоновки код сможет работать со всеми возможными адресами; в исходном же коде нет ни намека на то, какие адреса использовать. Вот поэтому понять, как именно программа работает с памятью, и бывает довольно тяжело. {При программировании на низком уровне, близком к аппаратному, ситуация может отличаться - но такой вариант не является типичным для нормального программирования и вообще возможен только в особых случаях, например с устройствами, отображаемыми в память.}
Разобраться в использовании кэша могут помочь инструменты профилирования уровня ЦПУ, вроде oprofile, описанного в разделе 7.1. Предоставляемые ими результаты привязаны к фактически используемому оборудованию, и могут быть собраны относительно быстро, если нет необходимости в большей детализации. Но если углубленная детализация все-таки потребуется, oprofile выходит из игры: слишком часто придется прерывать работу потока, что недопустимо. Более того, чтобы протестировать поведение программы на разном оборудовании, придется как-то находить другие машины и выполнять программу на них. Иногда (а скорее - очень и очень часто) это попросту невозможно. Возьмем пример - рисунок 3.8. Чтобы собрать такие данные с помощью oprofile, потребовалось бы 24 компьютера разных конфигураций, многих из которых вообще не существует на данный момент.
На деле те данные были получены с использованием программы моделирования кэша. Программа носит имя cachegrind и использует инструментарий valgrind, который первоначально разрабатывался для отладки работы с памятью. Valgrind моделирует выполнение программы и при этом поддерживает различные расширения, вроде cachegrind, позволяющие в ней копаться. Утилита cachegrind использует эти возможности для перехвата всех адресных обращений к памяти; затем она моделирует работу кэшей L1i, L1d и L2 с заданными объемами, размерами строк кэша и соответствующей ассоциативностью.
Для применения утилиты необходимо запустить программу, вызвав её через valgrind:
valgrind --tool=cachegrind command arg
Это простейшая форма запуска: программа command запускается с параметром arg и моделированием трех кэшей, в которых используются размеры и ассоциативность, аналогичные таковым на используемом процессоре. Часть результатов выводится при стандартной ошибке во время выполнения программы; показывается общая статистика использования кэша, как показано на рисунке 7.5.
==19645== I refs: 152,653,497
==19645== I1 misses: 25,833
==19645== L2i misses: 2,475
==19645== I1 miss rate: 0.01%
==19645== L2i miss rate: 0.00%
==19645==
==19645== D refs: 56,857,129 (35,838,721 rd + 21,018,408 wr)
==19645== D1 misses: 14,187 ( 12,451 rd + 1,736 wr)
==19645== L2d misses: 7,701 ( 6,325 rd + 1,376 wr)
==19645== D1 miss rate: 0.0% ( 0.0% + 0.0% )
==19645== L2d miss rate: 0.0% ( 0.0% + 0.0% )
==19645==
==19645== L2 refs: 40,020 ( 38,284 rd + 1,736 wr)
==19645== L2 misses: 10,176 ( 8,800 rd + 1,376 wr)
==19645== L2 miss rate: 0.0% ( 0.0% + 0.0% )
Рисунок 7.5. Общие выходные данные cachegrind
Дано общее число команд и обращений к памяти, количество промахов кэшей L1i/L1d и L2, коэффициенты промахов и т.п. Утилита может даже разделять обращения к L2 на запросы инструкций и запросы данных, а все обращения к данным - на запросы чтения и запросы записи.
А еще интереснее становится, если изменить параметры моделируемых кэшей и сравнить результаты. Чтобы заставить cachegrind игнорировать параметры кэшей используемого процессора и применять указанные в командной строке, используются параметры --I1, --D1 и --L2. Ну например, строка
valgrind --tool=cachegrind --L2=8388608,8,64 command arg
приведет к моделированию кэша L2 объемом 8 Мб с 8-канальной ассоциативностью и строкой кэша размером 64 байта. Обратите внимание, что параметр --L2 в командной строке идет перед именем моделируемой программы.
Этим возможности cachegrind не исчерпываются. Перед завершением процесса cachegrind создает файл с именем cachegrind.out.XXXXX, где XXXXX - идентификатор процесса (PID). В файле содержится как общая суммарная информация, так и подробности использования кэша каждой функцией исходного кода. Данные можно просмотреть с помощью программы cg_annotate.
Выходные данные, предоставляемые программой, содержат общую информацию об использовании кэша, которая была показана при завершении процесса, а также подробности использования строк кэша каждой функцией программы. Для связи данных с соответствующими функциями необходимо, чтобы cg_annotate могла сопоставить адреса функциям. То есть, для наилучшего результата должна быть доступна информация отладки. Если таковая отсутствует, то могут помочь таблицы идентификаторов ELF, но, поскольку внутренние идентификаторы отсутствуют в динамической таблице, результаты будут неполными. На рисунке 7.6 показана часть выходных данных для того же прогона программы, что и на рисунке 7.5.
--------------------------------------------------------------------------------
Ir I1mr I2mr Dr D1mr D2mr Dw D1mw D2mw file:function
--------------------------------------------------------------------------------
53,684,905 9 8 9,589,531 13 3 5,820,373 14 0 ???:_IO_file_xsputn@@GLIBC_2.2.5
36,925,729 6,267 114 11,205,241 74 18 7,123,370 22 0 ???:vfprintf
11,845,373 22 2 3,126,914 46 22 1,563,457 0 0 ???:__find_specmb
6,004,482 40 10 697,872 1,744 484 0 0 0 ???:strlen
5,008,448 3 2 1,450,093 370 118 0 0 0 ???:strcmp
3,316,589 24 4 757,523 0 0 540,952 0 0 ???:_IO_padn
2,825,541 3 3 290,222 5 1 216,403 0 0 ???:_itoa_word
2,628,466 9 6 730,059 0 0 358,215 0 0 ???:_IO_file_overflow@@GLIBC_2.2.5
2,504,211 4 4 762,151 2 0 598,833 3 0 ???:_IO_do_write@@GLIBC_2.2.5
2,296,142 32 7 616,490 88 0 321,848 0 0 dwarf_child.c:__libdw_find_attr
2,184,153 2,876 20 503,805 67 0 435,562 0 0 ???:__dcigettext
2,014,243 3 3 435,512 1 1 272,195 4 0 ???:_IO_file_write@@GLIBC_2.2.5
1,988,697 2,804 4 656,112 380 0 47,847 1 1 ???:getenv
1,973,463 27 6 597,768 15 0 420,805 0 0 dwarf_getattrs.c:dwarf_getattrs
Рисунок 7.6: Выходные данные cg_annotate
Столбцы Ir, Dr и Dw показывают общее использование кэша, а не промахи, которые, в свою очередь, показаны в оставшихся двух столбцах. Эти данные можно использовать для поиска области кода, приводящей к большинству промахов кэша. В первую очередь, пожалуй, стоит сконцентрироваться на промахах L2, а затем уже переходить к оптимизации промахов L1i/L1d.
cg_annotate может детализировать данные еще сильнее. Если дано имя исходного файла, утилита сможет пометить каждую строку (кроме имени программы) количеством промахов и попаданий кэша, соответствующих данной строке. Такая информация позволит программисту точно выявить строку, приводящую к промахам. Интерфейс программы сыроват: на момент написания данной работы, файл данных cachegrind и исходный файл должны находиться в одной директории.
А теперь снова следует повторить: cachegrind - утилита моделирования, которая не использует аппаратные измерения процессора. Фактическая реализация кэшей процессора может очень и очень сильно отличаться. Cachegrind моделирует алгоритм вытеснения LRU (Least Recently Used), который для кэшей с большим уровнем ассоциативности явно слишком дорог. Более того, при моделировании не принимаются во внимание системные вызовы и контекстные переключения, а ведь и те и другие могут занять большую часть L2 и переполнить L1i/L1d. В итоге число промахов кэша при модуляции оказывается меньше, чем оно есть на самом деле в реальных условиях. Но тем не менее, cachegrind - отличная утилита для изучения работы программы с памятью и сопутствующих проблем.
7.3 Оценка использования памяти
Первый шаг к оптимизации использования памяти - узнать, сколько памяти выделяет для себя программа и, если возможно, где именно (в каком месте кода). К счастью, для данной цели существуют простые в применении утилиты, даже не требующие рекомпиляции или какой-либо модификации испытуемой программы.
Для первого такого инструмента, massif, важно не удалять информацию отладки, автоматически генерируемую компилятором. Данная утилита предоставляет обзор использования памяти за некоторый период времени. На рисунке 7.7 показан пример выходных данных.
Рисунок 7.7. Выходные данные massif
Как и cachegrind (раздел 7.2), massif использует инструментарий valgrind. Запускается через
valgrind --tool=massif command arg
где command arg - наблюдаемая программа и ее параметр(ы). В процессе моделирования работы распознаются все вызовы функций выделения памяти. Место и время каждого вызова записываются; выделенный объем памяти добавляется к памяти, выделенной предыдущими вызовами из этого же места, а также к общему объему памяти всей программы. По тому же алгоритму обрабатываются и функции, освобождающие память, только, естественно, наоборот: размер освобожденного блока вычитается из соответствующих суммарных объемов. В дальнейшем собранная таким образом информация может быть использована для построения диаграммы, описывающей использование памяти за весь жизненный цикл программы и устанавливающей соответствие каждого момента времени месту кода, откуда было вызвано выделение памяти. Перед завершением процесса, massif создает два файла: massif.XXXXX.txt и massif.XXXXX.ps, где XXXXX в обоих случаях - идентификатор процесса (PID). Файл .txt содержит суммарную информацию по использованию памяти для всех мест вызова, а .ps вы видите на рисунке 7.7.
Также massif может контролировать использование стека программой, что может помочь определить общий объем памяти, которую занимает программа. Но иногда это невозможно. Бывает, что valgrind не может определить границы стека - например, когда используется signaltstack или стеки потоков. В таких случаях не имеет смысла добавлять размеры этих стеков к общей сумме. Есть и другие примеры, когда контролировать стек бессмысленно. В любом из этих случаев massif следует запускать с дополнительным параметром --stacks=no. Обратите внимание, это параметр valgrind, и поэтому он ставится перед именем испытуемой программы.
В некоторых программах используются их собственные функции выделения памяти, либо т.н. "интерфейсные" функции, предоставляющие интерфейс вызова системных функций выделения памяти. В первом случае выделение памяти проходит незамеченным; во втором - записанные места вызова несут дезинформацию, поскольку записывается адрес вызова внутри интерфейсной функции, а не адрес самой этой функции. В связи с этим, существует возможность дополнять список функций выделения памяти дополнительными функциями. Параметр --alloc-fn=xmalloc говорит программе, что xmalloc - тоже функция выделения памяти, что нередко в программах GNU. Тогда будут записываться вызовы самой xmalloc, а не вызовы выделения памяти изнутри нее.
Вторая утилита - memusage; это часть библиотеки GNU C. Представляет собой упрощенную версию massif (и существовавшая задолго до появления последней). Всё, что она контролирует - общий объем памяти, выделенной из кучи (включая возможные вызовы mmap и им подобных, если используется параметр -m), и, при необходимости, использование стека. Результаты могут быть показаны в виде диаграммы либо общего использования памяти за время работы, либо в виде разбиения по вызовам функций выделения памяти. Диаграммы создаются по отдельности сценарием memusage, который (как и valgrind), необходимо использовать для запуска приложения:
memusage command arg
При использовании параметра -p IMGFILE диаграмма будет создана в файле IMGFILE с расширением PNG. Код, собирающий информацию, запускается прямо в самой программе, это не моделирование, в отличие от valgrind. Следовательно, memusage гораздо быстрее, чем massif, и используется даже тогда, когда утилита massif бесполезна. Помимо суммарного потребления памяти, программа также записывает размеры выделенной памяти при каждом вызове и выводит их в виде гистограммы. Эта информация также показывается при возникновении ошибки.
Иногда программу, которую нужно исследовать, невозможно (или запрещено) запускать напрямую. Например, стадия компиляции gcc, запускаемая драйвером gcc. В таких случаях имя исследуемой программы необходимо предоставить сценарию memusage, передав его через параметр -n NAME. Также этот параметр полезен, если исследуемая программа запускает другие программы. В случае, когда имя программы не указано, профилированию подвергаются все запускаемые приложения.
У обеих утилит, massif и memusage, есть дополнительные параметры. Когда программисту нужна дополнительная функциональность, сперва стоит прочесть мануал или справку, дабы убедиться, не реализована ли уже данная функциональность.
Теперь мы знаем, каким образом собираются данные касательно выделения памяти, и далее необходимо обсудить, как эти данные можно интерпретировать в контексте использования памяти и кэша. Главные моменты эффективного динамического распределения памяти - последовательное выделение и компактность выделенной области памяти. Таким образом мы возвращаемся к повышению эффективности предвыборки и снижению количества промахов кэша.
Когда программе нужно считать некоторое количество данных для последующей обработки, это можно организовать, создав список, каждый элемент которого содержит новый элемент данных. Потери при таком методе выделения памяти теоретически должны быть минимальны (один указатель для простого связанного списка), но на деле использование таких данных кэшем может чрезвычайно снизить производительность.
Например, одна из проблем - нет никаких гарантий, что последовательно выделенная память окажется в лежащих рядом областях. Тому есть множество возможных причин:
- адреса блоков памяти внутри большого участка, управляемого распределителем памяти, возвращаются от конца к началу;
- свободное место на участке памяти заканчивается, и происходит переход к новому участку, в совсем другой области адресного пространства;
- запросы на выделение разных объемов памяти обслуживаются разными пулами памяти;
- чередование выделений памяти разными потоками многопоточных приложений.
Если нужно распределить память для данных заранее для будущей обработки, применение связанного списка - явно плохая идея. Нет никакой гарантии (и даже вероятности), что соседние элементы списка окажутся соседними и в памяти. Для гарантии смежности выделенных областей память ни в коем случае нельзя распределять мелкими участками. Необходимо использовать другой слой работы с памятью; и программист легко может его применить. Я имею в виду реализацию obstack, доступную в библиотеке GNU C. Этот распределитель запрашивает большие блоки памяти у системного распределителя и затем уже из этих блоков выделяет произвольные области, маленькие или не очень. Области, выделяемые таким образом, всегда будут расположены последовательно, если только не закончится место в том самом большом блоке. Что, учитывая объемы, запрашиваемые на выделение, происходит довольно редко. Применение obstack не означает полный отказ от стандартного распределителя памяти, поскольку obstack ограничен в возможностях освобождения объектов. Подробнее см. руководство к библиотеке GNU C.
Итак, каким же образом, используя диаграммы, можно понять, где лучше использовать obstack (или другие подобные приемы)? Точное место возможной оптимизации нельзя определить, не обратившись к исходникам, но диаграмма помогает выбрать отправную точку для поисков. Если из одного и того же места происходит много запросов на выделение памяти, значит, тут может помочь выделение большого блока (см.obstack). На рисунке 7.7 вероятный кандидат на оптимизацию наблюдается по адресу 0x4c0e7d5. На промежутке от 800мс и до 1800мс с начала работы это единственная растущая область, ну за исключением верхней, зеленой. Более того, возрастание не резкое - значит, имеем дело с большим числом выделений относительно малых объемов памяти. Вне всяких сомнений, это наш кандидат на применение технологии obstack или ей подобных.
Другая проблема, которую помогают увидеть диаграммы - слишком большое суммарное число попыток выделения памяти. Особенно легко это заметить, если диаграмма строится в зависимости не от времени, а от количества вызовов (установлено по умолчанию в memusage). В этом случае пологий склон диаграммы означает большое количество выделений малых объемов памяти. Утилита memusage не может сказать, где именно происходят запросы выделения, но это "лечится" сравнением с выводом massif, а иногда программист и сам сразу может определить проблемное место. Множество мелких запросов выделения памяти следует объединить, чтобы достичь последовательного использования памяти.
Касательно последнего случая есть еще один момент, не менее важный: множество небольших выделений приводит к увеличению административной (управляющей) информации. Само по себе это не страшно. На диаграмме вывода massif (рис.7.7) область такой информации называется "heap-admin" и она довольно мала. Но в зависимости от реализаций malloc эта административная информация может выделяться вместе с блоками данных, в той же области памяти. Что сейчас и имеет место в текущей реализации malloc в библиотеке GNU C: каждый выделенный блок начинается с двухсловного (минимум) заголовка: 8 байт для 32-битных платформ, 16 байт для 64-битных. К тому же, размеры блоков обычно немного больше, чем нужно, из-за особенностей управления памятью (размеры блоков округляются до определенных значений).
Всё вышесказанное означает, что память, используемая программой, смешивается с памятью, используемой распределителем исключительно для административных целей. И мы получаем что-то вроде этого:

Каждый блок представляет собой одно слово (word) памяти и всего на этой небольшой области мы видим четыре выделенных блока. Заголовки и заполнение незначащей информацией привели к издержкам (потерям полезного места) в 50%. Такое расположение заголовка автоматически снижает коэффициент эффективной предвыборки процессора на те же 50%. Если бы блоки обрабатывались последовательно (для получения максимальной пользы от предвыборки), процессор бы считал все слова, содержащие заголовки и заполнители, в кэш, несмотря на то что само приложение никогда не будет к ним обращаться ни для записи, ни для чтения. Заголовки используются только средой выполнения, а она вступает в дело только при освобождении блока памяти.
Можно прийти к выводу, что следует использовать другую реализацию, дабы поместить административную информацию отдельно. Несомненно, в некоторых реализациях так и делается, и это может быть полезно. Но при этом необходимо помнить о множестве нюансов, и не в самую последнюю очередь - о безопасности. Независимо от того, к чему мы придем в будущем, проблема заполнения блоков [незначащей информацией] никогда не исчезнет (а одни эти "пустышки", без учета заголовков, занимают 16% всего объема памяти в нашем примере). Этого можно избежать только если программист возьмет на себя прямой контроль за выделением памяти. "Пустышки" также могут появиться в связи с требованиями выравнивания памяти, но и этот момент - во власти программиста.
7.4 Улучшаем прогнозирование ветвлений
В разделе 6.2.2 были упомянуты два метода улучшения работы L1i с помощью прогнозирования ветвлений и изменения порядка блоков, а именно: явное (статическое) предсказание через __builtin_expect и оптимизацию по профилю (profile guided optimization = PGO). Правильное прогнозирование ветвлений в первую очередь влияет на производительность, но в данный момент нас интересует иное - оптимизация использования памяти.
Использовать __builtin_expect (а лучше - макросы likely и unlikely) достаточно просто. Определения помещаются в центральном заголовке, и компилятор берет на себя всё остальное. Хотя есть тут небольшая проблема: программист может легко перепутать определения - использовать likely вместо unlikely, и наоборот. Даже если применять инструмент вроде oprofile для контроля за ошибочным прогнозированием ветвлений и промахами L1i, подобные проблемы сложно обнаружить.
Тем не менее, есть один простой способ. Листинг в разделе 9.2 демонстрирует альтернативные определения макросов likely и unlikely, с помощью которых прямо при выполнении программы отслеживается, верно заданы явные предсказания или же вкралась ошибка. Затем программист или тестер проверяет результаты и вносит поправки при необходимости. Производительность программы в расчет при этом не берется - просто проверяются статически заданные программистом предсказания, не более. С подробностями и исходниками можно ознакомиться в вышеупомянутом разделе.
Механизм PGO в наши дни довольно легко использовать через gcc. Процесс состоит из трех шагов, при этом необходимо соблюдать некоторые требования. Во-первых, все исходные файлы должны быть скомпилированы с дополнительным параметром -fprofile-generate. Этот параметр должен использоваться при всех запусках компилятора и должен быть передан команде, компонующей программу. Смешивать объектные файлы, скомпилированные с применением этого параметра и без него - теоретически можно, но с последними могут возникнуть проблемы.
Компилятор создает исполняемый файл, работающий как обычно, но только он значительно больше и медленнее, поскольку записывает (и сохраняет) всю информацию о ветвлениях. Компилятор также создает файл с расширением .gcno для каждого входного файла. Этот файл содержит информацию относительно ветвлений в коде и его нужно сохранить на будущее.
Как только исполняемый файл будет готов, следует выполнить репрезентативный набор тестов с разными рабочими нагрузками. Какая бы нагрузка не использовалась, в итоге исполняемый файл будет оптимизирован для эффективного выполнения соответствующей задачи. Неоднократные прогоны программы в пределах одного теста возможны - и, в общем, даже необходимы; каждое выполнение вносит свой вклад в итоговый выходной файл. Перед завершением работы программы данные, собранные в течение текущего прогона, записываются в файлы с расширением .gcda, которые создаются в каталоге с исходниками. Программу можно запускать из любого каталога, исполняемый файл можно копировать, но каталог с исходниками в любом случае должен быть доступен для записи. Еще раз: для каждого входного файла исходников создается свой выходной файл. В случае нескольких прогонов важно, чтобы файлы .gcda, созданные во время предыдущего прогона, оставались в том же каталоге с исходниками, иначе итоговые данные будет невозможно собрать в один файл.
После завершения всех тестовых прогонов программу следует перекомпилировать. Необходимо и крайне важно, чтобы файлы .gcda оставались в том же каталоге, где находятся файлы исходников. Эти файлы нельзя перемещать, иначе компилятор их попросту не найдет, что приведет к несовпадению контрольных сумм. При повторной компиляции параметр -fprofile-generate нужно заменить на -fprofile-use. Важно не вносить в исходники никаких изменений, могущих повлиять на генерируемый исполняемый код. Это значит: можно изменять форматирование (пробелами) и редактировать комментарии, но вот добавление новых ветвлений или блоков приводит к недействительности всей собранной информации, и компиляция в этом случае окончится неудачей.
Вот и всё, что требуется от программиста; и вправду довольно простой процесс. Самое главное, на что необходимо обратить внимание - это выбор подходящих репрезентативных тестов для сбора информации. Если тестовые нагрузки не будут совпадать с реальными будущими условиями эксплуатации программы, выполненная оптимизация принесет больше вреда чем пользы. Поэтому в общем случае трудно использовать PGO для создания библиотек, ведь они могут быть использованы в самых разных сценариях, иногда чуть ли не противоположных. В связи с этим, если нет уверенности в схожести условий использования, то обычно лучше полагаться исключительно на статическое прогнозирование ветвлений с применением __builtin_expect.
Пара слов о файлах .gcno и .gcda. Это бинарные файлы, первоначально не предназначенные для просмотра. Тем не менее, при необходимости для их исследования можно применить инструмент gcov, также являющийся частью пакета gcc. В основном эта утилита применяется для анализа покрытия (coverage, отсюда и название), но при этом используется тот же формат файлов, что и для PGO. Утилита gcov генерирует выходные файлы с расширением .gcov для каждого исходного файла с исполняемым кодом (обычно включая системные заголовки). Эти выходные файлы представляют собой листинги, аннотированные в соответствии с заданными gcov параметрами - могут быть показаны вероятности, счетчик ветвлений и т.п.
7.5 Оптимизация страничных ошибок
В операционных системах с замещением страниц по требованию (Linux - одна из таких систем) всё, что делает вызов mmap, - изменяет таблицы страниц. А именно - он гарантирует, что в случае обращения к страницам, связанным с файлами, соответствующие данные (файлы) будут доступны, а в случае обращения к анонимной памяти будут предоставлены страницы, инициализированные нулями. То есть, при вызове mmap в таких системах не происходит собственно выделения памяти. {Не согласны и хочется возразить? Погодите маленько, далее мы поговорим об исключениях.}
Память выделяется при первом обращении к странице, будь то запрос чтения или записи, либо при выполнении кода. В ответ на возникающую в таком случае страничную ошибку ядро берет на себя управление и определяет (с помощью дерева таблиц страниц), какие данные должна содержать страница. Такая обработка страничных ошибок недешево обходится, но тем не менее именно это происходит с каждой страницей, используемой процессом.
Для минимизации стоимости страничных ошибок (стоимость здесь и далее - в смысле "потери производительности") необходимо снижать общее число используемых страниц памяти. Этой цели может послужить соответствующая оптимизация исходного кода. Для уменьшения стоимости определенной области кода (например, кода инициализации), можно реорганизовать его в таком порядке, чтобы в данной области количество затрагиваемых страниц памяти было минимально. Но не так уж просто определить "правильный" порядок.
Автор данной работы написал утилиту на основе инструментария valgrind, позволяющую контролировать появление страничных ошибок. Но контролировать не количество, а причину их возникновения. Инструмент pagein выдает информацию о порядке и времени возникновения страничных ошибок. Выходные данные, записываемые в файл pagein.<PID>, выглядят как показано на рисунке 7.8.
0 0x3000000000 C 0 0x3000000B50: (within /lib64/ld-2.5.so)
1 0x 7FF000000 D 3320 0x3000000B53: (within /lib64/ld-2.5.so)
2 0x3000001000 C 58270 0x3000001080: _dl_start (in /lib64/ld-2.5.so)
3 0x3000219000 D 128020 0x30000010AE: _dl_start (in /lib64/ld-2.5.so)
4 0x300021A000 D 132170 0x30000010B5: _dl_start (in /lib64/ld-2.5.so)
5 0x3000008000 C 10489930 0x3000008B20: _dl_setup_hash (in /lib64/ld-2.5.so)
6 0x3000012000 C 13880830 0x3000012CC0: _dl_sysdep_start (in /lib64/ld-2.5.so)
7 0x3000013000 C 18091130 0x3000013440: brk (in /lib64/ld-2.5.so)
8 0x3000014000 C 19123850 0x3000014020: strlen (in /lib64/ld-2.5.so)
9 0x3000002000 C 23772480 0x3000002450: dl_main (in /lib64/ld-2.5.so)
Рисунок 7.8: Выходные данные утилиты pagein
Второй столбец содержит адрес запрошенной страницы. Содержит она код или данные, указывается в третьем столбце, соответственно C' (Code) - код,D' (Data) - данные. Четвертый столбец содержит количество тактов, прошедших с момента первой страничной ошибки. Оставшаяся часть строки - попытка valgrind'а определить имя для адреса, вызвавшего данную страничную ошибку. Само значение адреса всегда верно, но с именем могут быть несоответствия, если нет доступа к информации отладки.
В примере, показанном на рисунке 7.8, выполнение начинается с адреса 0x3000000B50, который запрашивает страницу по адресу 0x3000000000. Вскоре запрашивается следующая за ней страница, на этот раз функцией под названием _dl_start. Код инициализации обращается к переменной на странице 0x7FF000000. Это происходит по прошествии всего 3,320 тактов после первой страничной ошибки и больше всего похоже на вторую инструкцию программы (от первой ее отделяют лишь три байта). Давайте взглянем на саму программу: видим нечто необычное относительно доступа к памяти. А именно, обращает на себя внимание инструкция call, которая вроде бы не загружает и не записывает никаких данных. Но она сохраняет адрес возврата в стек, что, собственно, мы и наблюдали в выходном отчете. Конечно, имеется в виду не официальный стек процесса, а внутренний стек приложения, используемый valgrind. Следовательно, при интерпретации результатов pagein важно помнить, что valgrind может внести некоторые искажения.
Выходные данные pagein можно использовать для определения, какие последовательности инструкций программы в идеале должны быть расположены рядом друг с другом. С первого же взгляда на код /lib64/ld-2.5.so видно, что первые команды сразу вызывают функцию _dl_start, и что два этих места расположены на разных страницах. Таким образом, реорганизация исходника путем перемещения кодовых последовательностей на одну и ту же страницу памяти может помочь избежать страничной ошибки - или хотя бы отсрочить её. Но пока что определение максимально эффективной организации кода - процесс обременительный. Поскольку повторные запросы страниц утилитой не записываются, то чтобы увидеть результаты изменений, приходится использовать метоб проб и ошибок. Путем анализа диаграммы вызовов можно предсказать возможные последовательности запросов, что поможет ускорить процесс сортировки функций и переменных.
На очень грубом, поверхностном уровне, последовательности запросов можно увидеть, изучая объектные файлы, из которых в итоге создается исполняемый модуль или DSO (Dynamic Shared Object = динамически разделяемый объект). Начиная с одной или нескольких отправных точек (например, имен функций), можно вычислять цепочки зависимостей. На уровне объектных файлов это неплохо работает даже без приложения особых усилий. На каждом проходе определяем, какие из объектных файлов содержат нужные нам функции и переменные. Начальный набор файлов необходимо определить однозначно. Затем выделяем все неопределенные ссылки в этих объектных файлах и добавляем их [ссылки] к набору нужных идентификаторов. И так повторяем, пока набор не станет стабилен.
Второй шаг - определение порядка. Объектные файлы необходимо скомпоновать друг с другом таким образом, чтобы "задеть" как можно меньше страниц памяти. Вдобавок, ни одна функция не должна пересекать границу страницы. Сложность в том, что для лучшего расположения объектных файлов необходимо знать, что дальше будет делать компоновщик. Тут важно, что компоновщик помещает объектные файлы в исполняемый модуль (или DSO) в том же порядке, в каком они расположены во входных файлах (например, архивах) и в командной строке. Это дает программисту значительные возможности.
Для тех, кто готов потратить немного больше времени: были успешные попытки реорганизации, сделанные с помощью автоматического отслеживания запросов через перехватчики (hooks) __cyg_profile_func_enter и __cyg_profile_func_exit, которые вставляет gcc при запуске с параметром -finstrument-functions [oooreorder]. Подробную информацию об интерфейсах __cyg_* можно найти в руководстве к gcc. Используя трассировку программы, программист может более точно определить цепочки запросов. Результаты, достигнутые в [oooreorder] - снижение стоимости инициализации на 5%, и это достигнуто всего лишь перестановкой функций. Основная польза - снижение числа страничных ошибок, но и кэш TLB тоже играет роль, и немалую, учитывая, что в виртуальных средах промахи TLB обходятся гораздо дороже.
Комбинируя анализ вывода утилиты pagein с информацией о последовательности запросов, можно оптимизировать определенные этапы работы программы (инициализация тому примером), минимизируя число страничных ошибок.
Ядро Linux предоставляет два дополнительных механизма для избежания страничных ошибок. Первый - флаг для mmap, заставляющий ядро не просто модифицировать таблицу страниц, но, по сути, заранее загрузить все страницы в отображаемой области. Это достигается просто - к четвертому параметру вызова mmap добавляется флаг MAP_POPULATE. В результате вызов mmap обойдется значительно дороже, но, если все страницы, выделенные по данному запросу, будут использованы в ближайшее время, преимущества могут оказаться огромными. Вместо обработки множества страничных ошибок, каждая из которых обходится довольно дорого в связи с требованиями синхронизации и пр., программе придется обработать всего один, хоть и дорогой, вызов mmap. Обратная сторона медали, т.е. этого флага, проявляется в случаях, когда большая часть выделенных страниц не используется в ближайшее время после вызова (или не используется вообще). Выделенные, но не используемые страницы - просто пустая трата времени и памяти. Страницы, выделенные, но не использованные сразу (в ближайшее время) после вызова, тоже засоряют систему. Память выделяется еще до того, когда это действительно нужно, что теоретически может привести к нехватке свободного места. С другой стороны, в худшем случае страница просто будет использована для других целей (ведь она еще не была изменена), что не так уж дорого обходится системе - хотя, с учетом выделения, чего-то тоже стоит.
В целом, механизму MAP_POPULATE недостает избирательности. А вторая проблема: это лишь оптимизация; даже если выделены все-все страницы - не беда. Если система слишком занята для выполнения операции, предварительное выделение может быть отменено. А когда страница будет реально нужна, опять же произойдет страничная ошибка; ничего страшного - по крайней мере, не страшнее искусственного создания нехватки ресурсов. Альтернатива - применение POSIX_MADV_WILLNEED с функцией posix_madvise. Это подсказка операционной системе, что в ближайшем будущем программе понадобится страница, описанная в запросе. Ядро может как проигнорировать эту подсказку, так и заранее выделить страницы. Преимущество этого механизма в том, что он более избирателен. Предварительно загружены могут быть как отдельные страницы, так и диапазоны страниц в любом отображенном адресном пространстве. В случае отображенного в память файла, содержащего множество не используемых при выполнении данных, этот метод имеет огромное преимущество перед MAP_POPULATE.
Помимо этих активных подходов к минимизации количества страничных ошибок, также можно применить более пассивный подход, популярный среди разработчиков оборудования. Динамически разделяемый объект (DSO) занимает смежные страницы в адресном пространстве, часть из них содержит код, другая часть - данные. Чем меньше размер страницы, тем больше страниц необходимо для одного объекта DSO. А это, в свою очередь, увеличивает число страничных ошибок. Но важно отметить, что верно и обратное. Чем больше размер страницы, тем меньше их нужно для отображения; а следовательно, уменьшается и число страничных ошибок.
Большинством архитектур поддерживаются страницы размером в 4 Кб. На IA-64 и PPC64 популярен размер страниц в 64 Кб. Это значит, что минимальный объем выделяемой памяти составляет 64 Кб. Данное значение необходимо указывать при компиляции ядра, и его нельзя изменить динамически, во время работы. По крайней мере, пока нельзя. Интерфейсы ABI архитектур, поддерживающих несколько размеров страниц, позволяют запускать приложения с любым из поддерживаемых размеров. Среда выполнения сама сделает необходимые настройки, а корректно написанная программа ничего не заметит. Увеличенные размеры страниц означают больше потерь в результате того, что страницы используются лишь частично, но в некоторых ситуациях это вполне допустимо.
Большинство архитектур также поддерживают очень большие размеры, от 1 Мб и больше. Такие страницы иногда бывают полезны, но выделять всю память такими огромными кусками - бессмысленно. Слишком велики будут потери физической памяти. Но огромные страницы имеют свои преимущества: если используются не менее огромные наборы данных, то хранение их в страницах по 2 Мб на х86-64 потребует на 511 страничных ошибок меньше (в расчете на каждую большую страницу), чем применение страничек по 4 Кб. Это может в корне всё изменить. Решение: избирательно выделять память таким образом, чтобы использовались большие страницы именно для указанного диапазона адресов, а для остальных отображений того же процесса оставить обычные размеры страниц.
Использование больших страниц имеет свою цену. Поскольку области физической памяти, используемые для больших страниц, должны быть непрерывны, то спустя какое-то время отображение таких страниц может стать невозможным вследствие фрагментации памяти. Не доводите до такого. Люди работают над проблемами дефрагментации памяти и способами избежания фрагментации, но это очень сложно. Для больших страниц размером, скажем, 2 Мб, необходимо найти 512 последовательных страничек, а это сложно сделать практически всегда, за исключением одного периода: загрузки системы. Вот поэтому-то сегодня для использования больших страниц применяется специальная файловая система, hugetlbfs. Эта псевдо-файловая система резервируется по требованию системного администратора с помощью записи количества страниц, которое необходимо зарезервировать, в
/proc/sys/vm/nr_hugepages
Данная операция не будет выполнена, если не будет найдено достаточно свободных, последовательно расположенных областей памяти. Становится еще интересней, если используется виртуализация. Виртуальная система, созданная с использованием модели VMM, не имеет прямого доступа к физической памяти и потому не может сама выделить hugetlbfs. Ей приходится полагаться на менеджер VMM, и не факт, что данная функциональность вообще поддерживается. Что касается модели KVM, ядро Linux, на котором запущен модуль KVM, может выполнить монтирование hugetlbfs и передать подмножество страниц для выделения на одном из гостевых доменов.
В дальнейшем, когда программе потребуется страница большого размера, будет несколько вариантов:
- программа может использовать разделяемую память System V, применив флаг
SHM_HUGETLB. - файловая система
hugetlbfsможет быть полностью смонтирована и затем программа может создавать файл уже внутри, и использоватьmmapдля отображения одной (или более) страниц в качестве анонимной памяти.
В первом случае hugetlbfs не требует монтирования. Код, запрашивающий одну или более страниц, будет выглядеть примерно так:
key_t k = ftok("/some/key/file", 42);
int id = shmget(k, LENGTH, SHM_HUGETLB|IPC_CREAT|SHM_R|SHM_W);
void *a = shmat(id, NULL, 0);
Критичные моменты данной кодовой последовательности - применение флага SHM_HUGETLB и выбор верного значения LENGTH, которое должно быть кратно размеру больших страниц системы. Для разных архитектур используются разные значения. Использование интерфейса разделяемой памяти System V неудобно, ибо завязано на ключевом аргументе для различия (разделения) отображений. Интерфейс ftok может легко привести к конфликтам, и поэтому лучше - если возможно - использовать другие механизмы.
Если требование обязательного монтирования системы hugetlbfs - не проблема, то лучше использовать именно этот вариант заместо разделяемой памяти System V. На деле может возникнуть пара затруднений с использованием специальной файловой системы - во-первых, ядро должно поддерживать ее, и во-вторых, пока нет стандартизированной точки монтирования. Когда файловая система смонтирована, к примеру, в /dev/hugetlb, программа легко может ее использовать:
int fd = open("/dev/hugetlb/file1", O_RDWR|O_CREAT, 0700);
void *a = mmap(NULL, LENGTH, PROT_READ|PROT_WRITE, fd, 0);
Используя одно и то же имя файла в запросе open, разные процессы могут совместно использовать одни и те же большие страницы и взаимодействовать. Также есть возможность сделать страницы исполняемыми, для чего нужно установить флаг PROT_EXEC в запросе mmap. Как и в примере с разделяемой памятью System V, значение LENGTH должно быть кратно размеру больших страниц.
Аккуратно написанные программы (а такими должны быть все программы) могут определять точку монтирования во время выполнения, используя функцию вроде этой:
char *hugetlbfs_mntpoint(void) {
char *result = NULL;
FILE *fp = setmntent(_PATH_MOUNTED, "r");
if (fp != NULL) {
struct mntent *m;
while ((m = getmntent(fp)) != NULL)
if (strcmp(m->mnt_fsname, "hugetlbfs") == 0) {
result = strdup(m->mnt_dir);
break;
}
endmntent(fp);
}
return result;
}
Больше информации об этих двух случаях можно найти в файле hugetlbpage.txt, являющемся частью дерева исходников ядра. Этот файл также описывает особый подход, требуемый в случае IA-64.

Рисунок 7.9: Выборка с применением больших страниц памяти, NPAD=0
Чтоб продемонстрировать преимущества больших страниц, на рисунке 7.9 показаны результаты выполнения теста случайной выборки при NPAD=0. Это те же данные, что показаны на рисунке 3.15, но в этот раз мы используем также страницы памяти большого размера. Как видно - преимущество в производительности может быть огромно. Для 220 байт использование больших страниц дало прирост производительност в 57%. Это связано с тем, что данный размер всё еще полностью умещается в одну страницу размером 2 Мб, и потому не происходит никаких промахов DTLB.
Далее прирост поначалу не столь высок, но с повышением размера рабочего множества снова увеличивается. Для рабочего множества в 512 Мб использование больших страниц дает прирост производительности в 38%. Кривая теста с использованием больших страниц выравнивается на отметке в 250 тактов. Когда рабочие множества достигают размеров более 227 байт, цифры снова значительно вырастают. Причина выравнивания в том, что буфер TLB в 64 элемента для страниц в 2 Мб покрывает 227 байт.
Как показывают цифры, большую часть потерь при использовании больших рабочих множеств составляют потери TLB. Использование интерфейсов, описанных в этом разделе, дает большой выигрыш. Скорее всего, данные этого графика соответствуют идеальному варианту, но даже реально работающие программы демонстрируют значительное увеличение в скорости. Среди программ, использующих сегодня страницы больших размеров, находятся базы данных, поскольку они работают с большими объемами данных.
На данный момент нет способов использования больших страниц для отображения данных, связанных с файлами. Есть заинтересованность в реализации данной возможности, но все сделанные пока что предложения подразумевают использование исключительно больших страниц с помощью файловой системы hugetlbfs. Это неприемлемо: использование больших страниц в данном случае должно быть прозрачным. Ядро может легко определять, какие отображения достаточно велики, и может автоматически использовать страницы большого размера. Проблема в том, что ядро не всегда в курсе важных нюансов. Если память, отображаемая большими страницами, в дальнейшем потребуется разделить на маленькие, по 4 Кб (например, в случае частичного изменения защиты с применением mprotect), то будет потеряно очень много драгоценных ресурсов, в частности, последовательных областей физической памяти. Так что можно быть уверенным: пройдет еще какое-то время, прежде чем такой подход будет успешно реализован.
8 Грядущие технологии: что нас ждет?
В предыдущих разделах мы видели, что рост числа процессоров или ядер вызывает значительные проблемы с производительностью. Но именно этого роста и следует ожидать в ближайшем будущем. Количество ядер в процессорах будет увеличиваться; и для реализации возникающего таким образом потенциала программы просто обязаны использовать параллельность больше чем когда-либо, поскольку производительность каждого ядра в отдельности уже не будет расти такими темпами, как раньше.
8.1. Проблемы с атомарными операциями
Традиционно, синхронизация доступа к разделяемым структурам данных реализуется двумя способами:
- применением взаимных исключений (мьютексов), для чего обычно используются возможности системной среды исполнения;
- применением безблокировочных (lock-free) структур данных.
Недостаток второго варианта: от процессора требуется поддержка примитивов, способных выполнить полностью всю операцию атомарно. Не все процессоры поддерживают такие примитивы. На большинстве архитектур поддержка сводится к атомарным операциям чтения и записи одного [машинного] слова. Есть два основных способа их реализации (см. раздел 6.4.2):
- использование атомарной операции "сравнение и замена" (CAS);
- использование пары инструкций load lock/store conditional (LL/SC).
Нетрудно заметить, что операция CAS может быть реализована с применением инструкций LL/SC. И поэтому именно она применяется в качестве основы большинства атомарных операций и безблокировочных структур данных.
Некоторые процессоры, в особенности архитектуры x86 и x86-64, поддерживают куда более широкий набор атомарных инструкций. Многие из которых представляют собой версии CAS, оптимизированные под отдельные задачи. Например, атомарный инкремент хранящегося в памяти значения может быть реализован с помощью инструкций CAS и LL/SC, но родная, "нативная" поддержка атомарного инкрементирования на процессорах x86/x86-64 работает быстрее. Важно, чтобы программисты при работе знали об этих инструкциях и о том, как их применять. Хотя в этом нет ничего нового.
Но что действительно выделяет эти две архитектуры, так это поддержка операций CAS с двойными словами (DCAS). Это значительный плюс для некоторых (но не для всех, см. [dcas]) приложений . В качестве примера использования DCAS давайте попробуем написать безблокировочную структуру данных стека LIFO, основанную на массиве. Первая попытка, с применением встроенных средств gcc, показана на рисунке 8.1.
struct elem {
data_t d;
struct elem *c;
};
struct elem *top;
void push(struct elem *n) {
n->c = top;
top = n;
}
struct elem *pop(void) {
struct elem *res = top;
if (res != NULL)
top = res->c;
return res;
}
Рисунок 8.1: Стек LIFO, не ориентированный на многопоточность
Видно, что этот код никак не подходит для многопоточных приложений. Параллельные запросы из разных потоков будут менять значение глобальной переменной top, не принимая во внимание изменения, производимые другими потоками. Одни элементы могут неожиданно теряться, а другие, удаленные - возникать вновь, как по волшебству. Можно, конечно, использовать взаимные исключения, но сейчас мы постараемся обойтись одними лишь атомарными операциями.
Для начала попытаемся решить проблему, применив CAS при вставке и удалении элементов списка. В итоге получим код, показанный на рисунке 8.2.
#define CAS __sync_bool_compare_and_swap
struct elem {
data_t d;
struct elem *c;
};
struct elem *top;
void push(struct elem *n) {
do
n->c = top;
while (!CAS(&top, n->c, n));
}
struct elem *pop(void) {
struct elem *res;
while ((res = top) != NULL)
if (CAS(&top, res, res->c))
break;
return res;
}
Рисунок 8.2: Стек LIFO, организованный с применением CAS
На первый взгляд, должно работать. Переменная top не изменяется до тех пор, пока не совпадет с элементом, который находился на вершине стека при начале операции. Но нужно принимать во внимание параллельность на всех уровнях. Другой поток, работающий с этой же структурой, может вступить в дело в самый неподходящий момент. Один из таких случаев - так называемая проблема ABA. Представьте, что произойдет, если второй поток запланирован прямо перед инструкцией CAS в pop и он выполняет следующие действия:
l = pop()push(newelem)push(l)
В результате этих действий элемент, находящийся на вершине стека, возвращается на своё место, но второй элемент изменился. При этом в первом потоке, поскольку верхний элемент остался прежним, операция CAS выполнится успешно. Но значение res->c уже не верно. Это указатель на второй элемент первоначального стека, а не на newelem. И что в итоге? Новый элемент потерян.
В литературе [см. lockfree] (локально) можно найти предложения по решению этой проблемы, основанные на особенностях некоторых процессоров. А именно, имеются в виду процессоры x86 и x86-64 и их способность выполнять инструкции DCAS. На рисунке 8.3 показана третья версия кода, на этот раз с применением DCAS.
#define CAS __sync_bool_compare_and_swap
struct elem {
data_t d;
struct elem *c;
};
struct lifo {
struct elem *top;
size_t gen;
} l;
void push(struct elem *n) {
struct lifo old, new;
do {
old = l;
new.top = n->c = old.top;
new.gen = old.gen + 1;
} while (!CAS(&l, old, new));
}
struct elem *pop(void) {
struct lifo old, new;
do {
old = l;
if (old.top == NULL) return NULL;
new.top = old.top->c;
new.gen = old.gen + 1;
} while (!CAS(&l, old, new));
return old.top;
}
Рисунок 8.3: Стек LIFO, основанный на CAS с двойными словами
В отличие от предыдущей пары примеров, это лишь псевдокод (на данный момент), поскольку gcc пока "не понимает" передачу структур в качестве параметров CAS. Тем не менее, такого примера должно быть достаточно для понимания принципов подхода. К указателю на вершину стека добавляется счетчик обращений. Так как он изменяется при любой операции, будь то push или pop, описанная выше проблема ABA решается сама собой. К тому времени как первый поток возобновит работу, пытаясь обновить указатель top, счетчик обращений уже будет увеличен трижды. Следовательно, инструкция CAS завершится неудачей, и на следующей итерации цикла будут определены верные значения первого и второго элементов стека. Мы избежали ошибки. Проблема решена!
Но решена ли она на самом деле? Авторы данного труда [lockfree] (локально) убеждены, что да - и надо отдать им должное, такой подход стоит упоминания. Действительно, вполне возможно создать структуры данных для стека LIFO, позволяющие использовать вышеприведенный код. Но в общем случае, этот подход не лучше предыдущего. Проблемы с параллельностью не исчезли - они лишь переместились в другое место. Предположим, поток выполняет pop и затем прерывается сразу после проверки old.top == NULL. Тут второй поток использует pop и завладевает бывшим первым элементом стека. Поток может сделать с ним что угодно - поменять все значения, к примеру, или (в случае динамически выделяемых элементов) освободить память.
Затем первый поток возобновляет работу. В переменной old все еще хранится предыдущее значение вершины стека. А если точнее, указатель top ссылается на элемент, только что обработанный вторым потоком. Оператором new.top = old.top->c первый поток обращается к значению элемента через указатель. Но элемент, на который ссылается указатель, возможно, уже освобожден. А часть адресного пространства, где он находился, возможно, недоступна - происходит сбой. В случае работы с данными родового типа подобные ситуации недопустимы. Любое решение этой проблемы обходится чрезвычайно дорого: память нельзя освобождать, ну или необходимо получить подтверждение того, что ни один поток более не ссылается на нее, прежде чем выполнить освобождение. Учитывая, что безблокировочные структуры данных по определению должны работать быстрее других и лучше поддерживать параллельность, видим, что эти дополнительные требования попросту сводят на нет все преимущества. Решить проблему может так называемая "сборка мусора" при работе с памятью, но она поддерживается не всеми языками. А где поддерживается - имеет свою цену.
Для более сложных структур данных обычно всё еще хуже. В вышеупомянутом документе также описана реализация FIFO, с некоторыми уточнениями в последующих материалах. Но и там всё те же проблемы. Поскольку на существующем оборудовании (x86, x86-64) инструкции CAS могут изменять только пару последовательно расположенных в памяти слов, то в других часто встречающихся ситуациях они вообще бывают бесполезны. К примеру, невозможно атомарное добавление либо удаление элементов в любом месте двусвязного списка. {Для справки: разработчики IA-64 также не реализовали эту возможность. Они позволяют сравнивать два слова, но заменять - только одно.}
Проблема в том, что обычно используется несколько адресов памяти, а вся операция сможет завершиться успешно только если ни одно из значений, хранящихся в этих ячейках, не было изменено при параллельном доступе. Данная концепция хорошо известна в сфере управления базами данных, и именно оттуда пришло одно из самых многообещающих предложений по разрешению описанной дилеммы.
8.2. Транзакционная память
Херлих и Мосс в своем новаторском исследовании 1993 года [transactmem] (локально) предложили применить аппаратный транзакционный подход к организации операций с памятью, поскольку исключительно средствами ПО эффективно решить проблему не удавалось. В то время в Digital Equipment Corporation уже столкнулись с проблемами масштабируемости на топовом многопроцессорном оборудовании (имеющем пару десятков процессоров). Принцип тот же, что и с транзакциями в базах данных: либо результат транзакции виден сразу и полностью, либо она отменяется и все значения остаются неизменными.
Вот это и предложили применить к памяти, и именно этого в предыдущем разделе мы пытались добиться, разрабатывая алгоритмы с применением атомарных операций. Транзакционная память рассматривается как замена (или расширение) атомарных операций в различных ситуациях, и особенно в случае безблокировочных структур данных. Интеграция системы транзакций в процессор может показаться ужасно сложной затеей, но на самом деле в большинстве процессоров уже реализовано нечто подобное.
Например, в некоторых ЦП реализация операций LL/SC представляет собой ничто иное, как транзакцию. Инструкция SC отменяет или подтверждает транзакцию на основе того, были обращения к области памяти или нет. Транзакционная память расширяет эту концепцию. А именно, подразумевается, что в транзакции теперь принимают участие не две простые инструкции, а множество их. Чтобы разобраться в том, как оно работает, давайте сначала посмотрим, каким образом можно реализовать пару LL/SC. {Но это не означает, что на деле инструкции реализуются именно так.}
8.2.1. Реализация Load Lock/Store Conditional
При выполнении инструкции LL значение, хранящееся в области памяти, загружается в регистр. В процессе данное значение загружается и в кэш данных первого уровня (L1d). В дальнейшем инструкция SC завершится успешно только в случае, если значение останется нетронутым. Как процессор может это проконтролировать? Ответ приходит сам собой, если вернуться к описанию протокола MESI, рисунок 3.18. Когда другой процессор меняет значение в памяти, копия в кэше L1d первого процессора должна быть помечена как недействительная. При выполнении инструкции SC на первом процессоре ей придется загружать значение в L1d заново. А это процессор уже должен отследить.
Есть и другие моменты, которые следует уладить, которые касаются контекстных переключений (возможная модификация данных на том же процессоре) и случайных перезагрузок строки кэша после записи на другом процессоре. Но это всё решаемо - политикой (очистка кэша при контекстном переключении) и дополнительными флагами, либо отдельными строками кэша для инструкций LL/SC. В целом, реализация LL/SC обеспечивается фактически по умолчанию при использовании протокола согласования кэша вроде MESI.
8.2.2. Операции с транзакционной памятью
Чтобы транзакционная память была действительно полезной, транзакции не должны завершаться с первой же инструкцией сохранения. Вместо этого должна быть реализована возможность выполнения нужного числа операций загрузки и сохранения. Следовательно, необходимы отдельные инструкции завершения (подтверждения) и отмены. Вскоре увидим, что нужна еще одна, третья инструкция, позволяющая запрашивать текущее состояние транзакции и проверять, была она отменена или нет.
Всего должны быть реализованы три операции с памятью:
- Чтение из памяти
- Чтение с последующей записью
- Запись в память
Для чего нужен второй, особый тип операции чтения, можно понять, взглянув внимательнее на протокол MESI. Для "нормального" чтения подходят строки кэша, находящиеся в состояниях E' иS'. А операция чтения второго типа может быть выполнена только над строкой, имеющей статус `E'. В каких именно случаях нужно применять второй тип, будет вскользь упомянуто ниже. А для детального изучения вопроса заинтересованный читатель может обратиться к литературе о транзакционной памяти, для начала можно порекомендовать [transactmem] (локально).
Также, помимо только что указанных трех операций, нам нужна возможность управления транзакциями, которое в основном состоит из операций завершения и отмены (commit и abort соответственно) - они нам уже знакомы по работе с транзакциями в базах данных. Хотя есть и еще одна операция, в теории необязательная, но на практике, для написания серьезных программ с применением транзакционной памяти - попросту необходимая. Имеется в виду инструкция, позволяющая потоку проверить, выполняется ли еще транзакция и может ли она быть успешно завершена в дальнейшем, либо она уже потерпела неудачу и в любом случае будет отменена.
Далее обсудим, как на деле эти операции взаимодействуют с кэшами ЦПУ и шиной. Но сначала давайте взглянем на примеры кода, использующего транзакционную память. Это должно облегчить понимание раздела в дальнейшем.
8.2.3. Пример кода, использующего транзакционную память
Для примера вернемся к уже известному нам коду и продемонстрируем реализацию стека LIFO с применением транзакционной памяти.
struct elem {
data_t d;
struct elem *c;
};
struct elem *top;
void push(struct elem *n) {
while (1) {
n->c = LTX(top);
ST(&top, n);
if (COMMIT())
return;
... delay ...
}
}
struct elem *pop(void) {
while (1) {
struct elem *res = LTX(top);
if (VALIDATE()) {
if (res != NULL)
ST(&top, res->c);
if (COMMIT())
return res;
}
... delay ...
}
}
Рисунок 8.4: Стек LIFO, организованный с применением транзакционной памяти
Данный листинг напоминает самый первый, вообще не ориентированный на многопоточность, - и это дополнительный плюс: писать код, использующий транзакционную память, проще. Чем он отличается от того, первого, так это операциями LTX, ST, COMMIT и VALIDATE. С помощью них организуется доступ к транзакционной памяти. На деле есть еще одна операция, LT, которую в данном случае мы не использовали. LT представляет собой неисключающее (non-exclusive) чтение, LTX - исключающее (exclusive) чтение, а ST - запись в транзакционную память. Операция VALIDATE проверяет, выполняется ли еще транзакция и может ли она быть завершена успешно. Возвращается true, если с транзакцией все в порядке. Если же транзакция уже помечена как отмененная, то она окончательно отменяется и следующая инструкция начинает новую транзакцию. Специально для этого в коде имеется новый блок if, на случай, если транзакция все еще выполняется.
Операция COMMIT завершает транзакцию; если завершение проходит успешно, возвращается true. Это значит, что данная часть программы завершена и поток может двигаться дальше. Если вернулось false, значит, вся кодовая последовательность должна быть выполнена заново. Для этого введен внешний цикл while. Хотя стоит отметить, это не всегда так уж необходимо - иногда лучшим выбором будет просто продолжить работу.
Особенность операций LT, LTX и ST в том, что они могут окончиться неудачей, и никак об этой неудаче не сообщить. Проверить это программа может только через VALIDATE или COMMIT. То есть в случае операции загрузки (чтения) может оказаться, что загруженное в регистр значение - ошибочно, недействительно; и вот поэтому в вышеприведенном примере необходимо использовать VALIDATE, прежде чем разыменовывать указатель. В следующем разделе увидим, почему следует использовать именно такую реализацию. Хотя возможно, что с широким распространением транзакционной памяти в процессорах будет реализовано нечто иное. Но тем не менее, авторы [transactmem] (локально) пришли именно к тому, что мы сейчас описываем.
Функцию push можно описать так: транзакция начинается с чтения указателя на вершину стека. Чтение запрашивает исключительное владение, ибо далее в эту переменную будет производиться запись. Если ранее другой поток уже начал транзакцию, чтение завершится неудачей и транзакция - всё еще выполняющаяся - будет помечена как отмененная; загруженное при этом значение может являться просто мусором. Это значение, независимо от статуса, сохраняется в поле next нового элемента списка. Всё нормально, ведь данный элемент пока нигде не используется, и доступ к нему имеет только один поток. Затем указатель на вершину стека заменяется указателем на новый элемент. Если транзакция еще не была помечена как отмененная, то данная замена указателя пройдет успешно. Так всё происходит в общем случае. Неудача может произойти, только если поток использует для доступа к указателю код, отличающийся от представленного в функциях push и pop. Если на момент вызова ST транзакция уже отменена, то не выполнится вообще ничего. Ну и в конце концов, поток пытается завершить транзакцию. Если завершение проходит успешно, всё готово - и другие потоки могут начинать свои транзакции. Если транзакция была отменена на каком-либо из этапов, ее необходимо выполнить с самого начала. Но перед этим лучше всего вставить некоторую задержку (delay). Если упустить данный момент, поток может войти в непрерывно повторяющийся цикл, тратя ресурсы и перегревая процессор.
Функция pop чуть более сложная. Она начинается так же - чтением вершины стека с запросом на исключительное владение. Затем немедленно происходит проверка, успешно ли выполнилась операция LTX. Если нет - далее ничего не происходит, кроме задержки перед следующей итерацией. Если указатель top считался успешно, значит, он находится в нужном нам состоянии и мы можем разыменовать указатель. Вспомните, именно здесь была проблема с использованием атомарных операций; а с применением транзакционной памяти всё проходит гладко. Последующая операция, ST, выполняется только если стек не пуст, так же как и в первоначальном коде, не поддерживающем многопоточность. И наконец, транзакция завершается. Если завершение успешно, функция возвращает старый указатель на вершину, иначе ставим задержку и пытаемся заново. Важный нюанс: следует помнить, что операция VALIDATE отменяет транзакцию, если та помечена соответствующим образом. Следующая операция транзакционной памяти начнет новую транзакцию, следовательно, мы должны пропустить весь оставшийся код в функции.
Как именно работают задержки, увидим, когда транзакционная память будет реализована аппаратно. Если реализация окажется неудачной, то производительность системы серьезно пострадает.
8.2.4. Протокол шины для транзакционной памяти
Рассмотрев основные принципы работы с транзакционной памятью, теперь можем углубиться в подробности ее реализации. Обратите внимание, что реализация основана не на используемом оборудовании. Вместо этого, она отталкивается от первоначального описания принципов транзакционной памяти и знаний о протоколах согласования кэша. Кое-какие подробности опущены, но это не должно помешать разобраться в рабочих характеристиках.
На деле транзакционная память не является какой-то отдельной памятью - это было бы глупо и бессмысленно, ведь нам необходима возможность проведения транзакций в любом месте адресного пространства потока. Вместо этого, она реализуется на первом уровне кэша. В теории, можно было б ее разместить прямо в обычном кэше L1d, но в [transactmem] (локально) показано, что это не самая лучшая идея. Скорее, мы увидим кэш транзакций, параллельный кэшу данных первого уровня. Все запросы доступа будут использовать кэши верхних уровней точно так же, как они используют L1d. По идее, кэш транзакций должен быть гораздо меньше кэша данных первого уровня. Если он будет полностью ассоциативен, то размер такого кэша должен определяться количеством операций, которое может содержать транзакция. Различные реализации, скорее всего, будут ограничены архитектурой и/или конкретной версией процессора. Легко представить кэш транзакций, состоящий из 16 элементов, а то и меньше. Выше, в примере, нам нужна была только одна единственная область памяти; алгоритмы с транзакционными рабочими множествами большего размера будут ну очень сложными. Вполне возможно появление процессоров, поддерживающих несколько активных транзакций одновременно. В таком случае число элементов кэша увеличивается, но остается достаточно небольшим для того, чтобы сохранить полную ассоциативность.
Кэши транзакций и L1d - эксклюзивны, то есть раздельны. Это значит, что строка кэша может содержаться в одном из кэшей, но никогда - в обоих сразу. Каждый слот в кэше транзакций в любой момент времени находится в одном из четырех состояний, поддерживаемых протоколом MESI. Дополнительно, каждый слот (строка) хранит некоторое состояние транзакции. Данные состояния перечислены ниже (названия приведены в соответствии с [transactmem] (локально):
EMPTY
слот не содержит никаких данных. Статус MESI всегда 'I'.
NORMAL
слот содержит подтвержденные данные. Они также могут находиться и в кэше L1d. Статусы MESI могут быть 'M', 'E' и 'S'. Поддержка состояния 'M' означает, что при подтверждении (завершении) транзакции данные не обязаны записываться в основную память (ну если только данная область не объявлена как некэшируемая или со сквозной записью). Это может значительно повысить производительность.
XABORT
слот содержит данные, отбрасываемые при отмене. Явная противоположность XCOMMIT. Все данные, созданные во время транзакции, содержатся в кэше транзакций, ничего не записывается в основную память до завершения транзакции. Это ограничивает максимальный размер транзакции, но зато при этом означает, что никакая другая память, кроме кэша транзакций, не должна следить за состояниями XCOMMIT/XABORT конкретной области. Возможные статусы MESI: 'M', 'E' и 'S'.
XCOMMIT
слот содержит данные, отбрасываемые при подтверждении. Полезная оптимизация для реализации в процессорах. Если в процессе выполнения транзакции значение, хранящееся в области памяти, изменяется, то старое значение нельзя сразу отбрасывать - если транзакция будет отменена, его нужно будет восстановить. Статусы MESI те же, что и для XABORT. Заметное отличие от XABORT состоит в том, что если кэш транзакций заполняется, все XCOMMIT-элементы (во всех состояниях) сбрасываются, при этом элементы, находящиеся в состоянии 'M', должны быть сначала записаны обратно в основную память.
При вызове операции LT, процессор сначала выделяет две строки кэша. При этом в первую очередь ищутся NORMAL-слоты по адресу операции, т.е. кэш-попадания. Если такой элемент найден, то ищется второй и значение копируется. Один элемент помечается как XABORT, второй как XCOMMIT.
В случае когда кэш-попадания отсутствуют, т.е. данного адреса в кэше нет, ищутся слоты с пометкой EMPTY. Если таковых не обнаружено, то ищутся слоты NORMAL. Старое содержимое затем сбрасывается в память, если слот находится в состоянии 'M'. Ну а если не выходит найти даже NORMAL-слотов, то придется пожертвовать элементами XCOMMIT. Хотя, всё это - нюансы конкретной реализации. Максимальный размер транзакции определяется размером кэша транзакций, и поскольку количество слотов, необходимое для каждой операции в транзакции, фиксировано, количество транзакций можно ограничить таким образом, чтоб не приходилось сбрасывать XCOMMIT-элементы.
Если адрес не найден в кэше транзакций, на шину передается запрос T_READ. Использование именно его указывает системе, что это запрос для кэша транзакций. В остальном он практически не отличается от обычного запроса шины READ. Как и в случае с обычным READ-запросом, сначала опрашиваются кэши других процессоров. Если в них ничего не обнаружено, искомое значение считывается из основной памяти. Протоколом MESI определяется состояние новой строки - 'E' либо 'S'. Разница между T_READ и READ проявляется, если строка кэша в момент запроса используется активной транзакцией другого процессора или ядра. В таком случае операция T_READ завершается неудачей, никаких данных не передается. Транзакция, отправившая запрос, помечается как отмененная, а значение, в ней используемое (обычно полученное простым чтением регистра), освобождается. Вернувшись к нашему примеру, видим, что такое поведение не создает проблем, если правильно применять операции с транзакционной памятью. А именно, прежде чем использовать загруженное значение, его необходимо верифицировать с помощью VALIDATE. В большинстве случаев это ничего не стоит и лишним не будет. При попытке реализовать структуру FIFO с помощью атомарных операций мы увидели, что именно такой проверки и не хватает, чтобы наш безблокировочный код заработал как надо.
Операция LTX почти не отличается от LT. Но именно что "почти". Отличие в том, что для взаимодействия с шиной применяется операция T_RFO, а не T_READ. T_RFO, как и стандартный запрос шины RFO, содержит требование исключительного владения строкой кэша. В результате строка кэша будет находиться в состоянии 'E'. Как и T_READ, запрос T_RFO может завершиться неудачей, и при этом значение так же отбрасывается. Если строка кэша уже находится в локальном кэше транзакций со статусом 'M' или 'E', ничего делать не требуется. Если же строка в локальном кэше имеет статус 'S', то необходим запрос шины для аннулирования всех остальных копий.
Операция ST подобна LTX. Сначала значение переводится в исключительное владение локального кэша транзакций. Затем операция ST копирует значение во вторую строку (слот) кэша и помечает элемент как XCOMMIT. Другой слот помечается как XABORT и туда записывается новое значение. Если транзакция уже была отменена ранее, либо отменяется при неудаче последних действий (являющихся аналогом LTX), записи не происходит.
Ни VALIDATE, ни COMMIT не могут автоматически скрытно обратиться к шине для записи в основную память. И это огромный плюс по сравнению с атомарными операциями. В случае атомарных операций параллельность обеспечивается благодаря записи измененных значений обратно в основную память. И если вы дочитали до этого места, то уже должны понимать, насколько это дорого. С применением же транзакционной памяти, запись в основную память не навязывается. Если в кэше нет EMPTY-слотов, придется пожертвовать текущим содержимым, при этом только содержимое строк со статусом 'M' должно быть записано в основную память. Подход не отличается от используемого в обычной кэш-памяти, и обратную запись можно выполнять без особых гарантий атомарности. Если размер кэша достаточно велик, его содержимое может храниться долгое время. Если транзакции снова и снова работают с одной и той же областью памяти, прирост скорости может быть попросту огромен, поскольку в отличие от "обычного" подхода, когда на каждой итерации имеем одну или две записи в основную память, при подходе с применением транзакционной памяти все запросы обрабатываются кэшем транзакций, который так же быстр, как L1d.
Всё, что операции VALIDATE и COMMIT делают в случае отмены транзакции, это помечают XABORT-слоты как пустые, а XCOMMIT-слоты - как NORMAL. Соответственно, когда операцией COMMIT транзакция успешно завершается, слоты XCOMMIT помечаются как пустые, а XABORT - как NORMAL. Все эти операции крайне быстры, и выполняются в пределах кэша транзакций. Никакой дополнительной информации другим процессорам, желающим произвести транзакцию, не передается; они просто пробуют свою удачу опять и опять. Как это организовать эффективно - другой вопрос. В примере выше мы просто ставили ...delay... в соответствующих местах. Возможно, в будущих процессорах появится аппаратная реализация нужного нам алгоритма задержек.
Подведем итоги. Операции с транзакционной памятью обращаются к шине только при начале новой транзакции либо когда в выполняющуюся транзакцию нужно загрузить новую строку, которую не удалось найти в кэше транзакций. Операции в транзакциях, помеченных как отмененные, никогда не обратятся к шине. Не будет никакого "пинг-понга" со строками кэшей, обычно получающегося при попытке нескольких потоков использовать одну и ту же область памяти.
8.2.5. О чем еще стоит сказать
В разделе 6.4.2 мы уже обсудили, как можно использовать префикс lock (доступен на x86 и x86-64) во избежание применения атомарных операций в некоторых случаях. Однако, предложенные приемы не работают в случае множества потоков, которые при этом не борются за одну и ту же область памяти. В таком случае применение атомарных операций не обязательно. А с транзакционной памятью проблема исчезает сама собой. Ресурсоемкие запросы RFO выполняются только когда разные процессоры обращаются к одной и той же области одновременно, либо сразу друг за другом. Только тогда они и используются. Как-то еще оптимизировать выполнение уже практически невозможно.
Внимательный читатель наверняка уже задался вопросом, как же быть с задержками. Давайте представим, что может произойти в самом худшем случае? Что, если поток с активной транзакцией внезапно выходит из очереди, либо получает сигнал и, возможно, завершается, либо решает использовать siglongjmp для перехода в другое состояние? Ответ один: транзакция будет отменена. Ее можно отменить в любой момент: и когда поток выполняет системный вызов, и когда он получает сигнал (т.е. происходит смена уровня кольца). Так же может оказаться, что отмена транзакции - часть работы операционной системы при обработке системных вызовов или сигналов. Как бы то ни было, нам придется подождать, чтобы увидеть, как это всё будет реализовано на деле.
Но и прямо сейчас есть над чем поразмыслить. Рассмотрим последний в этом разделе нюанс относительно транзакционной памяти. Кэш транзакций, как и другие кэши, работает с кэш-строками. Поскольку он представляет собой эксклюзивный кэш, то одновременное использование одной и той же строки транзакциями и нетранзакционной операцией затруднительно. Следовательно, важно
- убирать данные, не используемые транзакцией, из кэш-строки
- данные разных транзакций хранить в разных строках кэша
Первый подход далеко не нов - сегодня он окупает себя сполна и при использовании атомарных операций. Со вторым сложнее: в наше время объекты почти никогда не выравниваются по строкам кэша в связи с высокой стоимостью. Если используемые данные, а с ними и слова, измененные с помощью атомарных операций, хранить в одной кэш-строке, то этим уменьшается количество затраченных строк. Это не относится к взаимным исключениям (где мьютекс всегда привязан к отдельной строке кэша), но в остальных случаях вполне реально расположить данные атомарных операций вместе с другими данными. В случае же транзакционной памяти, такое применение строки кэша для двух целей разом, скорее всего окажется фатальным. Любая обычная попытка доступа к данным {К данным рассматриваемой строки, конечно же. Доступ к другим случайным строкам не влияет на ход выполнения транзакции.} приведет к удалению кэш-строки из кэша транзакций, отменяя тем самым выполняемую транзакцию. Выравнивание объектов по строкам кэша в будущем станет вопросом не только производительности, но также корректности и точности.
Хотя возможно, транзакционная память будет по умолчанию реализована с более точным учетом данных, и в результате мы избежим проблем с обычным доступом к информации, находящейся в строках кэша, используемых транзакциями. Вот только такая реализация потребует гораздо больше усилий, поскольку тогда информации протокола MESI уже будет недостаточно.
8.3. Увеличение латентности
Относительно дальнейшего развития технологий памяти можно быть уверенным в одном: латентность продолжит расти. В разделе 2.2.4 мы уже говорили о том, что задержки памяти DDR3 будут превышать таковые у DDR2. Память FB-DRAM также имеет теоретически более высокие задержки, особенно при последовательном подключении модулей. Ведь проход по всем модулям запросов и ответов на них чего-то, да стоит.
Второй источник задержек - всё более широкое распространение NUMA. AMD Opteron в версии с несколькими ядрами (процессорами) как раз представляет собой систему NUMA. ЦПУ имеют свою локальную память с собственным контроллером, но к остальной части памяти доступ на материнских платах SMP осуществляется через шину HyperTransport. Технология Intel CSI будет использовать почти тот же принцип. В связи с ограничениями пропускной способности на каждый процессор и требованием (к примеру) постоянного использования множества 10-гигабитных Ethernet-портов, многосокетовые материнские платы никуда не исчезнут, даже учитывая увеличение числа ядер на каждом сокете.
Третий источник задержек - сопроцессоры. Мы думали, что избавились от них в начале 1990-х, когда исчезла необходимость в математических сопроцессорах на ЦП потребительского уровня, но теперь они возвращаются. Intel Geneseo и AMD Torrenza - расширения платформ, позволяющие сторонним разработчикам оборудования интегрировать свои продукты в материнские платы. То есть выходит, что сопроцессоры будут размещаться не на PCIe платах, а гораздо ближе к ЦПУ. Благодаря чему увеличится доступная им пропускная способность.
В IBM пошли по другому пути (хотя расширения по типу Intel и AMD всё ещё возможны) с процессором Cell. Данный процессор состоит, помимо ядра PowerPC, из восьми синергических вычислительных элементов (Synergistic Processing Units, SPU), которые по сути являются специализированными процессорами для (по большей части) вычислений с плавающей запятой.
Сопроцессоры и SPU объединяет то, что в них, скорее всего, будет использоваться еще более медленный набор логики памяти, чем в современных реальных процессорах. Частично это обусловлено необходимостью упрощения: все эти тонкости работы с кэшем, предвыборка и прочее - сложно, правда? Особенно когда в дополнение ко всему необходима поддержка когерентности кэша. Высокопроизводительные программы будут все больше полагаться на сопроцессоры, поскольку разница в производительности может быть огромна. Теоретическая пиковая производительность процессора Cell - 210 Гфлопс. Сравните с 50-60 Гфлопс для "обычного" хай-энд ЦПУ. Современные графические процессоры (Graphics Processing Units, GPU) достигают и более высоких результатов (до 500 Гфлопс), и их без особых проблем, пожалуй, можно интегрировать в системы Geneseo/Torrenza.
Все эти разработки наводят на мысль, что важность предвыборки повысится еще больше. Для сопроцессоров она станет действительно критична. Для ЦПУ, особенно с ростом числа ядер, необходимо постоянно чем-то нагружать шину FSB, вместо того чтобы накапливать кучу запросов между передачами. Для этого процессор должен иметь возможность "заглянуть" как можно дальше в будущее, что обеспечивается эффективным применением инструкций упреждающей выборки.
8.4. Векторные операции
Мультимедийные расширения современных процессоров, по сути, реализуют векторные операции в некоторой, очень ограниченной форме. Векторные инструкции характеризуются большим числом операций, выполняемых вместе. Ну, большим - если говорить о мультимедиа инструкциях и сравнивать со скалярными операциями. Это тем не менее очень и очень далеко от векторных компьютеров вроде Cray-1 или векторных блоков комплекса IBM 3090.
Для компенсации ограниченного числа операций, выполняемых за одну инструкцию (на большинстве машин это четыре операции с типом float или две с double), необходимо увеличение количества итераций внешних циклов. Пример в разделе 9.1 ясно это показывает: на каждую кэш-строку приходится по SM итераций.
Уменьшить это число можно, расширив векторные регистры и операции. Это дает нам нечто большее, чем просто улучшение декодирования инструкций и т.п.; мы сейчас более заинтересованы во влиянии на память. Если одной инструкцией можно считывать или записывать больше данных, то процессору лучше видно, как приложение использует память, и не приходится собирать информацию по кусочкам, исследуя поведение множества отдельных инструкций. Далее, полезнее становятся инструкции "сквозного" чтения или записи, т.е. которые не трогают кэш. С размером SSE регистра в 16 байт (в процессоре x86), использование "сквозного" чтения - не лучшая идея, поскольку тогда последующие запросы к той же строке будут вынуждены по новой загружать данные из памяти (в случае промахов кэша). С другой стороны, если векторные регистры будут достаточного размера для хранения одной и более строк кэша, операции сквозного чтения/записи станут не так страшны. На практике растет необходимость работать с наборами данных, не помещающимися в кэш-память.
Наличие больших векторных регистров не обязательно означает увеличение латентности, ведь векторным инструкциям не нужно ждать, пока прочитаются/запишутся все данные. Векторные процессорные блоки могут начать работу с теми данными, которые уже успели загрузиться, если получится распознать кодовую последовательность. Это значит, например, что если нужно загрузить векторный регистр и затем все элементы умножить на некое число, то процессор может начать операцию перемножения как только первая часть вектора будет загружена, не дожидаясь загрузки остальных. Всё это лишь вопрос сложности векторного блока. Рассмотренные факты показывают, что теоретически векторные регистры могут распространиться очень широко и уже сегодня программы можно разрабатывать, учитывая данную возможность. Практически же, процессоры используются в многопроцессных и многопоточных операционных системах, что накладывает ограничения на размер векторных регистров. А именно, важно время контекстного переключения, куда входит сохранение/загрузка значений регистров.
С большими регистрами возникает проблема - входные и выходные данные операций не могут находиться в памяти последовательно. Это может происходить из-за использования разреженных матриц, из-за доступа к матрицам по столбцам вместо строк, либо иных различных факторов. Векторные блоки для таких случаев имеют свои способы произвольного доступа к памяти. Инструкция векторной загрузки или сохранения может быть настроена нужным образом для обращения к различным местам адресного пространства. В современных мультимедийных инструкциях это невозможно в принципе. Значения пришлось бы явно загружать последовательно, одно за другим, и затем старательно собирать их в один векторный регистр.
Векторные блоки прошлого имели различные режимы для обеспечения типичных, наиболее используемых запросов доступа:
- используя striding, он же интервальный режим, можно указать величину промежутка между двумя соседними векторными элементами. Интервалы между всеми элементами должны быть одинаковыми, но это, к примеру, легко позволяет считать столбец матрицы в векторный регистр за одну инструкцию, а не использовать по инструкции на каждую строку.
- используя косвенную адресацию памяти, можно создавать шаблоны произвольного доступа. Инструкция чтения/записи получает указатель на массив с адресами или смещениями от адресов памяти, и по ним работает.
Сейчас еще не ясно, увидим ли мы возрождение настоящих векторных операций в процессорах будущего. Быть может, эта задача будет возложена на сопроцессоры. В любом случае, если мы получим доступ к векторным операциям, будет важно корректно организовывать код, выполняющий подобные операции. Код должен быть самодостаточным и заменяемым, с интерфейсом, позволяющим эффективно применять векторные операции. Например, интерфейсы должны обеспечивать добавление матриц целиком, вместо того чтобы ограничиваться строками, столбцами или даже группами элементов. Чем больше "строительные блоки", тем выше шанс использования векторных операций.
В [vectorops] (локально) авторы призывают к возрождению векторных операций. Они выделяют множество преимуществ и пытаются развеять некоторые мифы. Но по правде говоря, они рисуют слишком упрощенную картину. Выше упомянуто, что большие наборы регистров означают увеличение времени контекстных переключений, чего следует избегать в операционных системах общего назначения. Почитайте о проблемах процессора IA-64, возникающих при операциях, интенсивно применяющих контекстные переключения. Долгое время выполнения векторных операций также становится проблемой, если задействуются прерывания. При возникновении прерывания, процессор должен остановить текущую работу и обработать его. После этого можно возобновлять прерванную работу. А в целом, прервать выполнение инструкции где-то в середине достаточно сложно; не то чтобы совсем невозможно, но сложно. Если время выполнения инструкции велико, то в ней должна быть реализована возможность приостановки, либо перезапуска. Иначе время реагирования на прерывание станет слишком большим. Последнее - недопустимо.
Векторные блоки также не требовали жесткого выравнивания памяти, что в свою очередь оказывало влияние на разрабатываемые алгоритмы. В то время как некоторые из современных процессоров (особенно RISC) имеют строгие требования по выравниванию, в связи с чем расширение до полноценных векторных операций опять же затруднено. В общем, векторные операции потенциально имеют большие преимущества, особенно если поддерживается косвенность и интервалы, так что - надеемся и ждем появления такого функционала в будущем.
9 Приложения и библиография
9.1 Умножение матриц
Это полный текст программы-бенчмарка, используемой для умножения матриц в разделе 6.2.1. За более подробной информацией об используемых в программе особенностях отсылаем читателя к справочному руководству Intel.
#include <stdlib.h>
#include <stdio.h>
#include <emmintrin.h>
#define N 1000
double res[N][N] __attribute__ ((aligned (64)));
double mul1[N][N] __attribute__ ((aligned (64)));
double mul2[N][N] __attribute__ ((aligned (64)));
#define SM (CLS / sizeof (double))
int
main (void)
{
// ... Инициализация mul1 и mul2
int i, i2, j, j2, k, k2;
double *restrict rres;
double *restrict rmul1;
double *restrict rmul2;
for (i = 0; i < N; i += SM)
for (j = 0; j < N; j += SM)
for (k = 0; k < N; k += SM)
for (i2 = 0, rres = &res;[i][j], rmul1 = &mul1;[i][k]; i2 < SM;
++i2, rres += N, rmul1 += N)
{
_mm_prefetch (&rmul1;[8], _MM_HINT_NTA);
for (k2 = 0, rmul2 = &mul2;[k][j]; k2 < SM; ++k2, rmul2 += N)
{
__m128d m1d = _mm_load_sd (&rmul1;[k2]);
m1d = _mm_unpacklo_pd (m1d, m1d);
for (j2 = 0; j2 < SM; j2 += 2)
{
__m128d m2 = _mm_load_pd (&rmul2;[j2]);
__m128d r2 = _mm_load_pd (&rres;[j2]);
_mm_store_pd (&rres;[j2],
_mm_add_pd (_mm_mul_pd (m2, m1d), r2));
}
}
}
// ... использование результирующей матрицы
return 0;
}
Структура циклов в основном точно такая, как в последней реализации, приведенной в разделе 6.2.1. Одно большое отличие в том, что операция загрузки значения rmul1[k2] была извлечения из внутреннего цикла, поскольку мы должны создать вектор, где у обоих элементов значения одинаковы. Это делается с помощью внутренней операции _mm_unpacklo_pd().
Единственное, что еще нужно отметить, это то, что мы явно выровняли три массива для того, чтобы, как мы ожидаем, значения, находящиеся в этих массивах действительно находились в одной и той же кэш-строке.
9.2 Предсказание отладочного ветвления
Если, как было рекомендовано, использовать определения likely и unlikely из раздела 6.2.2, то легко {по крайней мере, с помощью инструментальных средств GNU} воспользоваться отладочный режимом для проверки допущений, которые должны быть действительно истинными. Определения макросов можно заменить следующим образом:
#ifndef DEBUGPRED
# define unlikely(expr) __builtin_expect (!!(expr), 0)
# define likely(expr) __builtin_expect (!!(expr), 1)
#else
asm (".section predict_data, \"aw\"; .previous\n"
".section predict_line, \"a\"; .previous\n"
".section predict_file, \"a\"; .previous");
# ifdef __x86_64__
# define debugpred__(e, E)\
({ long int _e = !!(e);\
asm volatile (".pushsection predict_data\n"\
"..predictcnt%=: .quad 0; .quad 0\n"\
".section predict_line; .quad %c1\n"\
".section predict_file; .quad %c2; .popsection\n"\
"addq $1,..predictcnt%=(,%0,8)"\
: : "r" (_e == E), "i" (__LINE__), "i" (__FILE__));\
__builtin_expect (_e, E);\
})
# elif defined __i386__
# define debugpred__(e, E)\
({ long int _e = !!(e);\
asm volatile (".pushsection predict_data\n"\
"..predictcnt%=: .long 0; .long 0\n"\
".section predict_line; .long %c1\n"\
".section predict_file; .long %c2; .popsection\n"\
"incl ..predictcnt%=(,%0,4)"\
: : "r" (_e == E), "i" (__LINE__), "i" (__FILE__));\
__builtin_expect (_e, E);\
})
# else
# error "debugpred__ definition missing"
# endif
# define unlikely(expt) debugpred__ ((expr), 0)
# define likely(expr) debugpred__ ((expr), 1)
#endif
В этих макросах используется множество функциональных возможностей, реализуемых ассемблером и компоновщиком GNU при сборке файлов ELF. Первая инструкция asm в контейнере DEBUGPRED определяет три дополнительных раздела; она, в основном, предоставляет ассемблеру сведения о том, какие должны быть созданы секции. Все секции доступны во время выполнения программы, а в секцию predict_data также можно осуществлять запись. Важно, чтобы все названия секций были допустимыми идентификаторами языка C. Причина станет понятной в ближайшее время.
Новые определения макросов likely и unlikely обращаются к машинно-спицифическому макросу debugpred__. Этот макрос выполняет следующие задачи:
- Размещает два слова в секции
predict_data, которые являются счетчиками правильных и неправильных предсказаний. Эти два поля с помощью операции%=получают уникальные имена; лидирующие точки гарантируют, что символы не попадут в таблицу символов. - Размещает одно слово в секции
predict_line, которое содержит номер строки, где используется макросlikelyилиunlikely. - Размещает одно слово в секции predict_file, которое содержит указатель на имя файла, где используется макрос
likelyилиunlikely. - Увеличивает счетчики "correct" ("правильно") или "incorrect" ("неправильно") для этого макроса в соответствии с фактическим значением выражения
e. Мы здесь не используем атомарные операции, поскольку они, в своей массе, медленнее и абсолютная точность при маловероятном случае коллизии не так важна. Если потребуется, то это достаточно легко изменить.
Псевдооперации .pushsection и .popsection описаны в руководстве по ассемблеру. Заинтересованному читателю можно предложить изучить детали этого определения при помощи подсказок и руководств, а также методом некоторых проб и ошибок.
Эти макросы автоматически и прозрачно заботятся о сборе информации о правильных и неправильных предсказаниях ветвлений. Единственное, чего не хватает, это метод, с помощью которого можно получать результаты. Простейший способ --- определить деструктор объекта и выдать в нем полученные результаты. Это можно сделать с помощью функции, определяемой следующим образом:
extern long int __start_predict_data;
extern long int __stop_predict_data;
extern long int __start_predict_line;
extern const char *__start_predict_file;
static void
__attribute__ ((destructor))
predprint(void)
{
long int *s = &__start_predict_data;
long int *e = &__stop_predict_data;
long int *sl = &__start_predict_line;
const char **sf = &__start_predict_file;
while (s < e) {
printf("%s:%ld: incorrect=%ld, correct=%ld%s\n", *sf, *sl, s[0], s[1],
s[0] > s[1] ? " <==== WARNING" : "");
++sl;
++sf;
s += 2;
}
}
Здесь начинает играть свою роль тот факт, что названия разделов являются допустимыми идентификаторами языка C; они используются компоновщиком GNU, если это потребуется, при автоматическом создании в секции двух символов. Символы __start_XYZ соответствуют началу секции XYZ, а __stop_XYZ является месторасположением первого байта, идущего за секцией XYZ. Эти символы позволяют повторять содержимое секции во время выполнения программы. Обратите внимание, что поскольку содержимое секций может зависеть от того, какие файлы использует компоновщик во время компоновки программы, у компилятора и ассемблера недостаточно информации для того, чтобы определить размер секции. Только с помощью этих магических символов, генерируемых компоновщиком, можно обеспечить повторное исполнение содержимого секции.
Но код повторно выполняется не только в этой одной секции: это происходит еще в трех секциях. Поскольку мы знаем, что для каждых двух слов, добавляемых в секцию predict_data, мы добавляем одно слово для каждой секции predict_line и predict_file, у нас нет возможности проверять границы этих двух секций. Мы просто используем указатели и увеличиваем им в унисон.
Код выводит строку для каждого предсказания, которое появляется в коде. В ней указывается, где предсказание неверно. Конечно, это можно изменить и режим отладки задать таким образом, чтобы отмечать только записи, в которых больше неверных предсказаний, чем верных. Это кандидаты на изменение. Есть частности, из-за которых происходит усложнение; например, если предсказание ветвления происходит внутри макроса, который используется в нескольких местах, тогда прежде, чем будет принято окончательное решение, следует рассмотреть совместно все макросы.
Два последних комментария: данных, необходимых для этой отладочной операции, немало и в случае, когда используются DSO, их использование ресурсоемко (месторасположение секции predict_file должно изменяться). Таким образом, при создании двоичных файлов режим отладки нужно отключать. Наконец, каждый исполняемый файл и DSO могут выдавать свои собственные выходные данные; это надо иметь в виду при анализе данных.
9.3 Измерение издержек, связанных с общим использованием кэш-строк
В этом разделе приводится тестовая программа, которая используется для измерения дополнительных затрат, связанных с использованием одной и той же кэш-строки, в сравнении с случаем, когда используются различные кэш-строк.
#include <error.h>
#include <pthread.h>
#include <stdlib.h>
#define N (atomic ? 10000000 : 500000000)
static int atomic;
static unsigned nthreads;
static unsigned disp;
static long **reads;
static pthread_barrier_t b;
static void *
tf(void *arg)
{
long *p = arg;
if (atomic)
for (int n = 0; n < N; ++n)
__sync_add_and_fetch(p, 1);
else
for (int n = 0; n < N; ++n)
{
*p += 1;
asm volatile("" : : "m" (*p));
}
return NULL;
}
int
main(int argc, char *argv[])
{
if (argc < 2)
disp = 0;
else
disp = atol(argv[1]);
if (argc < 3)
nthreads = 2;
else
nthreads = atol(argv[2]) ?: 1;
if (argc < 4)
atomic = 1;
else
atomic = atol(argv[3]);
pthread_barrier_init(&b;, NULL, nthreads);
void *p;
posix_memalign(&p;, 64, (nthreads * disp ?: 1) * sizeof(long));
long *mem = p;
pthread_t th[nthreads];
pthread_attr_t a;
pthread_attr_init(&a;);
cpu_set_t c;
for (unsigned i = 1; i < nthreads; ++i)
{
CPU_ZERO(&c;);
CPU_SET(i, &c;);
pthread_attr_setaffinity_np(&a;, sizeof(c), &c;);
mem[i * disp] = 0;
pthread_create(&th;[i], &a;, tf, &mem;[i * disp]);
}
CPU_ZERO(&c;);
CPU_SET(0, &c;);
pthread_setaffinity_np(pthread_self(), sizeof(c), &c;);
mem[0] = 0;
tf(&mem;[0]);
if ((disp == 0 && mem[0] != nthreads * N)
|| (disp != 0 && mem[0] != N))
error(1,0,"mem[0] wrong: %ld instead of %d",
mem[0], disp == 0 ? nthreads * N : N);
for (unsigned i = 1; i < nthreads; ++i)
{
pthread_join(th[i], NULL);
if (disp != 0 && mem[i * disp] != N)
error(1,0,"mem[%u] wrong: %ld instead of %d", i, mem[i * disp], N);
}
return 0;
}
Код, представляемый здесь, следует, большей частью, рассматривать в качестве иллюстрации создания программы, в которой измеряются такие эффекты, как затраты, связанные с использованием кэш-строк. Интерес представляет тело циклов в tf. Внутренняя инструкция __sync_add_and_fetch, известная компилятору, создает атомарную инструкцию добавления. Во втором цикле мы должны "употребить" результат приращения (с помощью инлайновой инструкции asm). Реальный код вместо инструкции asm не подставляется; благодаря этой инструкции компилятор не удаляет из цикла счетчик цикла.
Вторая интересная особенность в том, что программа размещает потоки на конкретных процессорах. В программе предполагается, что процессоры пронумерованы от 0 и до 3, что обычно бывает в случае, если в машине используется четыре или большее число логических процессоров. В программе можно было бы для определения числа используемых процессоров воспользоваться интерфейсами из libNUMA, но это программа-тест предназначена для широкого применения без добавления указанной зависимости. Так или иначе, это достаточно легко исправить.
10 Несколько советов по использованию oprofile
Предлагаемое ниже описание не является руководством по использованию oprofile. Есть другая документация, касающаяся данной темы. Вместо этого здесь приводится несколько общих советов о том, как анализировать программы и искать места возможных проблем. Но перед этим мы должны привести, как минимум, некоторые базовые сведения.
10.1 Базовые сведения о oprofile
Работа oprofile осуществляется в в два этапа: сбор информации и ее анализ. Сбор информации выполняется ядром; это нельзя сделать на пользовательском уровне, так как для измерений используются счетчики производительности процессора. Для этих счетчиков требуется доступ к регистрам MSR (Machine State Registers --- Регистры состояния машины), для доступа к которым, в свою очередь, требуются привилегии.
В каждом современном процессоре есть свой набор счетчиков производительности. Для некоторых вариантов архитектуры определенное подмножество счетчиков есть во всех реализациях процессоров, тогда как в других вариантах наличие счетчиков зависит от версии процессора. Из-за этого трудно дать общие рекомендации об использовании oprofile. К настоящему времени (еще) не разработаны абстракции высокого уровня, помогающие скрыть эти особенности.
Также от версии процессора зависит то, какое количество событий и в какой комбинации можно отслеживать в каждый момент времени. Это еще больше усложняет картину.
Если пользователю известны необходимые сведения о счетчиках производительности, то для выбора событий, которые должны учитываться, можно использовать программу opcontrol. Для каждого события необходимо указать "значение превышения" (количество событий, которые должны произойти, прежде чем работа процессора будет прервана для записи события), какие события будут подсчитываться на пользовательском уровне и / или в ядре, и, наконец, "маска устройства" (с ее помощью выбираются подфункции счетчика производительности).
Чтобы подсчитать циклы на процессорах x86 и x86-64, нужно выполнить следующую команду:
opcontrol --event CPU_CLK_UNHALTED:30000:0:1:1
Число 30000 является значением превышения. При определении возможностей системы и сборе данных важно выбрать разумное значение. Нельзя требовать получать данные о каждом наступлении конкретного события. Когда событий много, это может привести к остановке машины, поскольку все, что она сможет делать, это собирать данные, связанными с превышением значений для событий; вот почему нужно для oprofile задавать минимальное значение. Минимальные значения будут различными для каждого события, так как различные события имеют различную вероятность возникновения в обычном коде.
Выбор очень большого значения уменьшает разрешающую способность программы oprofile. При каждом превышении значения программа oprofile записывает адрес инструкции, которая выполняется в данный момент; для архитектур x86 и PowerPC можно, при определенных обстоятельствах, также выполнять трассировку и записывать ее результаты. {Мы надеемся, что с некоторого момента трассировка будет поддерживаться на любой архитектуре.} При низкой разрешающей способности можно не получить представительного количества значений; речь идет о вероятностностных значениях, именно поэтому программа oprofile называется вероятностным профилировщиком. Чем меньше значение превышения, тем сильнее его влияние на систему с точки зрения замедления системы, но тем выше разрешающая способность программы.
Если выполняется профилирование конкретной программы и система не используется в производственных целях, то часто будет более полезным использовать минимально возможное значение превышения. Точное значение для каждого события можно получить следующим образом
opcontrol --list-events
Если профилируемая программа взаимодействует к другим процессом, то могут возникнуть проблемы, а уменьшение скорости работы вызовет проблемы при взаимодействии. Проблемы могут также возникнуть в случае, если к процессу предъявляются некоторые требования режима реального времени, которые нельзя реализовать в случае, если процесс часто прерывается. В этом случае нужно найти золотую середину. То же самое справедливо в случае, если в течение длительных периодов времени осуществляется профилирование всей системы. Небольшое значение превышения может означать значительное замедление работы системы. В любом случае программа oprofile, как и любой другой способ профилирования, вносит неопределенность и неточность.
Профилирование можно запустить с помощью команды opcontrol --start и можно остановить с помощью команды opcontrol ---stop. Когда программа oprofile собирает данные, эти данные сначала собираются в ядре, а затем в поточном режиме перенаправляются в демон пользовательского уровня, где они декодируются и записываются в файловую систему. С помощью команды opcontrol --dump можно сделать запрос всей информации, находящейся в буфере ядра, которая будет передана на пользовательский уровень.
В собранных данных могут быть данные событиях, полученных от других счетчиков производительности. В случае, если пользователь не указал стирать сохраненные данные между отдельными запусками программы oprofile, то все значения будут сохраняться вместе. Можно накапливать данные об одних и тех же событиях, возникающих в разных ситуациях. Когда событие возникает во время других профилирующих запусков, полученные значения будут добавляться в том случае, если это то, что выбрал пользователь.
Та часть процесса сбора данных, которая работает на пользовательском уровне, выполняет демультиплексирование данных. Данные для каждого файла сохраняются отдельно. Можно даже выделять различные DSO, используемые отдельными исполняемыми файлами, и даже данные отдельных потоков. С помощью команды oparchive данные, созданные таким образом, можно заархивировать. Файл, созданный этой командой, можно транспортировать на другую машину и там можно выполнить анализ данных.
С помощью программы opreport можно создавать отчеты о результатах профилирования. С помощью программы opannotate можно увидеть, где происходят различные события: в какой инструкции и, если имеются данные, в какой строке исходного кода. В результате легче найти проблемные места. Подсчет циклов процессора укажет, где тратится большая часть времени (сюда относятся промахи кэш-памяти), тогда как подсчет неиспользуемых инструкций позволяет найти место, где находится наибольшее количество исполняемых инструкций --- они различаются существенно.
Одиночное попадание по некоторому адресу, обычно незначимо. Побочным эффектом статистического профилирования является то, что попадание может происходить и на инструкции, которые выполняются всего лишь несколько или даже только один раз. В подобном случае результаты необходимо проверять с помощью повторного сбора данных.
10.2 Как это все выглядит
Сессия oprofile может выглядеть достаточно просто:
$ opcontrol -i cachebench
$ opcontrol -e INST_RETIRED:6000:0:0:1 --start
$ ./cachebench ...
$ opcontrol -h
Обратите внимание, что эти команды, в том числе сама программа, запускаются с правами пользователя root. Запуск программы в роли пользователя root осуществляется здесь только лишь для упрощения ситуации; программа может быть запущена любым пользователем и oprofile ее обнаружит. Следующим шагом является анализ данных. С помощью программы opreport мы увидим следующее:
CPU: Core 2, speed 1596 MHz (estimated)
Counted INST_RETIRED.ANY_P events (number of instructions retired) with a unit mask of
0x00 (No unit mask) count 6000
INST_RETIRED:6000|
samples| %|
------------------
116452 100.000 cachebench
Это означает, что мы собрали целую кучу событий, и теперь можно использовать программу opannotate для того, чтобы более подробно изучить данные. Мы можем узнать, где в программе произошло наибольшее количество событий. Часть выходного потока команды opannotate --source будет выглядеть следующим образом:
:static void
:inc (struct l *l, unsigned n)
:{
: while (n-- > 0) /* inc total: 13980 11.7926 */
: {
5 0.0042 : ++l->pad[0].l;
13974 11.7875 : l = l->n;
1 8.4e-04 : asm volatile ("" :: "r" (l));
: }
:}
Это внутренняя функция теста, в которой тратится большая часть времени. Мы видим, что выборка распределена по всем трем строкам цикла. Основная причина этого в том, что выборка, когда это касается указателей на инструкции, не всегда точна на 100%. Процессор выполняет инструкции по порядку; точную последовательности выполнения, необходимую для получения правильного указателя инструкций, восстановить трудно. Самые последние версии процессоров пытаются это сделать для отдельных событий, но это, в общем, не стоит таких усилий или просто невозможно. В большинстве случаев это не имеет большого значения. Программист должен уметь даже в случае, если есть только выборка с нормальным распределением, определять, что происходит.
10.3 Запуск профилирования
Когда начинается анализ тела кода, то, несомненно, нужно начинать искать в программе те места, на которые затрачивается больше всего времени. Этот код, безусловно, должны быть оптимизирован настолько, насколько это окажется возможным. Но что происходит дальше? На что в программе излишне тратится время? На этот вопрос ответить не так просто.
Одна из проблем в этой ситуации в том, что абсолютные значения, на самом деле, ни о чем не говорят. На один циклов в программе может быть затрачена большая часть времени, и это будет нормально. Однако, возможных причин высокой загрузки процессора много. Но, обычно ситуация такова, что процессор более или менее равномерно используется во всей программе. В этом случае, абсолютные значения указывают на множество мест, из-за чего от них пользы мало.
Во многих ситуациях полезно взглянуть на отношения двух событий. Например, измерение количества ошибочных ветвлений в функции может оказаться бессмысленным в случае, если не измерено, как часто выполнялась функция. Да, абсолютное значение важно для выполнения программы. Отношение ошибочных ветвлений на один вызов более важно для качества кода функции. В руководстве по оптимизации Intel для архитектуры x86 и x86-64 [intelopt] описаны относительные значения, которые следует измерять (Приложение B.7 в упомянутом документе для событий Core 2).Ниже описываются некоторые из отношений, относящиеся к управлению памятью.
Instruction Fetch Stall |
| Отношение числа циклов, в течение которых декодер инструкций ждет новых данных из-за промахов в ITLB (буфер ассоциативной трансляции инструкций). |
ITLB Miss Rate |
| Промахи ITLB на одну инструкцию. Если этот показатель высокий, то это значит, что код распределен по очень большому количеству страниц. |
L1I Miss Rate |
| Промахи L1i на одну инструкцию. Поток выполнения команд непредсказуем или размер кода слишком большой. В первом случае может помочь отказ от косвенных переходов. В последнем случае может помочь переупорядочивание блоков или отказ от использования inline - инструкций. |
L2 Instruction Miss Rate |
| Промахи L2 кода программы на одну инструкцию. Любое значение, большее нуля, указывает на локальные проблемы с кодом, что хуже, чем промахи L1i. |
Load Rate |
| Число операций, читаемых за один цикл. Ядро Core 2 может обслуживать одну операцию загрузки. Высокий показатель означает, что выполнение связано с чтением данных из памяти. |
Store Order Block |
| Показывает, блокируется ли память из-за того, что что-то запоминалось в памяти ранее; из-за этого возникают промахи кэш-памяти. |
L1d Rate Blocking Loads |
| Загрузка из L1d блокирована из-за отсутствия ресурсов. Обычно это означает, что к L1d осуществляется слишком много параллельных обращений. |
L1d Miss Rate |
| Промахи L1d на одну инструкцию. Высокий показатель означает, что предварительная загрузка неэффективна и что кэш-память L2 используется слишком часто. |
L2 Data Miss Rate |
| Промахи L2 для данных на одну инструкцию. Если значение существенно больше нуля, то аппаратная и программная предварительные загрузки неэффективны. Процессору требуется большая (или более ранняя) помощь при использовании предварительной программной загрузки. |
L2 Demand Miss Rate |
| Промахи L2 для данных на одну инструкцию, при которых аппаратная предварительная загрузка вообще не используется. Это означает, что предварительная загрузка даже не начиналась. |
Useful NTA Prefetch Rate |
| Отношение полезной предварительной загрузки данных NTA (многократно используемых данных) к общему количеству предварительно загружаемых данных NTA. Маленькое значение означает, что большая часть данных уже находятся в кэш-памяти. Это отношение также можно вычислить для других видов предварительных загрузок. |
Late NTA Prefetch Rate |
| Отношение запросов данных, загружаемых в текущий момент с помощью предварительной загрузки, к общему числу всех предварительных загрузок данных NTA. Высокий показатель указывает, что инструкции предварительной программной загрузки выдаются слишком поздно. Это отношение также можно вычислить для других видов предварительных загрузок. |
Для всех этих показателей программа должна запускаться вместе с oprofile, причем для последней нужно указать, что дожны измеряться оба необходимых события. Это гарантирует, что значения двух счетчиков можно будет сравнивать. Прежде, чем выполнять деление, нужно убедиться, что в результате не возникнет переполнения. Самый простой способ, позволяющий избежать этого, состоит в домножении каждого из значений так, чтобы переполнение не возникало.
Эти показатели относятся сразу ко всей программе целиком - на уровне исполняемого кода / DSO и даже на функциональном уровне. Чем глубже анализировать программу, тем больше в полученном значении будет ошибочных составляющих./p>
Для понимания смысла эти показателей нужно опираться на базовые значения. Это не так просто, как может показаться. Различный программный код имеет различные характеристические значения и значения показателей, которые могут считаться плохими для одной программы и могут быть нормальными для другой программы.
11 Типы памяти
Хотя приводимые ниже сведения не являются необходимыми для эффективного программирования, может оказаться полезным ознакомиться еще с некоторыми техническими особенностями имеющихся в наличии типов памяти. В частности, здесь мы расскажем об отличиях "регистровой" и "безрегистровой" памяти, а также DRAM с ECC и DRAM без ECC.
Термины "регистровый" и "буферированный" используются как синонимы при описании типов DRAM, в которых есть еще один дополнительный компонент модуля DRAM: буфер. Все типы памяти DDR могут поставляться в регистровом или безрегистровом исполнении. В безрегистровых модулях контроллер памяти подключается непосредственно ко всем чипам, имеющимся в модуле. Схема приведена на рис.11.1.
Рис.11.1: Безрегистровый модуль DRAM
С точки зрения электроники, такая схема довольно требовательна. Контроллер памяти должен позволять работать со всеми чипами памяти (их может быть больше тех шести, которые изображены на рисунке). Если в контроллере памяти (MC) есть ограничения, либо если число модулей памяти слишком большое, то такая схема не будет идеальной.

Рис.11.2: Регистровый модуль DRAM
В буферированной (или регистровой) памяти ситуация меняется: в модуле DRAM вместо прямого подключения чипов памяти к контроллеру памяти, чипы подключаются к буферу, который затем, в свою очередь, подключается к контроллеру памяти. В результате значительно снижается сложность электрических соединений. За счет экономии соответствующего числа подключений, возрастает способность контроллера памяти управлять модулями DRAM.
В связи такими преимуществами возникает вопрос: почему не все модули DRAM буферированы? Есть несколько причин. Очевидно, что буферированные модули несколько сложнее, и, следовательно, дороже. Однако, стоимость я- это не единственный фактор. В буфере происходит некоторая задержка сигналов, идущих от чипов памяти; задержка должна быть достаточно большой с тем, чтобы гарантировать, что все сигналы, идущие от чипов памяти, попадут в буфер. В результате в модулях памяти DRAM возрастают задержки. В качестве последнего фактора здесь следует отметить, что из-за использования дополнительной электрической компоненты возрастает энергопотребление. Поскольку буфер должен работать на частоте шины, энергопотребление этого компонента может быть значительным.
Из-за других факторов, связанных с использованием модулей DDR2 и DDR3, как правило, в банке памяти нельзя иметь более двух модулей DRAM. Количество банков (до двух в общераспространенных устройствах) ограничивается количеством контактов контроллера. Большинство контроллеров памяти могут управлять четырьмя модулями DRAM и, следовательно, достаточно использовать безрегисровые модули. В серверных средах с высокими требованиями к памяти ситуация может оказаться другой.
Другой аспект некоторых серверных сред состоит в том, что в них ошибки недопустимы. Ошибки могут возникнуть из-за незначительных изменения поля внутри конденсаторов в ячейках памяти. Люди часто шутят о космической радиации, но это действительно возможно. Вместе с альфа-распадами и другими природными явлениями, они приводят к ошибкам, при которых содержимое ячейки памяти изменяется с 0 на 1 или наоборот. Чем больше используется памяти, тем выше вероятность такого события.
Если такие ошибки неприемлемы, то можно использовать DRAM с технологией ECC (Error Correction Code --- код коррекции ошибок). Коды коррекции ошибок позволяют на аппаратном уровне распознать неверное содержимое ячейки памяти и, в некоторых случаях, исправить ошибки. В прошлом ошибки распознавались с помощью проверки четности и, когда обнаруживалась одна ошибка, машину нужно было останавливать. Вместо этого при использовании ECC стало возможным исправлять небольшое количество ошибочных битов. Тем не менее, если количество ошибок слишком большое, доступ к памяти невозможно выполнить правильно, и машина, все же, останавливается. Хотя при использовании модулей DRAM это достаточно маловероятный случай, поскольку в одном модуле должно произойти несколько ошибок.
Когда мы говорим о памяти ECC, мы, на самом деле, не совсем корректны. Проверку ошибок выполняет не память, вместо нее это делает контроллер памяти. Просто в модулях DRAM вместе с реальными данными есть возможность хранить и передавать несколько дополнительных битов, которые не являются данными. Обычно в памяти ECC для каждых 8 битов данных хранится один дополнительный бит. Далее будет разъяснено, почему используются 8 битов.
При записи данных в адрес памяти, контроллер памяти перед тем, как отправлять данные и ECC в шину памяти, на лету вычисляет ECC для нового содержимого. При чтении данных берутся данные и ECC, контроллер памяти вычисляет значение ECC для данных и сравнивает это значение с ECC, полученным из модуля DRAM. Если оба кода ECC совпадут, то это значит, что все хорошо. Если они не совпадают, то контроллер памяти пытается исправить ошибку. Если такое исправление невозможно, то ошибка регистрируется в журнале и, возможно, машина останавливается.
Таблица 11.1: Соотношение ECC и битов данных
| SEC | SEC/DED | |||
|---|---|---|---|---|
| Биты данных W | Биты кода ECC E | Накладные расходы | Биты кода ECC E | Накладные расходы |
| 4 | 3 | 75.0% | 4 | 100.0% |
| 8 | 4 | 50.0% | 5 | 62.5% |
| 16 | 5 | 31.3% | 6 | 37.5% |
| 32 | 6 | 18.8% | 7 | 21.9% |
| 64 | 7 | 10.9% | 8 | 12.5% |
Для корректировки ошибок используются несколько технологий, но для DRAM ECC обычно используются коды Хэмминга. Коды Хэмминга первоначально использовались для кодирования четырех битов данных с возможностью обнаружить и исправить один измененный бит (SEC --- коррекция единичной ошибки). Механизм можно легко расширить на большее количество битов данных. Зависимость между количеством битов данных W и количество битов E, используемых для корректировки ошибок, описывается уравнением
E = ⌈log2 (W+E+1)⌉
В результате итеративного решения этого уравнения получаем значения, указанные во второй колонке таблицы 11.1. При наличии дополнительного бита мы можем выявить два измененных бита за счет использования простого бита четности. Тогда эта технология будет называться SEC/DED (Single Error Correction/Double Error Detection --- Корректировка одной ошибки/Обнаружение двух ошибок). При наличии этого дополнительного бита мы получаем значения, указанные в четвертом столбце таблицы 11.1. Накладные расходы для W=64 достаточно низкие, а числа (64, 8) кратны 8, так что это естественный выбор для ECC. В большинстве модулей каждый чип памяти составляет 8 битов и, следовательно, любая другая комбинация приведет к менее эффективному решению.
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | |
| Слово ECC | D | D | D | P | D | P | P |
| Четность P1 | D | — | D | — | D | — | P |
| Четность P2 | D | D | — | — | D | P | — |
| Четность P4 | D | D | D | P | — | — | — |
Рис.11.3: Структура матрицы генерации кодов Хемминга
Вычисление кода Хэмминга легко продемонстрировать с помощью кода, использующего W = 4 и E = 3. Мы вычисляем биты четности в стратегических местах в закодированном слове. Принцип показан на рис.11.3. В позициях битов, соответствующих степеням двойки, добавляются биты четности. В сумме четности для первого бита четности P1 учитывается каждый второй бит. В сумме четности для второго бита четности P2 учитываются биты данных 1, 3 и 4 (здесь кодируются как 3, 6 и 7). Подобным образом вычисляется P4.
Вычисление битов четности можно более изящно описать с помощью умножения матриц. Мы создаем матрицу G = [I |A], где I является диагональной матрицей из единиц, а A является матрицей генерации четности, которую можем получить из рис.11.3.

Столбцы матрицы A конструируются из битов, используемых при вычислении P1, P2 и P4. Если мы теперь представим каждый элемент входных данных в виде 4-мерного вектора d, мы можем вычислить r=d⋅G и получить 7-мерный вектор r. Это те данные, которые запоминаются в случае использования ECC DDR.
Чтобы декодировать данные, мы создаем новую матрицу H=[AT|I], где AT является транспонированной матрицей генерации четности, взятой из вычислений G. Т.е. следующее:

Результат умножения H⋅r показывает, являются ли сохраненные данные дефектными. Если данные не являются дефектными, то произведением будет 3-мерный вектор (0 0 0)T. В противном случае произведение, когда оно интерпретируется как двоичное представление числа, укажет номер столбца с измененным битом.
В качестве примера, предположим, d=(1 0 0 1). Результатом будет
r = (1 0 0 1 0 0 1)
Выполняя проверки с использованием умножения на Н, в результате получаем
Теперь предположим, у нас есть ошибка в хранимых данных и из памяти обратно читаем r' = (1 0 1 1 0 0 1). В этом случае мы получаем
Вектор не является нулевым вектором и, когда он интерпретируется как число, то s' имеет значение 5. Это номер бита, который мы изменили в r' (биты начинаем считать с 1). Контроллер памяти может исправить бит и программы не заметят, что здесь возникла проблема.
Обработка дополнительного бита для части DED лишь немного сложнее. С гораздо большими затратами можно создать коды, с помощью которых можно исправлять два измененных бита и более. Решение о том, необходимо ли это делать, принимается на основе вероятности и рисков. Некоторые производители памяти говорят, что для 256MB памяти ошибка может возникать каждые 750 часов. При удвоении объема памяти, время сокращается на 75%. При достаточном количестве памяти вероятность возникновения ошибки в течение короткого промежутка времени может оказаться существенной и потребуется использовать память ECC RAM. Временной промежуток может оказаться настолько маленьким, что использование SEC/DED становится недостаточным.
Вместо того, чтобы реализовывать еще более сложные схемы исправления ошибок, на серверных материнских платах есть возможность автоматически считывать всю память в течение заданного периода времени. Это означает, что независимо от того, действительно ли память требуется процессору, контроллер памяти читает данные и, если проверка ECC не прошла, записывает исправленные данные обратно в память. До тех пор, пока вероятность будет менее двух ошибок за промежуток времени, необходимый для чтения всего содержимого памяти и записи его обратно, коррекция ошибок с помощью SEC/DED будет вполне разумным решением.
Что касается регистровой DRAM, должен возникнуть вопрос: почему ECC DRAM не является нормой? Ответ на этот вопрос точно такой же, как и на эквивалентный вопрос о регистровой RAM: дополнительный чип памяти повышает стоимость, а вычисление четности увеличивает задержку. Безрегистровая память без ECC может быть гораздо более быстрой. Из-за схожести проблем регистровой DRAM и DRAM с ECC, обычно используют только регистровую DRAM с ECC и безрегистровую DRAM без ECC.
Есть еще один способ преодоления ошибок памяти. Некоторые производители предлагают то, что часто неправильно называется "RAID для памяти", когда данные избыточно распределены по нескольким модулям DRAM, или по крайней мере, чипам памяти. Материнские платы с поддержкой этой функции могут использовать безрегистровые модули DRAM, но увеличение трафика на шинах памяти может свести на нет разницу во времени доступа для модулей DRAM с ECC и без ECC.
12 Введение в libNUMA
Хотя большая часть информации, которая нужна программистам для оптимального планирования потоков, соответствующего распределения памяти и т. д., имеется в наличии, но получить ее крайне тяжело. Без всякого сомнения, доступ к необходимым для этого функциям можно получить с помощью имеющейся библиотеки поддержки NUMA (libnuma в пакете numactl системы RHEL/Fedora).
В ответ на это автор предложил новую библиотеку, в которой представлены все функции, необходимые для NUMA. Поскольку она позволяет работать с перекрывающейся памятью и иерархией кэш-памяти, эту библиотеку также можно применять в системах, не относящихся к NUMA, но использующих многопоточные и многоядерные процессоры - почти в каждой имеющейся в настоящее время машине.
Для того, чтобы следовать советам, предлагаемым в настоящем документе, крайне необходимы, функциональные возможности этой новой библиотеки. Это единственная причина, почему она здесь упоминается. Библиотека (на момент написания статьи) еще не закончена, отсутствует подробное ее писание, она не доведена до хорошего общего состояния и еще (широко) не распространяется. В будущем она может существенно измениться. В настоящее время она доступна по ссылке http://people.redhat.com/drepper/libNUMA.tar.bz2.
Интерфейсы этой библиотеки в значительной степени зависят от информации, экспортируемой файловой системой /sys. Если файловая система не смонтирована, многие функции просто не будут работать, либо они будут предоставлять неточную информацию. Это, в частности, важно помнить в случае, если процесс выполняется в изолированной среде chroot.
В настоящее время интерфейсный заголовок библиотеки содержит следующие определения:
typedef memnode_set_t;
#define MEMNODE_ZERO_S(setsize, memnodesetp)
#define MEMNODE_SET_S(node, setsize, memnodesetp)
#define MEMNODE_CLR_S(node, setsize, memnodesetp)
#define MEMNODE_ISSET_S(node, setsize, memnodesetp)
#define MEMNODE_COUNT_S(setsize, memnodesetp)
#define MEMNODE_EQUAL_S(setsize, memnodesetp1, memnodesetp2)
#define MEMNODE_AND_S(setsize, destset, srcset1, srcset2)
#define MEMNODE_OR_S(setsize, destset, srcset1, srcset2)
#define MEMNODE_XOR_S(setsize, destset, srcset1, srcset2)
#define MEMNODE_ALLOC_SIZE(count)
#define MEMNODE_ALLOC(count)
#define MEMNODE_FREE(memnodeset)
int NUMA_cpu_system_count(void);
int NUMA_cpu_system_mask(size_t destsize, cpu_set_t *dest);
int NUMA_cpu_self_count(void);
int NUMA_cpu_self_mask(size_t destsize, cpu_set_t *dest);
int NUMA_cpu_self_current_idx(void);
int NUMA_cpu_self_current_mask(size_t destsize, cpu_set_t *dest);
ssize_t NUMA_cpu_level_mask(size_t destsize, cpu_set_t *dest,
size_t srcsize, const cpu_set_t *src,
unsigned int level);
int NUMA_memnode_system_count(void);
int NUMA_memnode_system_mask(size_t destsize, memnode_set_t *dest);
int NUMA_memnode_self_mask(size_t destsize, memnode_set_t *dest);
int NUMA_memnode_self_current_idx(void);
int NUMA_memnode_self_current_mask(size_t destsize, memnode_set_t *dest);
int NUMA_cpu_to_memnode(size_t cpusetsize, const cpu_set_t *cpuset,
size_t __memnodesize, memnode_set_t *memnodeset);
int NUMA_memnode_to_cpu(size_t memnodesize, const memnode_set_t *memnodeset,
size_t cpusetsize, cpu_set_t *cpuset);
int NUMA_mem_get_node_idx(void *addr);
int NUMA_mem_get_node_mask(void *addr, size_t size,
size_t destsize, memnode_set_t *dest);
Макросы MEMNODE_* похожи по форме и функциональным возможностям на макросы CPU_*, которые приведены в разделе 6.4.3. Есть макросы, в которых нет вариантов _S; для них всех требуется параметр, указывающий размер. Тип memnode_set_t эквивалентен типу cpu_set_t, но на этот раз это узлы памяти. Заметим, что число узлов памяти может не иметь ничего общего с числом процессоров, и наоборот. В каждом узле памяти может быть много процессоров, либо процессоров может вообще не быть. Поэтому размер битовых наборов динамически выделяемых узлов памяти не должен определяться числом процессоров.
Вместо этого необходимо воспользоваться интерфейсом NUMA_memnode_system_count. Он возвращает количество узлов, зарегистрированных в настоящее время. С течением времени это число может увеличиваться или уменьшаться. Однако чаще всего оно будет оставаться постоянным и, следовательно, интерфейс хорошо использовать для определения размеров битовых наборов узла памяти. Распределение памяти, осуществляемое макросами MEMNODE_ALLOC_SIZE, MEMNODE_ALLOC и MEMNODE_FREE, опять же похоже на то, что делают макросы CPU_.
В качестве последней параллели с макросами CPU_* библиотека также предоставляет макросы, позволяющие сравнивать битовые наборы узла памяти и выполнять с ними логические операции.
Функции NUMA_cpu_* позволяют работать с наборами процессоров. В частности, интерфейсы лишь делают существующие функциональные возможности доступными под новым именем. NUMA_cpu_system_count возвращает количество процессоров в системе, вариант NUMA_CPU_system_mask возвращает битовую маску с соответствующим битовым набором --- функцию, к которой иначе добраться невозможно.
NUMA_cpu_self_count и NUMA_cpu_self_mask возвращают информацию о процессорах, на которых может работать текущий поток. NUMA_cpu_self_current_idx возвращает индекс процессора, используемого в настоящее время. Эта информация в момент, когда возвращается, может быть уже устаревшей из-за решений, касающихся планирования, которые могут быть приняты в ядре; нужно всегда учитывать, что она может быть неточной. NUMA_cpu_self_current_mask возвращает ту же самую информацию и устанавливает соответствующий бит в битовом наборе.
Интерфейс NUMA_memnode_system_count уже был описан. NUMA_memnode_system_mask является эквивалентом функции, которая заполняет битовый набор. NUMA_memnode_self_mask заполняет битовый набор в соответствие с тем, какие узлы памяти могут подключаться к процессорам, на которых в текущий момент работает поток.
Еще более специализированной информацию возвращают функции NUMA_memnode_self_current_idx и NUMA_memnode_self_current_mask. Возвращаемой информацией является узел памяти, подключенный к процессору, на котором в текущий момент работает поток. Точно также, как и для функций NUMA_cpu_self_current_*, когда эта информация возвращается, она может быть уже устаревшей; ее можно использовать только во вспомогательных целях.
Функцию NUMA_cpu_to_memnode можно использовать для отображения множества процессоров в набор непосредственно подключенных узлов памяти. Если в наборе процессоров установлен только один бит, можно определить, какой узел памяти принадлежит какому процессору. В настоящее время в Linux не поддерживаются варианты, когда одному процессору принадлежит более одного узла памяти; в будущем это, теоретически, может измениться. Чтобы получить отображение в другом направлении, можно воспользоваться функцией NUMA_memnode_to_cpu.
Если память уже распределена, то иногда полезно знать, где память размещена. Это то, что программист может определить с помощью функций NUMA_mem_get_node_idx и NUMA_mem_get_node_mask. Первая функция возвращает индекс узла памяти, на котором размещена страница, соответствующая адресу, указанному в качестве параметра, или, если память под страницу еще не выделена, будет размещена в соответствие с установленной политикой. Вторая функция может выполнять работу для целого диапазона адресов; она возвращает информацию в виде битового набора. Значение, возвращаемое функцией, указывает число используемых узлов памяти.
В оставшейся части настоящего раздела мы рассмотрим несколько примеров использования этих интерфейсов. Во всех случаях мы пропускаем обработку ошибок и не рассматриваем случай, когда количество процессоров и/или узлов памяти слишком велико для типов cpu_set_t и memnode_set_t, соотвественно. Создание надежного кода мы оставим в качестве упражнения для читателя.
12.1 Поиск потоков, принадлежащих данному процессору (потоков-братьев)
Чтобы спланировать вспомогательные потоки, или иные потоки, которые получат выигрыш, если их выполнение будет запланировано на данном процессоре, можно воспользоваться кодом, аналогичным следующему.
cpu_set_t cur;
CPU_ZERO(&cur;);
CPU_SET(cpunr, &cur;);
cpu_set_t hyperths;
NUMA_cpu_level_mask(sizeof(hyperths), &hyperths;, sizeof(cur), &cur;, 1);
CPU_CLR(cpunr, &hyperths;);
Сначала код с помощью cpunr создает для указанного процессора битовый набор. Зтаем этот набор передаются в NUMA_cpu_level_mask вместе с пятым параметр, указывающий, что мы ищем гиперпотоки. Результат возвращается в битовом наборе hyperths. Все, что остается сделать, это очистить бит соответствующий исходному процессору.
12.2 Поиск ядер, принадлежащих данному процессору (ядер-братьев)
Если не планируется исполнять два потока на двух гиперпотоках, но от совместного использования кэш-памяти можно получить выигрыш, то нам следует поискать другие ядра процессора. Это трюк выполняется с помощью следующей последовательности кода.
cpu_set_t cur;
CPU_ZERO(&cur;);
CPU_SET(cpunr, &cur;);
cpu_set_t hyperths;
int nhts = NUMA_cpu_level_mask(sizeof(hyperths), &hyperths;, sizeof(cur), &cur;, 1);
cpu_set_t coreths;
int ncs = NUMA_cpu_level_mask(sizeof(coreths), &coreths;, sizeof(cur), &cur;, 2);
CPU_XOR(&coreths;, &coreths;, &hyperths;);
ncs -= nhts;
Первая часть кода совпадает с кодом для поиска гиперпотоков. Это не случайно, поскольку мы должны отличать гиперпотоки данного процессора от гиперпотоков других ядер. Это реализовано во второй части, где снова вызывается функция NUMA_cpu_level_mask, но на этот раз с значением уровня равным 2. Все, что остается сделать, это удалить из результата все гиперпотоки данного процессора. Для отслеживания номера битового набора в соответствующих битовых наборов используются переменные nhts и ncs.
Результирующая маска может использоваться для планирования еще одного потока. Если явным образом не планируется другой поток, то решение о том, какое использовать ядро, можно возложить на ОС. В противном случае можно в цикле выполнить следующий код:
while (ncs > 0) {
size_t idx = 0;
while (! CPU_ISSET(idx, &ncs;))
++idx;
CPU_ZERO(&cur;);
CPU_SET(idx, &cur;);
nhts = NUMA_cpu_level_mask(sizeof(hyperths), &hyperths;, sizeof(cur), &cur;, 1);
CPU_XOR(&coreths;, &coreths;, hyperths);
ncs -= nhts;
... планирование потока для процессора с индексом idx ...
}
Цикл на каждой итерации по оставшимся используемым ядрам выбирает номер процессора. Затем для этого процессора вычисляются все гиперпотоки. Затем результирующий битовый набор вычитается (с помощью CPU_XOR) из битового набора имеющихся ядер. Если с помощью операции XOR не удается что-нибудь удалить, то что-то действительно неправильно. Переменная ncs обновляется, и мы готовы к следующему раунду, но не раньше, чем будут приняты решения о планировании. В конце концов, в зависимости от требований программы можно для планирования потоков использовать любое из значений idx, cur или hyperths. Для ОС часто лучше оставить столько свободы, сколько это будет возможным, и, следовательно, лучше использовать битовый набор hyperths, с тем, чтобы операционная система сама могла выбирать наилучший гиперпоток.
Библиография
[amdccnuma]
Performance guidelines for amd athlon™ 64 and amd opteron™ ccnuma multiprocessor systems. Advanced Micro Devices, 2006.
[arstechtwo]
Stokes, Jon ``Hannibal''. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM. http://arstechnica.com/paedia/r/ram_guide/ram_guide.part2-1.html, 2004.
[continuous]
Anderson, Jennifer M., Lance M. Berc, Jeffrey Dean, Sanjay Ghemawat, Monika R. Henzinger, Shun-Tak A. Leung, Richard L. Sites, Mark T. Vandevoorde, Carl A. Waldspurger and William E. Weihl. Continuous profiling: Where have all the cycles gone. Proceedings of the 16th acm symposium of operating systems principles, pages 1--14. 1997.
[dcas]
Doherty, Simon, David L. Detlefs, Lindsay Grove, Christine H. Flood, Victor Luchangco, Paul A. Martin, Mark Moir, Nir Shavit and Jr. Guy L. Steele. DCAS is not a Silver Bullet for Nonblocking Algorithm Design. Spaa '04: proceedings of the sixteenth annual acm symposium on parallelism in algorithms and architectures, pages 216--224. New York, NY, USA, 2004. ACM Press.
[ddrtwo]
Dowler, M. Introduction to DDR-2: The DDR Memory Replacement. http://www.pcstats.com/articleview.cfm?articleID=1573, 2004.
[directcacheaccess]
Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. , 2005. (локально)
[dwarves]
Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007. (локально)
[futexes]
Drepper, Ulrich. Futexes Are Tricky., 2005. http://people.redhat.com/drepper/futex.pdf. (локально) [goldberg]
Goldberg, David. What Every Computer Scientist Should Know About Floating-Point Arithmetic. ACM Computing Surveys, 23(1):5--48, 1991.
[highperfdram]
Cuppu, Vinodh, Bruce Jacob, Brian Davis and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133--1153, 2001.
[htimpact]
Margo, William, Paul Petersen and Sanjiv Shah. Hyper-Threading Technology: Impact on Compute-Intensive Workloads. Intel Technology Journal, 6(1), 2002. (локально)
[intelopt]
Intel 64 and ia-32 architectures optimization reference manual. Intel Corporation, 2007.
[lockfree]
Fober, Dominique, Yann Orlarey and Stephane Letz. Lock-Free Techiniques for Concurrent Access to Shared Objects. In GMEM, editor, Actes des journées d'informatique musicale jim2002, marseille, pages 143--150. 2002. (локально)
[micronddr]
Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003.
[mytls]
Drepper, Ulrich. ELF Handling For Thread-Local Storage. Technical report, Red Hat, Inc., 2003. (локально)
[nonselsec]
Drepper, Ulrich. Security Enhancements in Red Hat Enterprise Linux. , 2004. (локально)
[oooreorder]
McNamara, Caolán. Controlling symbol ordering. http://blogs.linux.ie/caolan/2007/04/24/controlling-symbol-ordering/, 2007.
[sramwiki]
Wikipedia. Static random access memory. https://en.wikipedia.org/wiki/Static_random-access_memory, 2006.
[transactmem]
Herlihy, Maurice and J. Eliot B. Moss. Transactional memory: Architectural support for lock-free data structures. Proceedings of 20th international symposium on computer architecture. 1993. (локально)
[vectorops]
Gebis, Joe and David Patterson. Embracing and Extending 20th-Century Instruction Set Architectures. Computer, 40(4):68--75, 2007. [article] (локально)